Во время саммита OVHcloud в октябре прошлого года мы объявили о недавней
регистрации 50 семейств патентов.
Эти патентные заявки, очевидно, касаются наших «аппаратных» инноваций (вы знаете, что мы производим наши серверы, стойки, системы охлаждения…), а также патентов на программное обеспечение, поскольку вопреки распространенному мнению можно запатентовать определенное программное обеспечение (при определенных условиях, но это не предмет этой статьи).

Итак, очевидно, вы удивляетесь, почему OVHcloud решила запустить эту патентную программу, когда с момента ее создания в ДНК OVHcloud был открытый код.
Это действительно очень хороший вопрос!
Цель этой статьи — объяснить, почему такая компания, как наша, не может избежать подачи патентов и почему патенты и открытые инновации не являются несовместимыми
Почему регистрация патента необходима
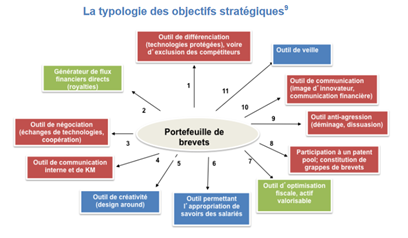
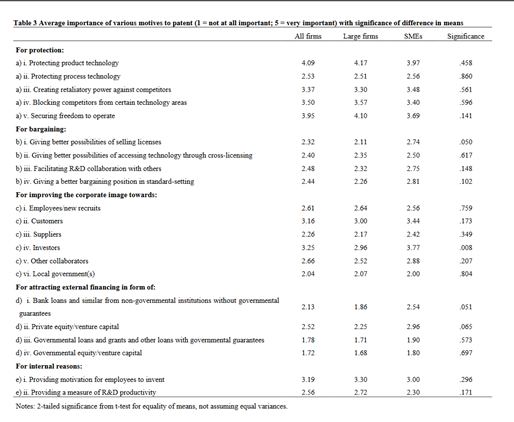
Существует множество исследований, в которых перечисляются причины, по которым компании решают подавать патенты (инструмент против агрессии, инструмент коммуникации, инструмент подбора кадров, инструмент финансовой оценки, инструмент блокирования конкуренции)
 publications.lib.chalmers.se/records/fulltext/248326/local_248326.pdf
publications.lib.chalmers.se/records/fulltext/248326/local_248326.pdf
publications.lib.chalmers.se/records/fulltext/248326/local_248326.pdf
publications.lib.chalmers.se/records/fulltext/248326/local_248326.pdf
Из всех этих причин основными являются:
Защищать себя
Есть две основные угрозы для такой компании, как наша:
- Гиганты, которые могут позволить себе подавать сотни патентов в год, чтобы атаковать любую компанию, пытающуюся конкурировать с ними
- Патентные тролли, которые являются компаниями, чей единственный бизнес заключается в том, чтобы покупать патенты и подавать в суд на компании, чтобы заставить их платить им лицензионные сборы.
Патентование является относительно дорогим, и обычно оно не является приоритетным для компаний, когда они находятся на этапе запуска.
Более того, пока они остаются маленькими, они могут надеяться не привлекать внимание крупных конкурентов или патентных троллей.
Когда мы начали расти и решили открыть филиал в США, территории по определению патентных троллей и GAFAM с тысячами патентов, мы подумали, что скрещивать пальцы в надежде на то, что нас не заметят, явно не правильная стратегия, поэтому мы засучили рукава, разработали патентную программу, соответствующую политику вознаграждений, обучили наших сотрудников интеллектуальной собственности, и мы быстро начали видеть преимущества: почти 50 заявок на патенты за 18 месяцев! И поверьте мне, это только начало!
Сохраняя нашу свободу действий
Коммерческая тайна является интересной защитой и часто предпочитается компаниями, потому что она намного дешевле, чем подача патентов (ну, похоже, она намного дешевле, но эффективное управление секретностью тоже может быть очень дорогим…)
Но следует отметить, что если бы третья сторона (даже добросовестно) подала патент на изобретение, которое в течение нескольких лет хранилось в секрете другой компанией, последняя станет фальшивомонетчиком, если продолжит использовать свое изобретение, не разочаровав ?!
Позволяет нам участвовать в патентных пулах и других сообществах открытых инноваций
Общеизвестно, что в числах есть сила!
Поэтому было естественно, что компании начали объединять усилия для инноваций.
Либо они хотят работать вместе (совместная разработка, перекрестное лицензирование ...), и в этом случае предпочтительнее подавать патенты до разработки, чтобы впоследствии можно было свободно обсуждать,
Или же они решают объединить усилия против атак патентных троллей и других агрессивных компаний и решают объединить свои патенты в качестве разменной монеты в случае нападения одного из членов группы.
Спасибо нашим сотрудникам
Поскольку мы считаем, что наша главная ценность — это наши сотрудники, и именно благодаря им мы внедряем инновации каждый день, мы создали привлекательную систему поощрений и отмечаем их всех вместе, когда их изобретение запатентовано.
Мы также создали Innovation Awards для поощрения сотрудников определенных проектов, которые не соответствуют критериям патентоспособности, но которые, тем не менее, важны для наших инноваций.
Когда патент способствует открытым инновациям
Многие недавние исследования показали, что, как это ни парадоксально, патентная система поощряет открытые инновации, стимулируя сотрудничество между компаниями в области исследований и разработок.
Технологическое партнерство
Выше мы только что видели, что это позволяет компаниям более мирно работать над совместными проектами, не опасаясь, что их предыдущие ноу-хау будут украдены.
Сегодня OVHcloud стремится расширять технологическое партнерство с другими компаниями, университетами и исследовательскими лабораториями.
Программное обеспечение и патенты с открытым исходным кодом
В программном обеспечении следует понимать, что патент и защита авторских прав не имеют одинаковой цели.
Авторское право защищает только форму (т.е. исходный код, объектный код, документацию и т.д.), В то время как патент защищает процесс, метод, независимо от используемого языка.
Две программы, производящие строго одинаковые эффекты, но с разными формами, не ущемляют друг друга с точки зрения авторского права.
Хотя патент, защищающий процесс, будет запрещать его повторное использование независимо от используемой формы.
Но зачем подавать патент, а потом давать доступ к источникам?
- Запретить сторонним организациям принимать решение о копировании функциональности программного обеспечения с открытым исходным кодом (в другой форме) и распространять его по закрытой лицензии.
- Чтобы не дать третьей стороне подать широкий патент на процесс до того, как у нас будет возможность распространить заявку в открытом коде.
- Сосредоточить усилия сообщества вокруг метода. Действительно, поскольку код открыт, все сообщество может использовать его, исправлять, оптимизировать, и, таким образом, инновации идут быстрее и дальше. Поскольку концепция остается защищенной патентом, это позволяет избежать умножения методов для одной и той же цели и рассеивания инновационных ресурсов.
«Экономика мира»
Когда Тесла разрешил использовать свои патенты без уплаты лицензионных сборов, Тесла не отказался от своих патентов, сказал Маск: «Тесла не будет возбуждать патентные иски против тех, кто добросовестно хочет использовать нашу технологию».
В то время Тесла считал, что можно добиться большего (ради спасения планеты), если сообщество будет работать над своими технологиями, а не сохранять их при себе, но патенты все еще существуют, и если компания не действует добросовестно (вероятно, Тесла нацеливается на патентных троллей), затем компания оставляет за собой право атаковать его.
Этот новый способ мышления и действия соответствует тому, что автор Тьерри Кузе называет «экономикой мира», которую он противопоставляет «экономике хищничества».
Это также то, что мы думаем в OVHcloud, и именно поэтому мы выступаем за SMART Cloud — обратимое, открытое и совместимое облако через открытые инновации.
Не волнуйтесь, OVHcloud не забыл свои ценности и намерен как можно больше участвовать в открытых инновациях и продвигать эту «экономику мира».