Хеллоу, диа френдс!
Впереди ещё целый месяц лета, и это прекрасно. Так же как и то, что завтра пятница и День системного администратора в одном флаконе. С чем вас и поздравляем! И прежде, чем мы традиционно начнём рассказывать о самом интересном за месяц, предлагаем пройти короткий тест на интуицию. Посмотрите на фото наших ребят и угадайте, кто из них настоящий системный администратор. Отгадка ниже.

Ну, а теперь коротко о том, что мы для вас приготовили. Статьи про вирусы и взломы, новости о Турбо-тарифах, уязвимости месяца и на десерт — ещё один тест на тру-сисадмина, который поможет определить, кто есть кто. В общем, если хардкор, скорость и драйв — это то, что вам нужно накануне праздничной пятницы, то вам сюда. Погнали!
Статьи и инструкции
О взломах, вирусах и способах борбы с ними
Чем больше жизнь перетекает в онлайн, тем больше желающих приходит отыскать слабое звено в ваших сайтах. И ладно бы с благими целями, так ведь нет. Взломы, вирусы, слив данных пользователей… счёт идет на секунды… В общем, боевик какой-то. Кстати, заметили, что в таких фильмах побеждает тот, кто успевает подготовиться? Пулемет зарядить, ловушек наставить, ну, или хотя бы морально собраться. Так вот пока есть время, берите пример с Рэмбо: если войны избежать не получится, то хотя бы будете знать, как отстреливаться. Подобрали тут для изучения матчасти:
О проблемах с доступностью сайта и сервера
Код 200 на языке протокола HTTPS — почти то же самое, что «окей» на английском. Только для сайта, который сообщает, что с ним все в порядке. Причины, почему с сайтом может быть не «окей», бывают самые разные. Но это не значит, что пришла пора опускать руки — для начала можно найти, где и что именно пошло не так. А там, глядишь, и решение отыщется. Кстати, если по сети недоступен сервер — рекомендации те же: искать и не сдаваться. Подробнее об этом в наших статьях в базе знаний. Не Чернышевский конечно, но на вопрос «что делать» ответы имеются.
О правильных запросах в поддержку
Средняя скорость ответа нашей техподдержки — 15 минут. Но кто не мечтает о том, чтобы ему отвечали мгновенно. Мы бы и сами так хотели, честно. Увы, человеческие и технические возможности имеют свои пределы. Правда, есть тут один лайфхак. Чтобы обработка тикета проходила быстрее, нужно правильно составить текст запроса. О том, как это работает, чистосердечно рассказываем в статье. Прям тут.
Новости
Турбо-тарифы стали еще быстрее

Если пропустили новость от Intel о выпуске процессоров Core десятого поколения i9-10900K — не беда. Главное, не пропустить тот факт, что теперь у нас есть виртуальные серверы на базе этих процессоров — с частотой до 5,3 ГГц. Еще одна хорошая новость: мощность VDS выросла, а цена нет. За техническими характеристиками, результатами тестов и подробностями — сюда.
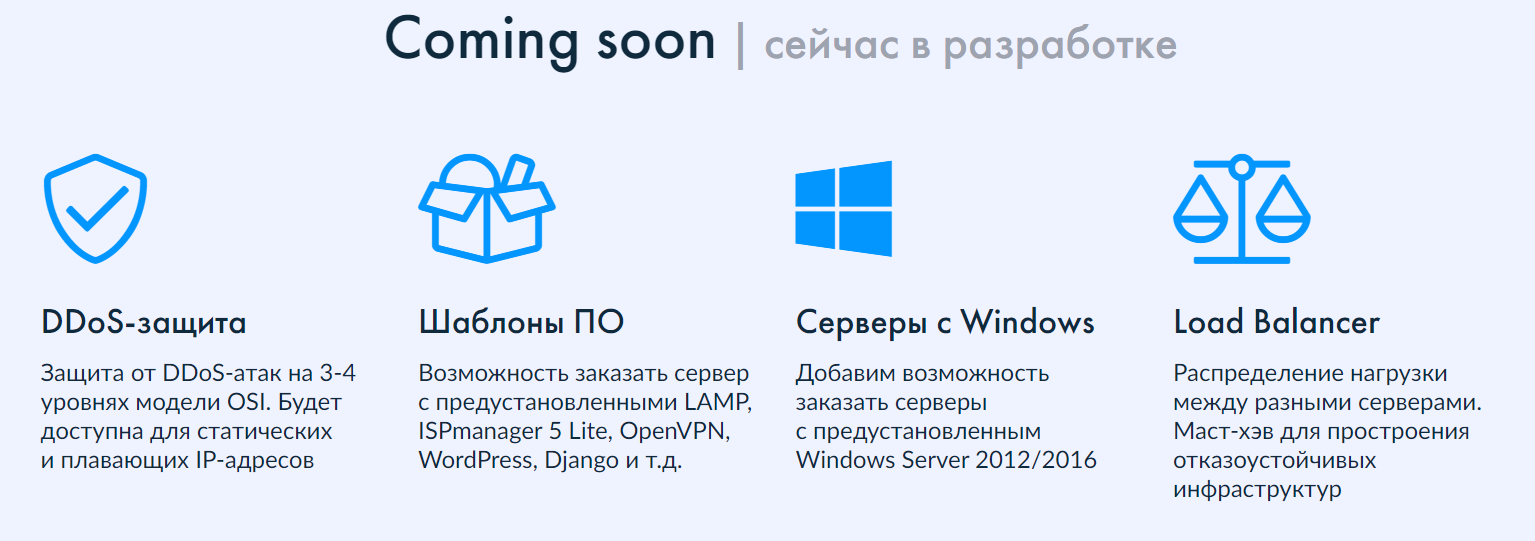
В сервисе CLO появились пять новых функций
Команда разработки проекта CLO не сидит сложа руки даже летом. И пока вы читаете новости — тоже. Но о перспективах чуть позже. А сейчас о том, что же изменилось с момента старта.
- Добавилась возможность заказывать сервер, самостоятельно настраивая нужное количество ресурсов. В разумных пределах, естественно.
- Также вы можете изменить ресурсы уже созданных серверов как в большую, так и в меньшую сторону.
- Если при запуске ОСи возникают ошибки, теперь можно перевести сервер в режим восстановления и получить доступ к консоли, чтобы починить всё, что сломалось.
- Пополнился список способов оплаты — стали доступны банковские переводы.
- Усилили систему безопасности, добавив возможность подключения двухфакторной аутентификации.
Подробнее в базе знаний CLO, ссылки прилагаются.
В ближайшее время команда проекта планирует добавить кое-что ещё. Если хотите быть в курсе всех изменений и планов по развитию CLO, заглядывайте на сайт проекта.
clo.ru/about
Уязвимости месяца
Уязвимости в libc и IPv6-стеке FreeBSD
Для кого-то июль оказался весьма плодотворным. Во FreeBSD устранено четыре уязвимости, позволяющие локальному пользователю получить больше прав, и три проблемы, не связанные с безопасностью, но от этого не менее опасные, так как при совпадении некоторых условий вполне способны привести к краху ядра. Совет традиционный — обнулитесь обновитесь. Подробнее об уязвимостях на opennet.ru
www.opennet.ru/opennews/art.shtml?num=53317
50 тысяч TLS-сертификатов EV подлежат отзыву
В начале месяца удостоверяющий центр Digicert сообщил, что 11 июля намерен отозвать около 50 тысяч сертификатов уровня EV. Такое решение было связано с тем, что расширенные отчёты по этим сертификатам за почти пятилетний период были пропущены. Отзыву подлежат сертификаты, выданные через аккредитованные удостоверяющие центры, не фигурирующие в отчётах для аудита. Изменение коснется клиентов, выпустивших EV-сертификаты в центрах сертификации CertCentral, Symantec, Thawte и GeoTrust, им может потребоваться перевыпуск. Подробнее на opennet.ru
www.opennet.ru/opennews/art.shtml?num=53334
Время Flash Player истекает
31 декабря 2020 года — официальная дата end of life (EOL) Flash Player, анонсированная компанией Adobe. После этого дня поддержка технологии будет прекращена, а выпуск обновлений завершится. В Adobe также намерены ликвидировать все загрузочные ссылки с сайта, добавить в код блокировки для запуска и обратиться к пользователям с просьбой удалить Flash Player со своих компьютеров, чтобы исключить возможность установки и использования неподдерживаемого ПО. Ведь после того, как технология лишится поддержки, она станет более уязвимой — компания планирует сделать всё, чтобы защитить пользователей. Подробнее на xakep.ru
xakep.ru/2020/06/22/uninstall-flash-player/
В Windows DNS Server устранена критическая уязвимость 17-летней давности
Критическая уязвимость существовала в коде 17 лет прежде, чем была обнаружена специалистами компании Check Point в мае этого года. Она уже успела получить кодовое имя SigRed, 10 из 10 баллов по шкале оценки уязвимости, что означает высокий уровень опасности, и мотивировать компанию Microsoft на экстренное устранение проблемы. Так как эксплуатация уязвимости почти не требует технических знаний, а сама она может быть использована для удаленных атак, рекомендуется не затягивать с обновлением. От слова совсем. Подробнее на xakep.ru
xakep.ru/2020/07/15/sigred/