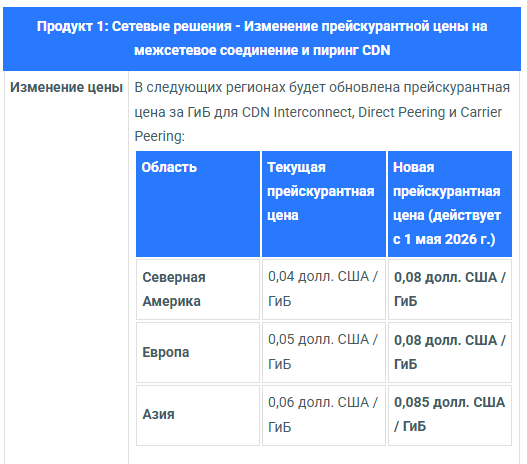
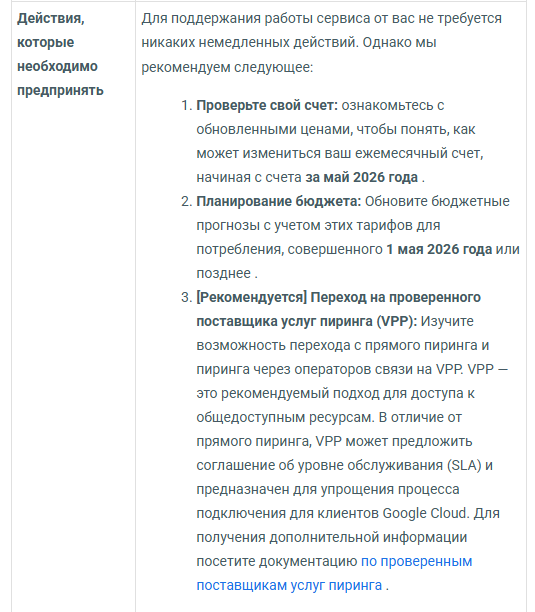
Компания провела масштабное обновление и представила новую стратегию развития, в рамках которой инфраструктурные сервисы для IT-специалистов дополняются линейкой готовых цифровых решений для предпринимателей без технической экспертизы.
Российская технологическая компания Рег.ру объявила о глобальном ребрендинге, отражающем переход от модели поставщика отдельных инфраструктурных инструментов к сервису, ориентированному на конечный результат для бизнеса. Обновление затрагивает позиционирование, продуктовую логику и подход к работе с клиентами, начиная от технических специалистов, заканчивая малым бизнесом и начинающими предпринимателями.
rebranding.reg.ru
В рамках новой стратегии Рег.ру предлагает клиентам два сценария работы. Первый сценарий предлагает использование линейки Рег.решений — сервиса простых решений «под ключ» для предпринимателей, которым требуется не просто инфраструктура, а эффективный набор инструментов для запуска и развития бизнеса, включая сайт, почту, онлайн-защиту, базовое продвижение и экспертную поддержку. Теперь владелец бизнеса может выбрать собственный сценарий работы в зависимости от задач, уровня технической экспертизы и ожидаемого результата. Второй ориентирован на разработчиков и ИТ-специалистов и сохраняет привычную модель самостоятельного выбора и настройки доменов, хостинга, облачных и серверных решений, включая инфраструктуру Рег.облака.
Сегодня рынок все заметнее уходит от модели с десятками подрядчиков и агентств к формату единого сервиса, который берет на себя решение конкретных задач бизнеса. Для малого и микробизнеса важны не отдельные инструменты, а понятный и надежный сервис для комплексного запуска и развития онлайн-проекта. Именно на этот запрос отвечает линейка Рег.решений, созданная для индивидуальных предпринимателей и небольших команд (обычно до трех человек) без крупных технических и финансовых ресурсов.
«За многие годы работы мы увидели, что значительная часть пользователей приходит за техническими продуктами, но на самом деле ожидает измеримый бизнес-результат — клиентов, продажи и дальнейшее развитие бизнеса. Ребрендинг отражает наш переход от отдельных инструментов к созданию экосистемы сервисов, которая помогает предпринимателям решать прикладные задачи, не погружаясь в технологии», — рассказывает Антон Терехов, коммерческий директор Рег.решений.
Ребрендинг затрагивает и обновление визуального стиля Рег.ру. На стартовой странице бренда появилось четкое разделение на два клиентских формата: «Сделаем вместе», объединяющий всю линейку Рег.решений, и «Сделайте сами» с классическим набором услуг — домен, хостинг, почта и другие инфраструктурные продукты. Цветовая палитра дополнилась зелеными, желтыми и лавандовыми оттенками, сменив акцент от холодной технологичности голубого цвета.
«Обновленный визуальный стиль строится вокруг идеи выбора и двух разных пользовательских путей. Мы ушли от образа исключительно технического провайдера и заложили в айдентику более сервисный и человекоцентрический подход, сохранив при этом преемственность и узнаваемость бренда, который вот уже почти 20 лет является первой точкой входа в онлайн для бизнеса», — отмечает Кирилл Шмонин, арт-директор Рег.ру.
Ребрендинг стал частью долгосрочной стратегии Рег.ру по расширению продуктового портфеля и снижению барьера входа в цифровую среду для малого бизнеса. Компания продолжает развивать инфраструктурные сервисы для профессиональной аудитории, одновременно формируя экосистему готовых решений для предпринимателей, которым важно быстро запустить проект в онлайне без привлечения внешних подрядчиков и технических навыков.