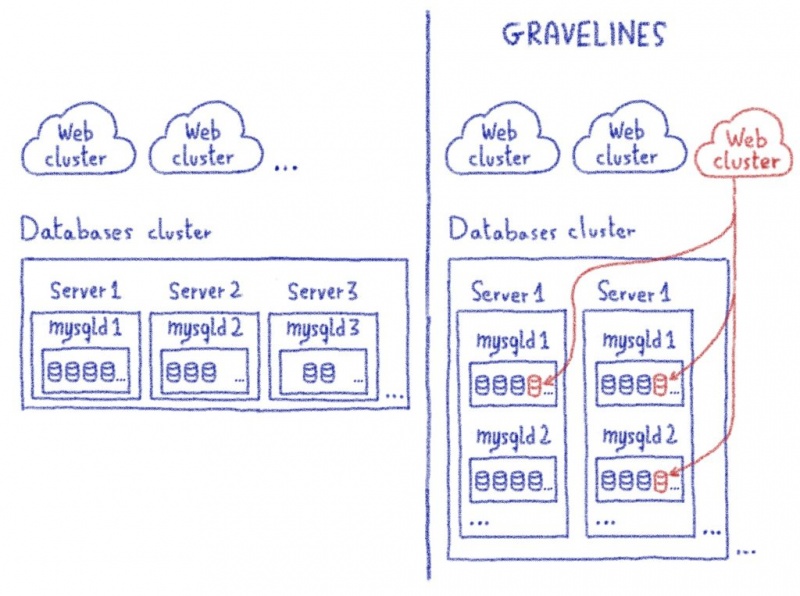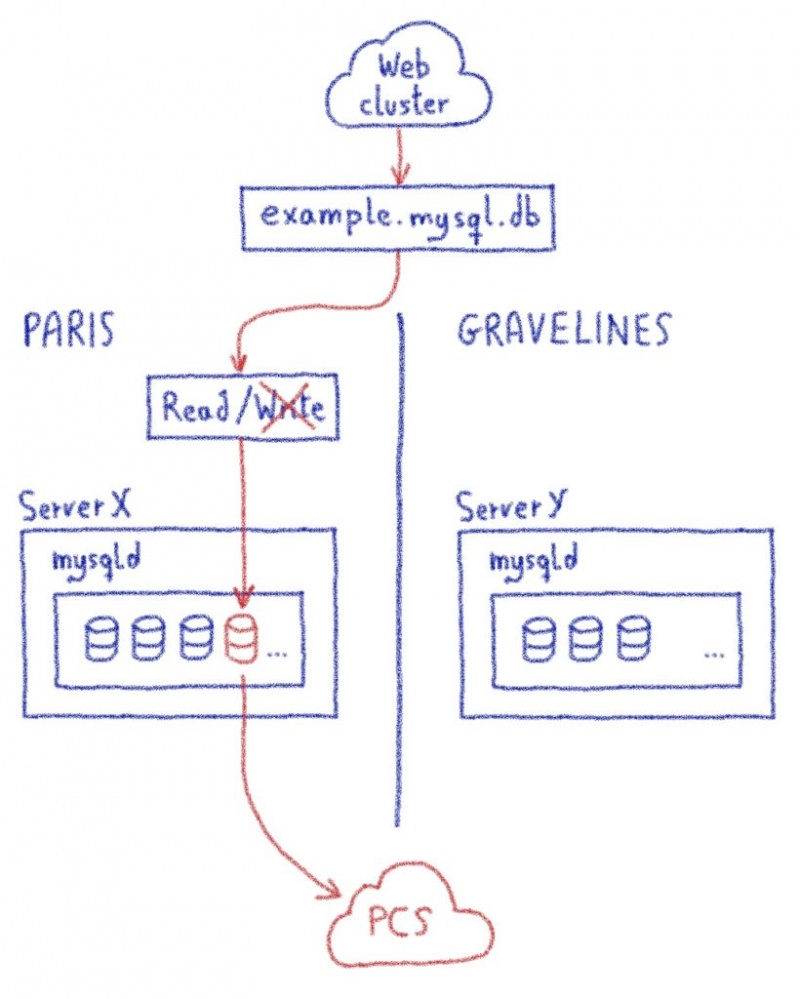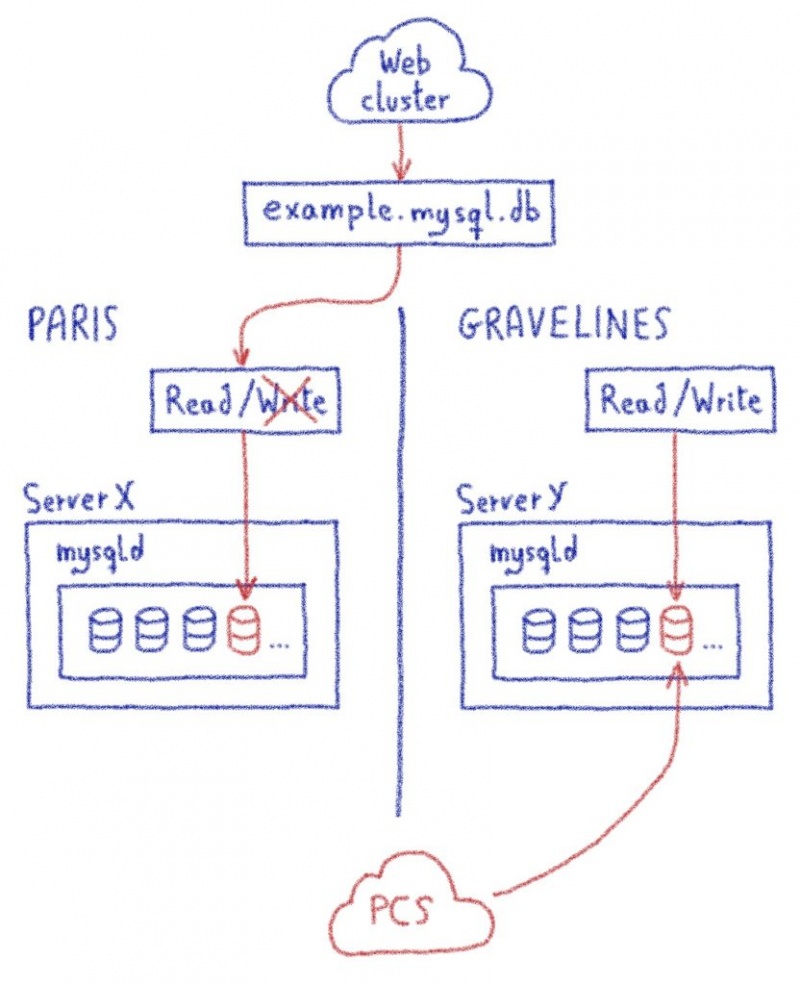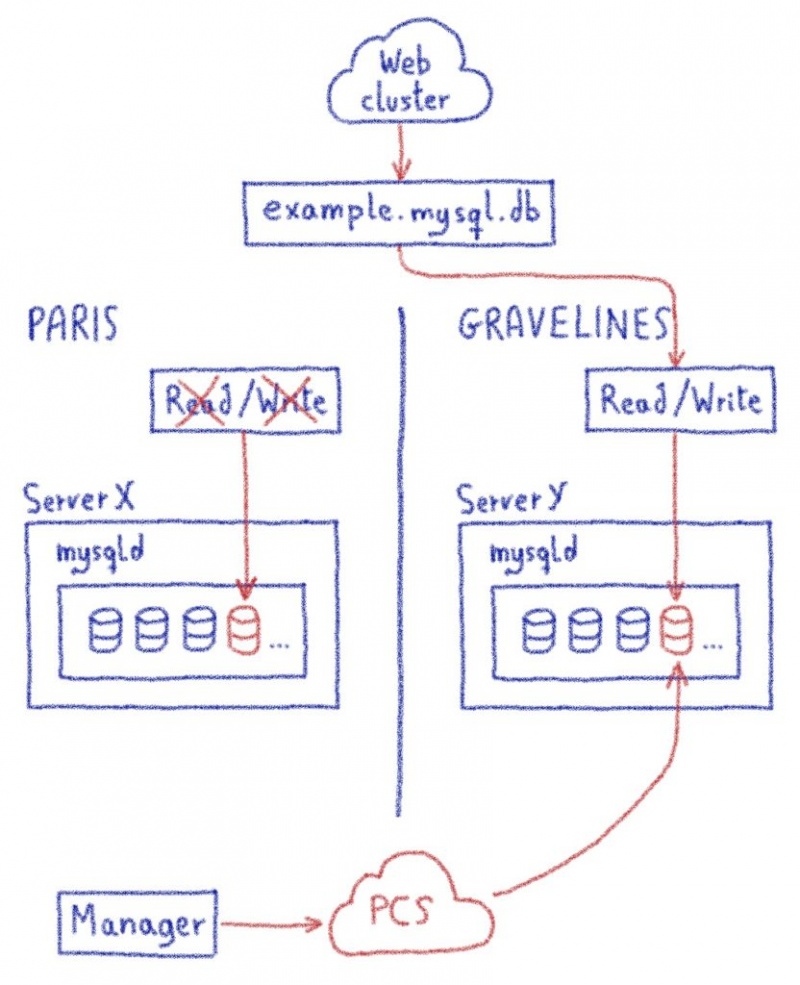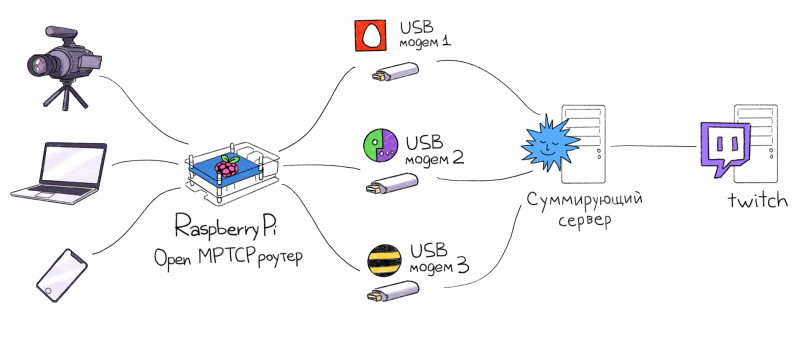
Можно ли объединить несколько интернет-каналов в один? Вокруг этой темы куча заблуждений и мифов, даже сетевые инженеры с опытом часто не знают о том, что это возможно. В большинстве случаев, объединением каналов ошибочно называют балансировку на уровне NAT или failover. Но настоящее суммирование позволяет пустить одно единственное TCP-подключение одновременно по всем интернет-каналам, например видеотрансляцию так, чтобы при обрыве любого из интернет-каналов вещание не прерывалось.
Существуют дорогие коммерческие решения для видеотрансляций, но такие устройства стоят много килобаксов. В статье описывается настройка бесплатного, открытого пакета OpenMPTCPRouter, разбираются популярные мифы о суммировании каналов.
Мифы про суммирование каналов
Есть много бытовых роутеров, поддерживающих функцию Multi-WAN. Иногда производители называют это суммированием каналов, что не совсем верно. Многие сетевики верят, что кроме LACP и суммирования на L2 уровне, никакого другого объединения каналов не существует. Мне часто доводилось слышать, что это вообще невозможно от людей, которые работают в телекомах. Поэтому попробуем разобраться в популярных мифах.
Балансировка на уровне IP-подключений
Это самый доступный и популярный способ утилизировать несколько интернет-каналов одновременно. Для простоты представим, что у вас есть три интернет провайдера, каждый выдаёт вам реальный IP-адрес из своей сети. Все эти провайдеры подключены в роутер с поддержкой функции Multi-WAN. Это может быть OpenWRT с пакетом mwan3, mikrotik, ubiquiti или любой другой бытовой роутер, благо сейчас такая опция уже не редкость.
Для моделирования ситуации представим, что провайдеры выдали нам такие адреса:
WAN1 — 11.11.11.11
WAN2 — 22.22.22.22
WAN2 — 33.33.33.33
То есть, подключаясь к удалённому серверу example.com через каждого из провайдеров, удаленный сервер будет видеть три независимых source ip клиента. Балансировка позволяет разделить нагрузку по каналам и использовать их все три одновременно. Для простоты представим, что мы делим нагрузку между всеми каналами поровну. В итоге, когда клиент открывает сайт, на котором условно три картинки, он загружает каждую картинку через отдельного провайдера. На стороне сайта это выглядит как подключения с трёх разных IP.
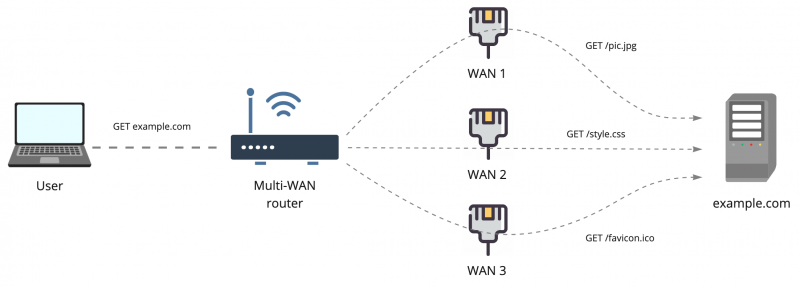
Такой режим балансировки часто несёт проблемы для пользователей. Например, многие сайты жёстко привязывают cookie и токены к IP-адресу клиента, и если он внезапно изменился, то запрос отбрасывается или клиента разлогинивает на сайте. Это часто воспроизводится в системах клиент-банка и на других сайтах со строгими правилами пользовательских сессий. Вот простой наглядный пример: музыкальные файлы в VK.com доступны только при действительном ключе сессии, который привязан к IP, и у клиентов, использующих такую балансировку, часто не проигрываются аудио, потому что запрос ушёл не через того провайдера, к которому привязана сессия.
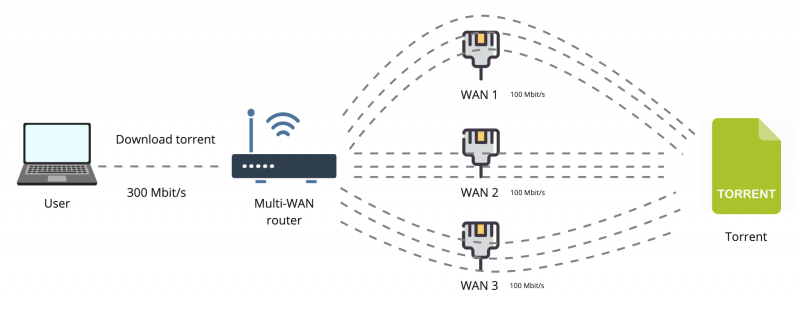
Такая балансировка позволяет получить суммирование скорости интернет-канала, при использовании множества подключений. Например, если у каждого из трёх провайдеров скорость 100 Мегабит, то при загрузке торрентов мы получим 300 Мегабит. Потому что торрент открывает множество подключений, которые распределяются между всеми провайдерами и в итоге утилизируют весь канал.
Важно понимать, что одно единственное TCP-подключение всегда пройдёт только через одного провайдера. То есть если мы скачиваем один большой файл по HTTP, то это подключение будет выполнено через одного из провайдеров, и если связь с этим провайдером оборвется, то загрузка тоже сломается.
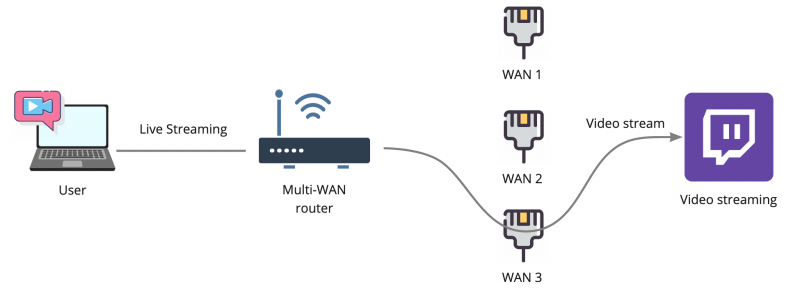
Это справедливо и для видео-трансляций. Если вы вещаете потоковое видео на какой-то условный Twitch, то балансировка на уровне IP-подключений не даст никакой особенной пользы, так как видео-поток будет транслироваться внутри одного IP-подключения. В данном случае, если у провайдера WAN 3 начнутся проблемы со связью, например потери пакетов или снижение скорости, то вы не сможете моментально переключиться на другого провайдера. Трансляцию придётся останавливать и переподключаться заново.
Настоящее суммирование каналов
Реальное суммирование каналов даёт возможность пустить одно подключение к условному Twitch сразу через всех провайдеров таким образом, что, если любой из провайдеров сломается, подключение не оборвется. Это на удивление сложная задача, которая до сих пор не имеет оптимального решения. Многие даже не знают, что такое возможно!
По предыдущим иллюстрациям мы помним, что условный сервер Twitch может принять от нас видеопоток только от одного source IP адреса, значит он должен быть у нас всегда постоянным, вне зависимости от того, какие провайдеры у нас отвалились, а какие работают. Чтобы этого добиться, нам потребуется суммирующий сервер, который будет терминировать все наши подключения и объединять их в одно.
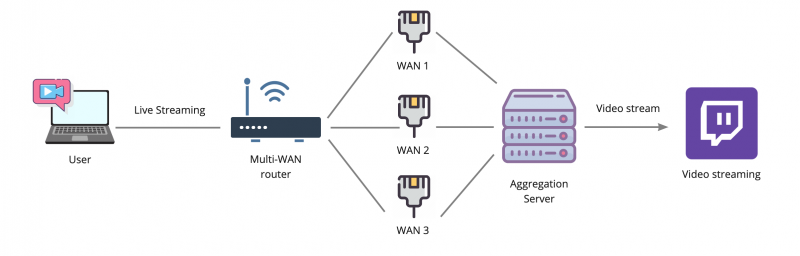
В такой схеме используются все провайдеры, и отключение любого из них не вызовет обрыв связи с сервером Twitch. По сути, это особый VPN-тоннель, под капотом у которого сразу несколько интернет-каналов. Главная задача такой схемы — получить максимально качественный канал связи. Если на одном из провайдеров начались проблемы, потеря пакетов, увеличение задержек, то это не должно никак отразиться на качестве связи, так как нагрузка автоматически будет распределяться по другим, более качественным каналам, которые есть в распоряжении.
Коммерческие решения
Эта проблема давно беспокоит тех, кто ведёт прямые трансляции мероприятий и не имеет доступа к качественному интернету. Для таких задач существуют несколько коммерческих решений, например компания Teradek делает такие монструозные роутеры, в которые вставляются пачки USB модемов:

В таких устройствах, обычно, встроена возможность захвата видеосигнала по HDMI или SDI. Вместе с роутером продаётся подписка на сервис суммирования каналов, а также обработки видеопотока, перекодирования его и ретрансляции дальше. Цена таких устройств начинается от 2к$ с комплектом модемов, плюс отдельно подписка на сервис.
Иногда это выглядит достаточно устрашающе:
 Настраиваем OpenMPTCPRouter
Настраиваем OpenMPTCPRouter
Протокол MP-TCP (MultiPath TCP) придуман для возможности подключения сразу по нескольким каналам. Например, его поддерживает iOS и может одновременно подключать к удалённому серверу по WiFi и через сотовую сеть. Важно понимать, что это не два отдельных TCP-подключения, а именно одно подключение, установленное сразу по двум каналам. Чтобы это работало, удалённый сервер должен поддерживать MPTCP тоже.
OpenMPTCPRouter — это открытый проект программного роутера, позволяющего по-настоящему суммировать каналы. Авторы заявляют, что проект находится в статусе альфа-версии, но им уже можно пользоваться. Он состоит из двух частей — суммирующего сервера, который размещается в интернете и роутера, к которому подключаются несколько интернет-провайдеров и сами клиентские устройства: компьютеры, телефоны. В качестве пользовательского роутера может выступать Raspberry Pi, некоторые WiFi-роутеры или обычный компьютер. Есть готовые сборки под различные платформы, что очень удобно.
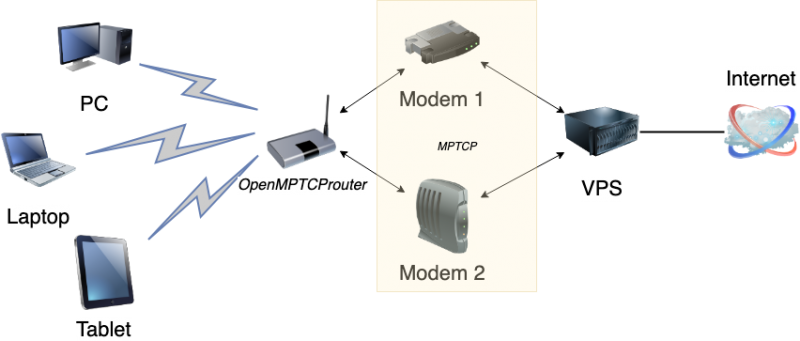 Настройка суммирующего сервера
Настройка суммирующего сервера
Суммирующий сервер располагается в интернете и терминирует подключения со всех каналов клиентского роутера в одно. IP-адрес этого сервера будет внешним адресом при выходе в интернет через OpenMPTCPRouter.
Для этой задачи будем использовать VPS-сервер на Debian 10.
Требования к суммирующему серверу:
- MPTCP не работает на виртуализации OpenVZ
- Должна быть возможность установки собственного ядра Linux
Сервер разворачивается выполнением одной команды. Скрипт установит ядро с поддержкой mptcp и все необходимые пакеты. Доступны установочные скрипты для Ubuntu и Debian.
wget -O - http://www.openmptcprouter.com/server/debian10-x86_64.sh | sh
Результат успешной установки сервера.
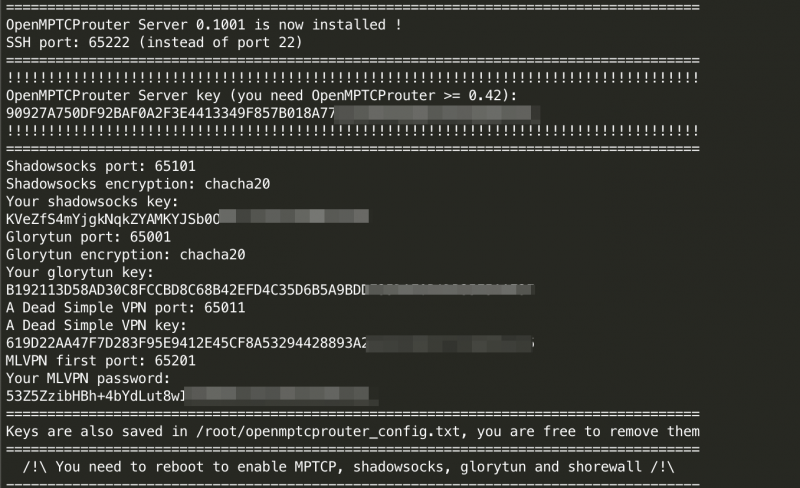
Сохраняем пароли, они потребуются нам для настройки клиентского роутера, и перезагружаемся. Важно иметь в виду, что после установки SSH будет доступен на порту 65222. После перезагрузки нужно убедиться, что мы загрузились с новым ядром
uname -a
Linux test-server.local 4.19.67-mptcp
Видим рядом с номером версии надпись mptcp, значит ядро установилось корректно.
Настройка клиентского роутера
На сайте проекта доступны готовые сборки для некоторых платформ, например Raspberry Pi, Banana Pi, роутеры Lynksys и виртуальные машины.
Эта часть openmptcprouter основана на OpenWRT, в качестве интерфейса используется LuCI, знакомый всем, кто когда-либо сталкивался с OpenWRT. Дистрибутив весит около 50Мб!

В качестве тестового стенда я буду использовать Raspberry Pi и несколько USB-модемов с разными операторами: МТС и Мегафон. Как записать образ на SD-карту, полагаю, не нужно рассказывать.
Изначально Ethernet-порт в Raspberry Pi настроен как lan со статическим IP-адресом 192.168.100.1. Чтобы не возиться с проводами на столе, я подключил Raspberry Pi к WiFi точке доступа и задал на WiFi-адаптере компьютера статический адрес 192.168.100.2. DHCP-сервер по умолчанию не включен, поэтому нужно использовать статические адреса.
Теперь можно зайти в веб-интерфейс 192.168.100.1
При первом входе система попросит задать пароль root, с этим же паролем будет доступен SSH.
В настройках LAN можно задать нужную подсеть и включить DHCP-сервер.
Я использую модемы, которые определяются как USB Ethernet интерфейсы с отдельным DHCP-сервером, поэтому это потребовало установки дополнительных пакетов. Процедура идентична настройке модемов в обычном OpenWRT, поэтому я не буду рассматривать её здесь.
Далее нужно настроить WAN-интерфейсы. Изначально в системе создано два виртуальных интерфейса WAN1 и WAN2. Им нужно назначить физическое устройство, в моем случае это имена интерфейсов USB-модемов.
Чтобы не запутаться в именах интерфейсов, я советую смотреть сообщения dmesg, подключившись по SSH.
Так как мои модемы сами выступают роутерами, и сами имеют DHCP-сервер, мне пришлось изменить настройки их внутренних диапазонов сетей и отключить DHCP-сервер, потому что изначально оба модема выдают адреса из одной сети, а это вызывает конфликт.
OpenMPTCPRouter требует, чтобы адреса WAN-интерфейсов были статическими, поэтому придумываем модемам подсети и настраиваем в меню system → openmptcprouter → interface settings. Здесь же нужно указать IP-адрес и ключ сервера, полученный на этапе установки суммирующего сервера.
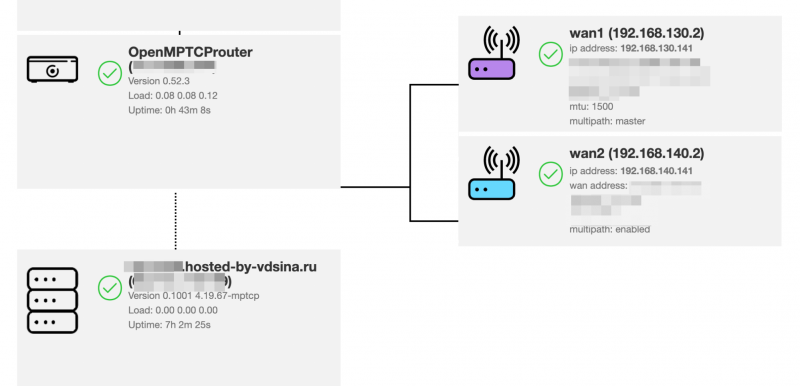
В случае удачной настройки, на странице статуса должна появится похожая картина. Видно, что роутер смог достучаться до суммирующего сервера и оба канала работают штатно.
По умолчанию используется режим shadowsocks + mptcp. Это такой прокси, который заворачивает в себя все подключения. Изначально он настроен обрабатывать только TCP, но можно включить и UDP.
Если на странице статуса нет ошибок, на этом настройку можно считать законченной.
С некоторыми провайдерами может возникнуть ситуация, когда на пути следования трафика флаг mptcp обрезается, тогда будет такая ошибка:
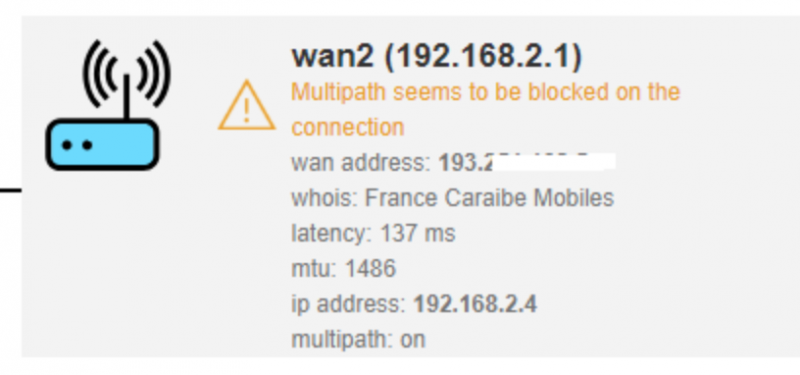
В этом случае можно использовать другой режим работы, без использования MPTCP, подробнее об этом
здесь
Заключение
Проект OpenMPTCPRouter очень интересный и важный, так как это, пожалуй, единственное открытое комплексное решение проблемы суммирования каналов. Всё остальное либо наглухо закрытое и проприетарное, либо просто отдельные модули, разобраться с которыми обычному человеку не под силу. На текущем этапе развития проект ещё достаточно сырой, крайне бедная документация, многие вещи просто не описаны. Но при этом он всё-таки работает. Надеюсь, что он будет и дальше развиваться, и мы получим бытовые роутеры, которые будут уметь нормально объединять каналы из коробки.