Когда разработчики развертывают рабочую нагрузку на платформе облачных вычислений, они часто не задумываются о базовом оборудовании, на котором работают их службы. В идеализированном образе «облака» обслуживание оборудования и физические ограничения невидимы. К сожалению, оборудование иногда нуждается в обслуживании, что может привести к простоям. Чтобы не перекладывать эти простои на наших клиентов и соответствовать обещаниям облака, Linode внедряет инструмент под названием Live Migrations.
Live Migrations — это технология, которая позволяет экземплярам Linode перемещаться между физическими машинами без прерывания обслуживания. Когда Linode перемещается с помощью Live Migrations, переход невидим для процессов этого Linode. Если оборудование хоста нуждается в обслуживании, Live Migration можно использовать для беспрепятственного переноса всех линодов этого хоста на новый хост. После завершения этой миграции физическое оборудование может быть отремонтировано, и время простоя не повлияет на наших клиентов.
Для меня разработка этой технологии стала определяющим моментом и поворотным моментом между облачными технологиями и необлачными технологиями. У меня есть слабость к технологии Live Migrations, потому что я потратил на нее больше года своей жизни. Теперь я могу поделиться этой историей со всеми вами.
Как работают живые миграции
Live Migration в Linode начинались, как и большинство новых проектов; с большим количеством исследований, серией прототипов и помощью многих коллег и менеджеров. Первым шагом вперед было изучение того, как QEMU обрабатывает Live Migration. QEMU — это технология виртуализации, используемая Linode, а Live Migrations — это функция QEMU. В результате наша команда сосредоточилась на том, чтобы внедрить эту технологию в Linode, а не изобретать ее.
Итак, как же работает технология Live Migration в том виде, в котором она реализована в QEMU? Ответ состоит из четырех шагов:
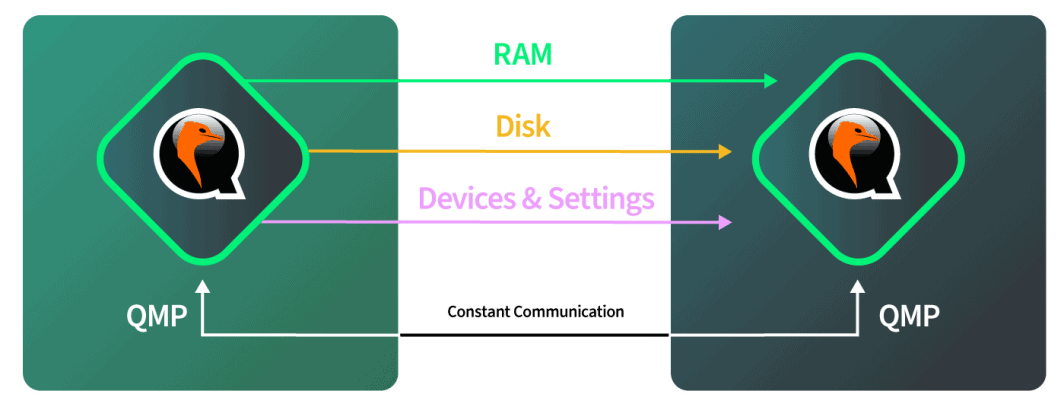
- Целевой экземпляр qemu запускается с точно такими же параметрами, которые существуют в исходном экземпляре qemu.
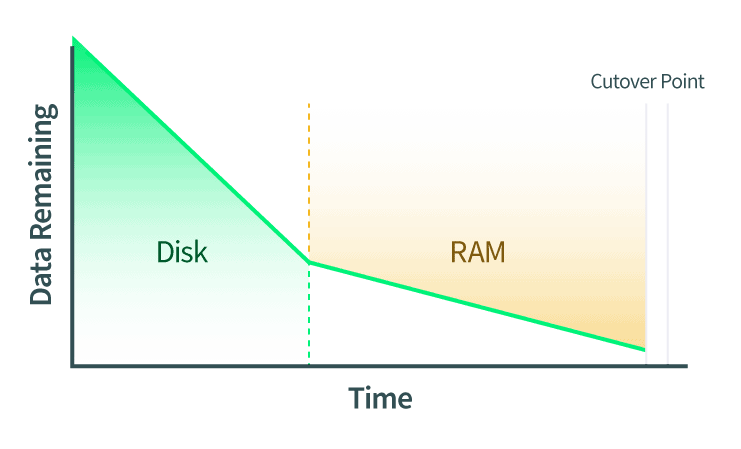
- Диски прошли Live Migration. О любых изменениях на диске также сообщается во время выполнения этой передачи.
- Оперативная память перенесена в реальном времени. Любые изменения в страницах ОЗУ также должны быть сообщены. Если на этом этапе также произойдут какие-либо изменения дисковых данных, эти изменения также будут скопированы на диск целевого экземпляра QEMU.
- Точка переключения выполнена. Когда QEMU определяет, что в ОЗУ недостаточно страниц, которые он может уверенно сократить, исходный и конечный экземпляры QEMU приостанавливаются. QEMU копирует последние несколько страниц ОЗУ и состояние машины. Состояние машины включает в себя кэш ЦП и следующую инструкцию ЦП. Затем QEMU указывает приемнику начать передачу, и приемник продолжает работу с того места, на котором остановился источник.
- Эти шаги объясняют, как выполнить динамическую миграцию с помощью QEMU на высоком уровне. Однако указание точного способа запуска целевого экземпляра QEMU — очень ручной процесс. Кроме того, каждое действие в процессе должно быть начато в нужное время.
 Как в Linode реализованы живые миграции
Как в Linode реализованы живые миграции
Посмотрев на то, что разработчики QEMU уже создали, как мы можем использовать это в Linode? Ответ на этот вопрос заключается в том, где была основная часть работы для нашей команды.
В соответствии с шагом 1 рабочего процесса Live Migration целевой экземпляр QEMU запускается для принятия входящего Live Migration. При реализации этого шага первой мыслью было взять профиль конфигурации текущего Linode и запустить его на целевой машине. Теоретически это было бы просто, но если подумать об этом, то можно обнаружить более сложные сценарии. В частности, профиль конфигурации сообщает вам, как загрузился Linode, но он не обязательно описывает полное состояние Linode после загрузки. Например, пользователь мог подключить устройство блочного хранения, подключив его к Linode после его загрузки, и это не будет задокументировано в профиле конфигурации.
Чтобы создать экземпляр QEMU на целевом хосте, необходимо было получить профиль работающего в данный момент экземпляра QEMU. Мы профилировали этот запущенный в данный момент экземпляр QEMU, проверив интерфейс QMP. Этот интерфейс дает нам информацию о том, как устроен экземпляр QEMU. Он не предоставляет информацию о том, что происходит внутри экземпляра с точки зрения гостя. Он сообщает нам, куда подключаются диски и в какой виртуализированный слот PCI подключаются виртуальные диски, как для локального SSD, так и для блочного хранилища. После запроса QMP и проверки экземпляра QEMU создается профиль, точно описывающий, как воспроизвести эту машину в месте назначения.
На целевой машине мы получаем полное описание того, как выглядит исходный экземпляр. Затем мы можем точно воссоздать экземпляр здесь, с одним отличием. Разница в том, что целевой экземпляр QEMU загружается с опцией, которая указывает QEMU принять входящую миграцию.
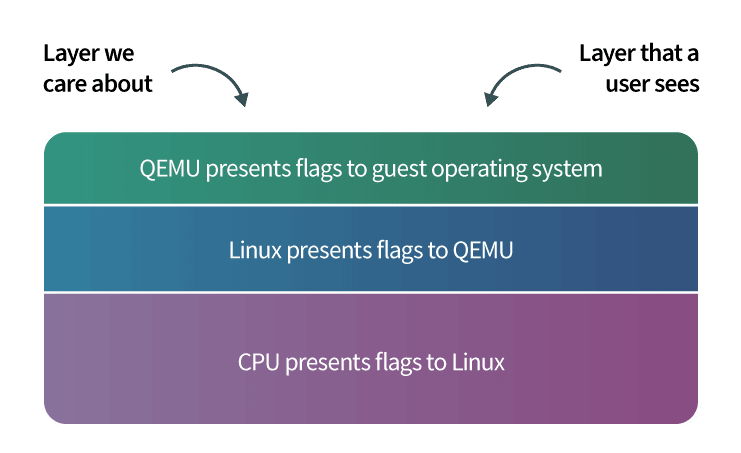
На этом этапе мы должны сделать перерыв в документировании Live Migration и переключиться на объяснение того, как QEMU достигает этих целей. Дерево процессов QEMU состоит из управляющего процесса и нескольких рабочих процессов. Один из рабочих процессов отвечает за такие вещи, как возврат вызовов QMP или обработка Live Migration. Другие процессы сопоставляются один к одному с гостевыми процессорами. Среда гостя изолирована от этой стороны QEMU и ведет себя как отдельная независимая система.
В этом смысле мы работаем с тремя слоями:
- Уровень 1 — это наш уровень управления;
- Уровень 2 — это часть процесса QEMU, которая обрабатывает все эти действия за нас; а также
- Уровень 3 — это фактический гостевой уровень, с которым взаимодействуют пользователи Linode.
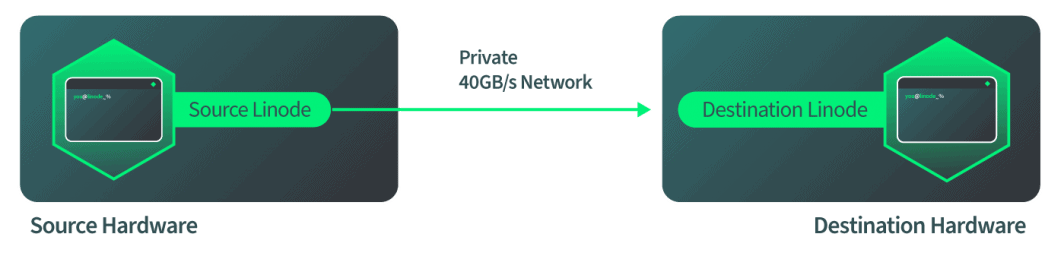
После того, как место назначения загружено и готово принять входящую миграцию, целевое оборудование сообщает исходному оборудованию, что источник должен начать отправку данных. Источник запускается, как только он получает этот сигнал, и мы сообщаем QEMU в программном обеспечении, чтобы начать миграцию диска. Программное обеспечение автономно отслеживает ход работы с диском, чтобы проверить, когда он будет завершен. Затем программное обеспечение автоматически переключается на миграцию ОЗУ, когда диск заполнен. Затем программное обеспечение снова автономно отслеживает миграцию ОЗУ, а затем автоматически переключается в режим переключения, когда миграция ОЗУ завершена. Все это происходит в сети Linode со скоростью 40 Гбит/с, поэтому сетевая сторона работает довольно быстро.
Переход: Критическая секция
Этап перехода также известен как критический раздел динамической миграции, и понимание этого шага является наиболее важной частью понимания динамических миграций.
В точке переключения QEMU определил, что он готов к переключению и запуску на целевой машине. Исходный экземпляр QEMU дает указание обеим сторонам сделать паузу. Это означает несколько вещей:
- Время останавливается по словам гостя. Если гость использует службу синхронизации времени, такую как сетевой протокол времени (NTP), то NTP автоматически повторно синхронизирует время после завершения динамической миграции. Это связано с тем, что системные часы будут отставать на несколько секунд.
- Сетевые запросы прекращаются. Если эти сетевые запросы основаны на TCP, например, SSH или HTTP, потери подключения не будет. Если эти сетевые запросы основаны на UDP, например, потоковое видео в реальном времени, это может привести к потере нескольких кадров.
Поскольку время и сетевые запросы останавливаются, мы хотим, чтобы переключение произошло как можно быстрее. Тем не менее, есть несколько вещей, которые нам нужно проверить в первую очередь, чтобы убедиться, что переход прошел успешно:
- Убедитесь, что динамическая миграция прошла без ошибок. Если была ошибка, откатываемся, останавливаем исходный линод и дальше не идем. В частности, для решения этого вопроса во время разработки потребовалось много проб и ошибок, и это было источником большой боли, но наша команда наконец добралась до сути.
- Убедитесь, что сеть будет отключена в источнике и правильно запущена в пункте назначения.
- Пусть остальная часть нашей инфраструктуры точно знает, на какой физической машине сейчас находится этот Linode.
- Поскольку для переключения есть ограничение по времени, мы хотим завершить эти шаги как можно быстрее. После того, как эти моменты будут решены, мы завершаем переход. Исходный линод автоматически получает завершенный сигнал и сообщает приемнику начать. Пункт назначения Линод продолжает с того места, где остановился. Все оставшиеся элементы в источнике и месте назначения очищаются. Если в какой-то момент в будущем целевой Linode потребуется снова выполнить динамическую миграцию, процесс можно повторить.
Обзор пограничных случаев
Большую часть этого процесса было легко реализовать, но разработка Live Migration была дополнена крайними случаями. Большая заслуга в завершении этого проекта принадлежит управленческой команде, которая увидела видение готового инструмента и выделила ресурсы для выполнения задачи, а также сотрудникам, которые довели проект до конца.
Вот некоторые из областей, где встречались пограничные случаи:
- Необходимо было создать внутренний инструментарий для организации Live Migration для групп поддержки клиентов и эксплуатации оборудования Linode. Это было похоже на другие существующие инструменты, которые у нас были и которые мы использовали в то время, но настолько отличались, что для его создания потребовались большие усилия по разработке:
- Этот инструмент должен автоматически просматривать весь парк оборудования в центре обработки данных и выяснять, какой хост должен быть местом назначения для каждого линода Live Migrated. Соответствующие характеристики при выборе этого варианта включают доступное пространство для хранения SSD и распределение оперативной памяти.
- Физический процессор конечной машины должен быть совместим с входящим Linode. В частности, ЦП может иметь функции (также называемые флагами ЦП), которые может использовать пользовательское программное обеспечение. Например, одной из таких функций является aes, которая обеспечивает шифрование с аппаратным ускорением. ЦП места назначения для динамической миграции должен поддерживать флаги ЦП исходного компьютера. Это оказалось очень сложным пограничным случаем, и в следующем разделе описывается решение этой проблемы.
- Изящная обработка случаев сбоев, включая вмешательство конечного пользователя или потерю сети во время динамической миграции. Эти случаи сбоев перечислены более подробно в следующем разделе этого поста.
Идти в ногу с изменениями в платформе Linode, что является непрерывным процессом. Для каждой функции, которую мы поддерживаем на Linodes сейчас и в будущем, мы должны убедиться, что эта функция совместима с Live Migrations. Эта задача описана в конце этого поста.
Флаги ЦП
В QEMU есть разные варианты представления процессора гостевой операционной системе. Один из этих вариантов — передать номер модели и функции центрального ЦП (также называемые флагами ЦП) непосредственно гостю. Выбрав эту опцию, гость может использовать всю необремененную мощность, которую позволяет система виртуализации KVM. Когда KVM впервые был принят Linode (что предшествовало Live Migrations), этот параметр был выбран, чтобы максимизировать производительность. Однако позже это решение вызвало множество проблем во время разработки Live Migrations.
В тестовой среде для Live Migration исходный и конечный хосты были двумя идентичными машинами. В реальном мире наш парк аппаратного обеспечения не на 100% одинаков, и между машинами существуют различия, которые могут привести к появлению разных флагов ЦП. Это важно, потому что, когда программа загружается в операционную систему Linode, Linode представляет этой программе флаги ЦП, и программа загружает определенные разделы программного обеспечения в память, чтобы использовать эти флаги. Если Linode переносится в режиме реального времени на конечный компьютер, который не поддерживает эти флаги ЦП, программа аварийно завершает работу. Это может привести к сбою гостевой операционной системы и перезагрузке Linode.
Мы обнаружили три фактора, которые влияют на то, как флаги процессора машины представляются гостям:
- Существуют незначительные различия между ЦП, зависящие от того, когда ЦП был приобретен. ЦП, приобретенный в конце года, может иметь другие флаги, чем приобретенный в начале года, в зависимости от того, когда производители ЦП выпускают новое оборудование. Linode постоянно покупает новое оборудование для увеличения мощности, и даже если модель ЦП для двух разных аппаратных заказов одинакова, флаги ЦП могут различаться.
- Разные ядра Linux могут передавать в QEMU разные флаги. В частности, ядро Linux для исходного компьютера Live Migration может передавать в QEMU флаги, отличные от флагов ядра Linux на целевом компьютере. Обновление ядра Linux на исходном компьютере требует перезагрузки, поэтому это несоответствие нельзя устранить путем обновления ядра перед выполнением динамической миграции, поскольку это приведет к простою линодов на этом компьютере.
- Точно так же разные версии QEMU могут влиять на то, какие флаги ЦП будут представлены. Обновление QEMU также требует перезагрузки машины.
Таким образом, Live Migration необходимо было реализовать таким образом, чтобы предотвратить сбои программы из-за несоответствия флагов CPU. Доступны два варианта:
Мы могли бы сказать QEMU эмулировать флаги процессора. Это привело бы к тому, что программное обеспечение, которое раньше работало быстро, теперь работает медленно, и нет возможности выяснить, почему.
Мы можем собрать список флагов ЦП в источнике и убедиться, что в пункте назначения установлены те же флаги, прежде чем продолжить. Это сложнее, но зато сохранит скорость программ наших пользователей. Это вариант, который мы реализовали для Live Migration.
После того, как мы решили сопоставить флаги исходного и целевого ЦП, мы выполнили эту задачу с помощью подхода ремня и подтяжек, который состоял из двух разных методов:
- Первый способ более простой из двух. Все флаги ЦП отправляются от источника к целевому оборудованию. Когда целевое оборудование настраивает новый экземпляр qemu, оно проверяет, установлены ли как минимум все флаги, которые присутствовали на исходном Linode. Если они не совпадают, динамическая миграция не выполняется.
- Второй метод намного сложнее, но он может предотвратить неудачные миграции, возникающие в результате несоответствия флагов ЦП. Перед запуском Live Migration мы создаем список оборудования с совместимыми флагами ЦП. Затем из этого списка выбирается целевая машина.
- Второй метод нужно выполнять быстро, и он очень сложен. В некоторых случаях нам нужно проверить до 226 флагов ЦП на более чем 900 машинах. Написать все эти 226 проверок флагов ЦП было бы очень сложно, и их нужно было бы поддерживать. В конечном итоге эта проблема была решена благодаря удивительной идее, предложенной основателем Linode Крисом Акером.
Основная идея заключалась в том, чтобы составить список всех флагов процессора и представить его в виде двоичной строки. Затем можно использовать побитовую операцию и для сравнения строк. Чтобы продемонстрировать этот алгоритм, я начну со следующего простого примера. Рассмотрим этот код Python, который сравнивает два числа, используя побитовое и:
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1
Чтобы понять, почему побитовая операция and дает такие результаты, полезно представить числа в двоичном формате. Давайте рассмотрим побитовую операцию и операцию для чисел 2 и 3, представленных в двоичном виде:
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010
Побитовая операция and сравнивает двоичные цифры или биты двух разных чисел. Начиная с самой правой цифры в приведенных выше числах, а затем влево:
Самые правые/первые биты 2 и 3 равны 0 и 1 соответственно. Побитовое и результат для 0 и 1 равен 0.
Второй крайний правый бит 2 и 3 равен 1 для обоих чисел. Побитовое и результат для 1 и 1 равен 1.
Все остальные биты для этих чисел равны 0, а побитовый результат для 0 и 0 равен 0.
Тогда двоичное представление полного результата будет 00000010, что равно 2.
Для Live Migration полный список флагов ЦП представлен в виде двоичной строки, где каждый бит представляет собой отдельный флаг. Если бит равен 0, то флаг отсутствует, а если бит равен 1, то флаг присутствует. Например, один бит может соответствовать флагу aes, а другой бит может соответствовать флагу mmx. Конкретные позиции этих флагов в двоичном представлении поддерживаются, документируются и используются машинами в наших центрах обработки данных.
Поддерживать это представление списка намного проще и эффективнее, чем поддерживать набор операторов if, которые гипотетически проверяли бы наличие флага процессора. Например, предположим, что всего нужно отследить и проверить 7 флагов ЦП. Эти флаги могут быть сохранены в 8-битном числе (один бит остается для будущего расширения). Пример строки может выглядеть так: 00111011, где крайний правый бит показывает, что aes включен, второй крайний правый бит показывает, что включен mmx, третий бит указывает, что другой флаг отключен, и так далее.
Как показано в следующем фрагменте кода, мы можем увидеть, какое оборудование будет поддерживать эту комбинацию флагов, и вернуть все совпадения за один цикл. Если бы мы использовали набор операторов if для вычисления этих совпадений, для достижения этого результата потребовалось бы гораздо большее количество циклов. Для примера Live Migration, когда на исходной машине присутствуют 4 флага ЦП, потребуется 203 400 циклов, чтобы найти подходящее оборудование.
Код Live Migration выполняет побитовую операцию и над строками флагов ЦП на исходном и целевом компьютерах. Если результат равен строке флага ЦП исходной машины, то целевая машина совместима. Рассмотрим этот фрагмент кода Python:
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatible
Обратите внимание, что в приведенном выше фрагменте кода пункт назначения поддерживает больше флагов, чем источник. Машины считаются совместимыми, потому что все флаги ЦП источника присутствуют в приемнике, что и гарантирует побитовая операция.
Результаты этого алгоритма используются нашими внутренними инструментами для создания списка совместимого оборудования. Этот список отображается для наших групп поддержки клиентов и специалистов по эксплуатации оборудования. Эти команды могут использовать инструменты для организации различных операций:
- Инструмент можно использовать для выбора наилучшего совместимого оборудования для данного Linode.
- Мы можем инициировать Live Migration для Linode без указания пункта назначения. Автоматически будет выбрано лучшее совместимое оборудование в том же центре обработки данных, и начнется миграция.
- Мы можем инициировать живую миграцию для всех линодов на хосте как одну задачу. Эта функция используется перед выполнением обслуживания хоста. Инструмент автоматически выберет места назначения для всех линодов и организует живую миграцию для каждого линода.
- Мы можем указать список из нескольких машин, которые нуждаются в обслуживании, и инструмент автоматически организует Live Migration для всех линодов на хостах.
Много времени уходит на то, чтобы программное обеспечение «просто работало…
Случаи отказа
Одна функция, о которой не очень часто говорят в программном обеспечении, — это изящная обработка случаев сбоя. Программное обеспечение должно «просто работать». Много времени на разработку уходит на то, чтобы программное обеспечение «просто работало», и это в значительной степени относится к Live Migrations. Много времени было потрачено на обдумывание всех способов, в которых этот инструмент не мог работать, и изящное решение этих случаев. Вот некоторые из этих сценариев и способы их решения:
Что произойдет, если клиент захочет получить доступ к функции своего Linode из Cloud Manager? Например, пользователь может перезагрузить Linode или подключить к нему том блочного хранилища.
Ответ: Клиент имеет право сделать это. Динамическая миграция прерывается и не продолжается. Это решение является подходящим, поскольку динамическая миграция может быть предпринята позже.
Что произойдет, если целевой Linode не загрузится?
Ответ. Сообщите об этом исходному оборудованию и спроектируйте внутренние инструменты для автоматического выбора другого оборудования в центре обработки данных. Кроме того, уведомите операционную группу, чтобы они могли исследовать оборудование исходного пункта назначения. Это произошло в рабочей среде и было обработано нашей реализацией Live Migrations.
Что произойдет, если вы потеряете сеть во время миграции?
Ответ. Автономно отслеживайте ход динамической миграции и, если за последнюю минуту не было никакого прогресса, отмените динамическую миграцию и сообщите об этом группе операций. Этого не происходило за пределами тестовой среды, но наша реализация подготовлена для этого сценария.
Что произойдет, если остальная часть Интернета отключится, но исходное и целевое оборудование все еще работает и обменивается данными, а исходный или целевой Linode работает нормально?
Ответ: Если динамическая миграция не находится в критической секции, остановите динамическую миграцию. Затем повторите попытку позже.
Если вы находитесь в критической секции, продолжайте динамическую миграцию. Это важно, потому что исходный линод приостановлен, а целевому линоде необходимо запуститься для возобновления работы.
Эти сценарии были смоделированы в тестовой среде, и предписанное поведение было признано наилучшим.
Идти в ногу с изменениями
После сотен тысяч успешных живых миграций иногда задают вопрос: «Когда выполняется живая миграция?» Live Migrations — это технология, использование которой со временем расширяется и которая постоянно совершенствуется, поэтому отметить завершение проекта не всегда просто. Один из способов ответить на этот вопрос — подумать, когда будет завершена основная часть работы по этому проекту. Ответ таков: для надежного, безотказного программного обеспечения работа не выполняется в течение длительного времени.
Поскольку со временем для Linodes разрабатываются новые функции, необходимо проделать работу, чтобы обеспечить совместимость этих функций с Live Migrations. При внедрении некоторых функций не требуется никаких новых разработок для Live Migrations, и нам нужно только проверить, что Live Migrations по-прежнему работает должным образом. Для других работа по обеспечению совместимости Live Migration отмечена как задача на раннем этапе разработки новых функций.
Как и все в программном обеспечении, всегда есть лучшие методы реализации, которые обнаруживаются в ходе исследований. Например, может случиться так, что более модульный подход к интеграции Live Migration потребует меньше обслуживания в долгосрочной перспективе. Или, возможно, смешивание функциональности Live Migrations с кодом более низкого уровня поможет включить его из коробки для будущих функций Linode. Наши команды рассматривают все эти варианты, и инструменты, лежащие в основе платформы Linode, — это живые существа, которые будут продолжать развиваться.