По состоянию на конец третьего квартала 2023 года Backblaze отслеживала 263 992 жестких диска (HDD) и твердотельных накопителей (SSD) в наших центрах обработки данных по всему миру. Из этого числа 4459 являются загрузочными дисками, из них 3242 — твердотельными накопителями и 1217 — жесткими дисками. Частота отказов твердотельных накопителей проанализирована в обзоре SSD Edition: 2023 Drive Stats.
В результате у нас осталось 259 533 жестких диска, на которых мы сосредоточимся в этом отчете. Мы проанализируем квартальные и за весь срок отказов накопителей данных по состоянию на конец третьего квартала 2023 года. Попутно мы поделимся своими наблюдениями и мнениями относительно представленных данных, и впервые в истории мы выявить частоту отказов дисков в разбивке по центрам обработки данных.
Уровень отказов жестких дисков в третьем квартале 2023 г.
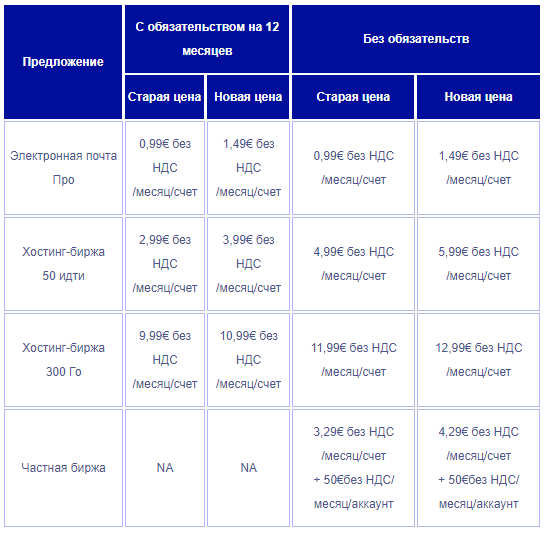
По состоянию на конец третьего квартала 2023 года мы управляли 259 533 жесткими дисками, используемыми для хранения данных. Для нашего обзора мы исключили из рассмотрения 449 накопителей, поскольку они использовались в целях тестирования или представляли собой модели накопителей, в которых не было как минимум 60 накопителей. В результате у нас осталось 259 084 жестких диска, сгруппированных по 32 различным моделям.
В таблице ниже приведена годовая частота отказов (AFR) для этих моделей накопителей за третий квартал 2023 года.
 Примечания и наблюдения по статистике за третий квартал 2023 года
Примечания и наблюдения по статистике за третий квартал 2023 года
- Диски емкостью 22 ТБ находятся здесь: Внизу списка вы увидите диски WDC емкостью 22 ТБ (модель: WUH722222ALE6L4). Backblaze Vault из 1200 дисков (плюс четыре) теперь работает. 1200 накопителей были установлены 29 сентября, поэтому в этом отчете каждый из них проработал только один день, но сбоев пока нет.
- Старики становятся смелее: на другом конце спектра срока службы находятся накопители Seagate емкостью 6 ТБ (модель: ST6000DX000) со средним сроком службы 101 месяц. В этой когорте в третьем квартале 2023 года не было сбоев при 883 дисках и сроке службы AFR 0,88%.
- Ноль сбоев: в третьем квартале шесть различных моделей накопителей не имели сбоев в течение квартала. Но только у Seagate емкостью 6 ТБ, упомянутого выше, было более 50 000 дней работы в эксплуатации, что является нашим минимальным стандартом для обеспечения достаточного количества данных, чтобы сделать AFR правдоподобным.
- Один сбой: в третьем квартале было зарегистрировано четыре модели приводов с одним сбоем.
После применения показателя 50 000 дней поездок выделились две поездки:
- WDC 16 ТБ (модель: WUH721816ALE6L0) с AFR 0,15%.
- Toshiba 14 ТБ (модель: MG07ACA14TEY) с AFR 0,63%.
Ежеквартальный показатель AFR падает
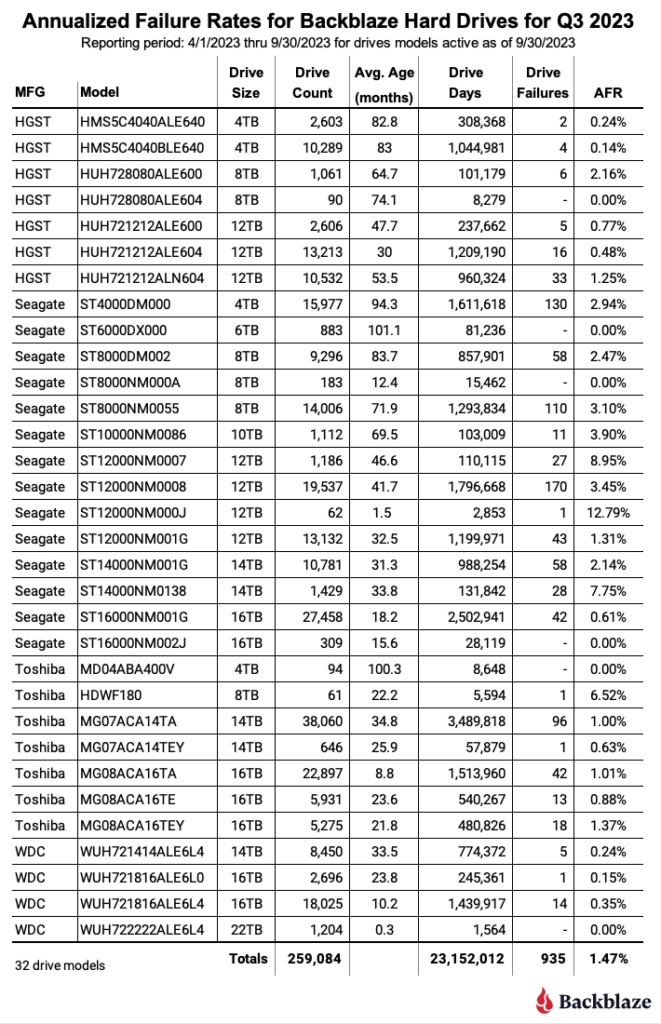
В третьем квартале 2023 года квартальный AFR для всех накопителей составил 1,47%. Это меньше, чем 2,2% во втором квартале, а также меньше, чем 1,65% год назад. Ежеквартальный AFR основан только на данных за этот квартал, поэтому он часто может колебаться от квартала к кварталу.
В нашем отчете за второй квартал 2023 года мы подозревали, что рост в 2,2% за квартал был вызван общим старением парка накопителей, и, в частности, мы указали на конкретные модели накопителей емкостью 8 ТБ, 10 ТБ и 12 ТБ как на потенциальных виновников такого роста. Этот прогноз не оправдался в третьем квартале, поскольку почти у двух третей моделей приводов показатель AFR снизился по сравнению с предыдущим кварталом по сравнению со вторым кварталом, и любое увеличение было минимальным. Сюда входили наши подозрительные модели дисков емкостью 8 ТБ, 10 ТБ и 12 ТБ.
Кажется, что второй квартал был аномалией, но в третьем квартале было одно большое отличие: мы вывели из эксплуатации 4585 устаревших дисков емкостью 4 ТБ. Средний возраст вышедших из эксплуатации накопителей составлял чуть более восьми лет, и хотя это было хорошее начало, осталось еще 28 963 накопителя емкостью 4 ТБ. Чтобы облегчить непрерывный вывод из эксплуатации устаревших дисков и сделать процесс миграции данных простым и безопасным, мы используем CVT, наше замечательное собственное программное обеспечение для миграции данных, о котором мы расскажем в другой раз.
Жаркое лето и данные статистики езды
Как и любой другой человек в нашем бизнесе, Backblaze постоянно контролирует наши системы и диски. Поэтому для нас не стало большим сюрпризом, когда ребята из НАСА подтвердили, что лето 2023 года станет самым жарким за всю историю наблюдений на Земле. Последствия этого рекордного лета отразились в наших системах мониторинга в виде предупреждений о температуре привода. Тот или иной диск на сервере хранения может перегреваться по многим причинам: он выходит из строя; вышел из строя вентилятор в сервере хранения; другие компоненты выделяют дополнительное тепло; поток воздуха каким-то образом ограничен; и так далее. Добавьте к этому тот факт, что температура окружающей среды в центре обработки данных часто повышается в летние месяцы, и вы можете получать больше предупреждений о температуре.
Просматривая данные о температуре наших накопителей в третьем квартале, мы заметили, что у небольшого количества накопителей температура превышала максимальную температуру производителя как минимум на один день. Максимальная температура для большинства накопителей составляет 60°C, за исключением накопителей Toshiba емкостью 12 ТБ, 14 ТБ и 16 ТБ, максимальная температура которых составляет 55°C. Из 259 533 дисков с данными, находившихся в эксплуатации в третьем квартале, 354 отдельных диска (0,0013%) превысили максимальную температуру производителя. Из них только два диска вышли из строя, в результате чего по состоянию на конец третьего квартала 352 диска все еще работали.
Хотя колебания температуры являются частью работы центров обработки данных, и подобные оповещения о температуре не являются чем-то необычным, команды наших центров обработки данных изучают коренные причины, чтобы убедиться, что мы готовы к неизбежному наступлению все более жаркого лета.
Повлияют ли предупреждения о температуре на статистику вождения?
Два диска, температура которых превысила максимальную температуру и вышли из строя в третьем квартале, были исключены из расчетов AFR третьего квартала. Оба диска были дисками Seagate емкостью 4 ТБ (модель: ST4000DM000). Учитывая, что оставшиеся 352 накопителя, температура которых превысила максимальную температуру, не вышли из строя в третьем квартале, мы оставили их в расчетах статистики накопителей для третьего квартала, поскольку они не увеличили вычисленную частоту отказов.
Начиная с четвертого квартала, мы удалим 352 диска из обычных расчетов AFR Drive Stats и создадим отдельную группу дисков для отслеживания, которую мы назовем Hot Drives. Это позволит нам отслеживать диски, температура которых превысила максимальную температуру, и сравнивать интенсивность их отказов с теми дисками, которые работали в соответствии со спецификациями производителя. Хотя число дисков в группе Hot Drives ограничено, это может дать нам некоторое представление о том, может ли воздействие высоких температур привести к более частому выходу диска из строя. Этот повышенный уровень мониторинга позволит выявить любое увеличение количества сбоев дисков, чтобы их можно было обнаружить и оперативно устранить.
Новые поля данных статистики поездок в третьем квартале
Во втором квартале 2023 года мы представили три новых поля данных, которые начали заполнять в публикуемых нами данных Drive Stats: vault_id, pod_id и is_legacy_format. В третьем квартале мы добавляем еще три поля в записи каждого диска следующим образом:
- центр обработки данных: центр обработки данных Backblaze, в котором установлен диск, в настоящее время одно из следующих значений: ams5, iad1, phx1, sac0 и sac2.
- Cluster_id: имя данной коллекции серверов хранения, логически сгруппированных для оптимизации производительности системы. Примечание. В настоящее время идентификатор кластера не всегда правильный, мы работаем над этим.
- pod_slot_num: физическое расположение диска на сервере хранения. Конкретный слот различается в зависимости от типа и емкости сервера хранения: Backblaze (45 дисков), Backblaze (60 дисков), Dell (26 дисков) или Supermicro (60 дисков). Мы углубимся в эти различия в другом посте.
С учетом этих дополнений новая схема, начинающаяся в третьем квартале 2023 года, будет следующей:
- дата
- серийный номер
- модель
- емкость_байтов
- отказ
- центр обработки данных (3 квартал)
- идентификатор_кластера (3-й квартал)
- vault_id (2-й квартал)
- pod_id (2-й квартал)
- pod_slot_num (3 квартал)
- is_legacy_format (2-й квартал)
- smart_1_normalized
- smart_1_raw
Остальные пары значений SMART (по данным каждой модели накопителя)
Начиная с третьего квартала, эти поля данных добавляются в общедоступные файлы статистики езды, которые мы публикуем каждый квартал.
Частота отказов по центрам обработки данных
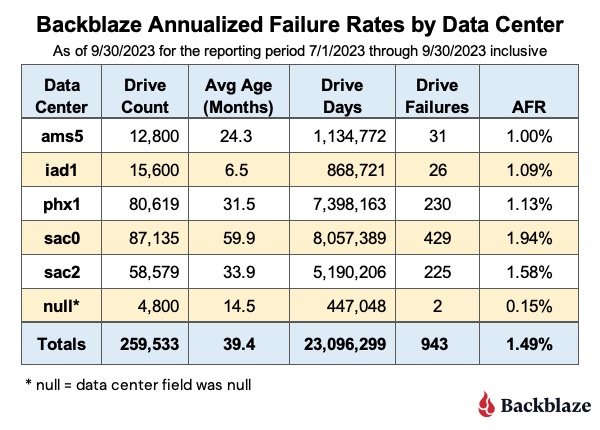
Теперь, когда у нас есть центр обработки данных для каждого диска, мы можем вычислить AFR для дисков в каждом центре обработки данных. Ниже вы найдете AFR для каждого из пяти центров обработки данных за третий квартал 2023 года.
 Примечания и наблюдения
Примечания и наблюдения
- Null?: Диски, сообщившие нулевое или пустое значение для своего центра обработки данных, сгруппированы в четыре хранилища Backblaze. Дэвид, старший инженер по инфраструктурному программному обеспечению Drive Stats, описал процесс сбора всех частей данных Drive Stats каждый день. TL:DR заключается в том, что хранилища могут быть слишком заняты, чтобы ответить в тот момент, когда мы запрашиваем, и, поскольку поле центра обработки данных является полезным для хранения данных, мы получаем пустое поле. Мы можем вернуться на день или два назад, чтобы найти значение центра обработки данных, что мы и сделаем в будущем, когда сообщим эти данные.
- sac0?: sac0 имеет самый высокий AFR среди всех центров обработки данных, но он также имеет самые старые диски — в среднем почти в два раза старше, чем следующий ближайший центр обработки данных, sac2. Как обсуждалось ранее, сбои дисков, похоже, следуют «кривой ванны», хотя в последнее время мы видели, что кривая начинается более пологой. Тем не менее, по мере старения моделей приводов они, как правило, выходят из строя чаще. Другим фактором может быть то, что sac0 и, в меньшей степени, sac2 имеют одни из самых старых модулей хранения данных, в том числе несколько модулей с 45 дисками. Мы находимся в процессе использования CVT для замены этих старых серверов при переходе с дисков емкостью 4 ТБ на диски емкостью 16 ТБ и более.
- iad1: Центр обработки данных IAD является основой нашего восточного региона и быстро растет с момента его ввода в эксплуатацию около года назад. Этот рост обусловлен сочетанием новых данных и использования клиентами наших возможностей облачной репликации для автоматического копирования своих данных в другом регионе.
- Данные за третий квартал: эта диаграмма предназначена только для данных за третий квартал и включает все диски с данными, включая те, у которых количество дисков менее 60 на модель. Отслеживая эти данные в ближайшие кварталы, мы надеемся получить некоторое представление о том, действительно ли в разных центрах обработки данных наблюдается разная частота отказов дисков, и если да, то почему.
Частота отказов жесткого диска в течение всего срока службы
По состоянию на 30 сентября 2023 г. мы отслеживали 259 084 жестких диска, используемых для хранения данных клиентов. Для анализа срока службы мы собираем количество дней работы диска и количество сбоев каждого диска, начиная с момента его ввода в эксплуатацию в одном из наших центров обработки данных. Мы группируем эти диски по моделям, а затем суммируем количество дней использования и сбоев для каждой модели за срок их службы. Этот график находится ниже.
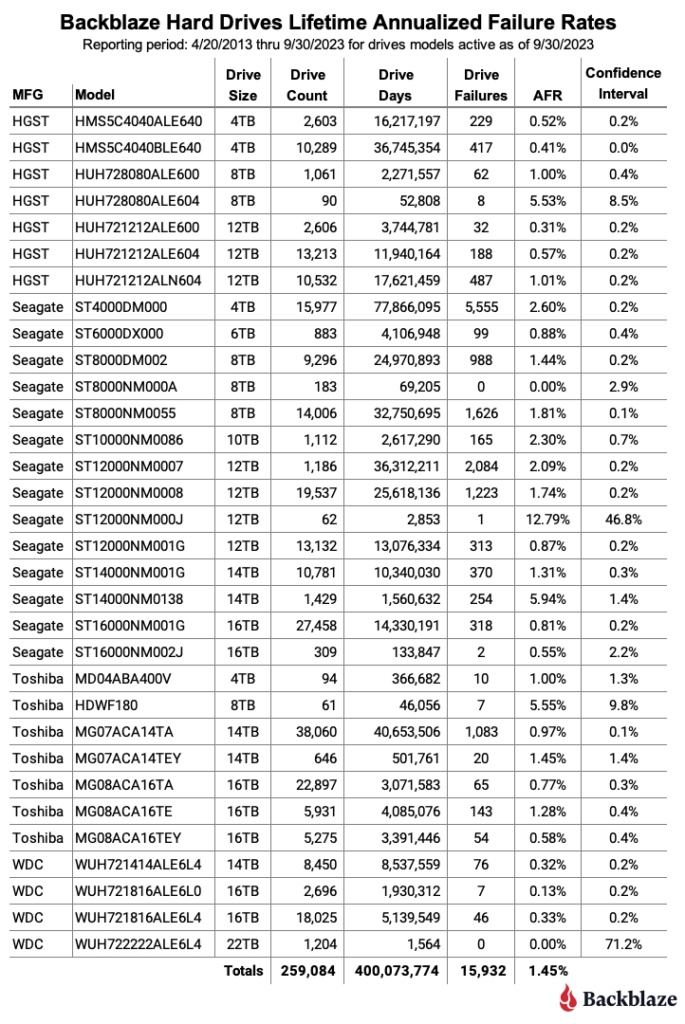
Одним из наиболее важных столбцов на этой диаграмме является доверительный интервал, который представляет собой разницу между низким и высоким уровнями достоверности AFR, рассчитанную на уровне 95%. Чем ниже значение, тем больше мы уверены в заявленном AFR. Нам нравится, чтобы доверительный интервал составлял 0,5% или меньше. Когда доверительный интервал выше, это не обязательно плохо, это просто означает, что нам либо нужно больше данных, либо данные несколько противоречивы.
В таблице ниже представлены только те модели приводов, доверительный интервал которых составляет менее 0,5%. Мы отсортировали список по размеру диска, а затем по AFR.
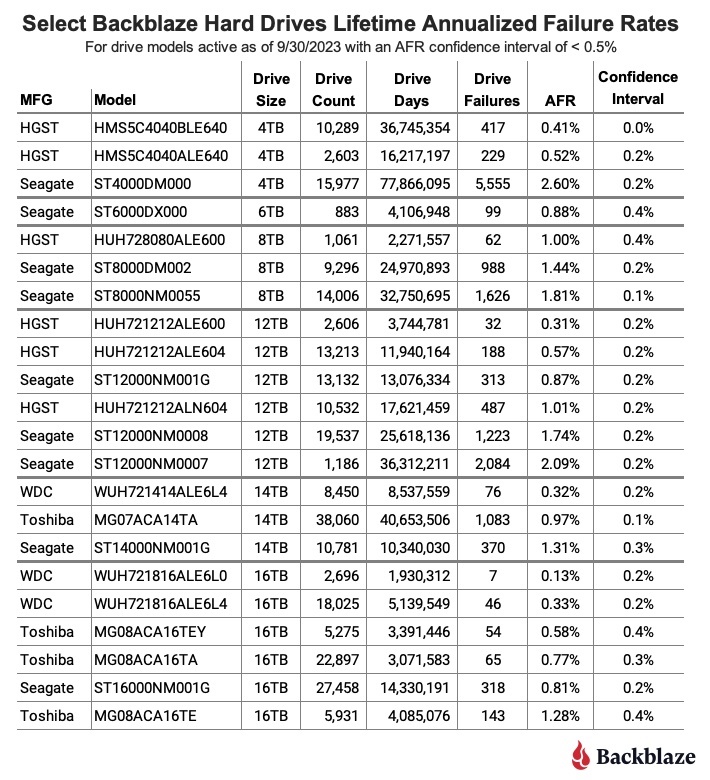
Модели накопителей емкостью 4 ТБ, 6 ТБ, 8 ТБ и некоторые модели накопителей емкостью 12 ТБ больше не производятся. В частности, модели HGST емкостью 12 ТБ все еще можно найти, но они были переименованы в Western Digital и получили альтернативные номера моделей. Изменились ли они существенно внутри, неизвестно, по крайней мере нам.
И последнее замечание относительно данных о сроке службы AFR: вы могли заметить, что AFR для всех накопителей не сильно меняется от квартала к кварталу. Последние два года он колебался между 1,39% и 1,45%. По сути, у нас много приводов с большим сроком службы, поэтому сложно переместить стрелку вверх или вниз. Хотя статистика срока службы отдельных моделей дисков может быть очень полезной, срок службы AFR для всех дисков, вероятно, будет становиться все менее и менее интересным по мере того, как мы добавляем все больше и больше дисков. Конечно, могут поступить несколько сотен тысяч никогда не выходящих из строя накопителей, поэтому мы продолжим рассчитывать и представлять срок службы AFR.