Продолжение черной пятницы
hosting.kitchen/abcd-host/servery-so-skidkami-na-chernuyu-pyatnicu-2020.html
Мы рады сообщить о Черной пятнице на ABCD.HOST! В течении недели вы можете приобрести у нас выделенные серверы со скидкой 25-30%, выделенные серверы с бесплатной установкой и скидкой на установку!
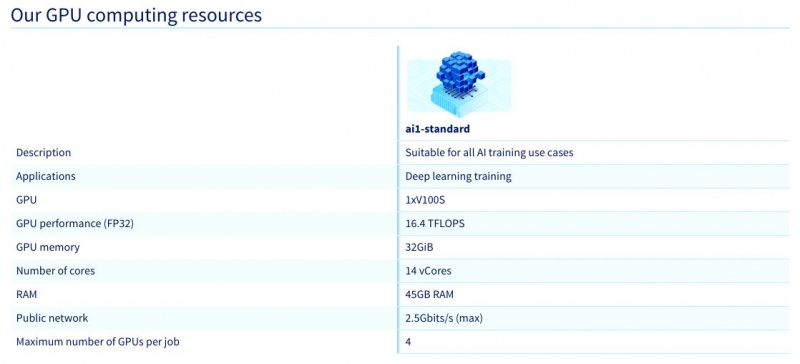
Конфигурации выделенных серверов
Скидки 25-30%
FR,CA E3-1245v2 [4c-8t] (3.8GHz) / 32 DDR3 1600 MHz / 3x 2 TB / 500 Mbps — 3080р./мес. 1980р. установка
FR,CA E3-1245v2 [4c-8t] (3.8GHz) / 32 DDR3 1600 MHz / 2x 960 SSD / 500 Mbps — 3300р./мес. 1980р. установка
FR,CA E5-1620v2 [4c-8t] (3.9GHz) / 64GB DDR3 ECC 1600MHz / 2x 480GB SSD / 500 Mbps — 3850р./мес. 1980р. установка
FR,CA E5-1620v2 [4c-8t] (3.9GHz) / 64GB DDR3 ECC 1600MHz / 2x 4TB HDD SATA / 500 Mbps — 3850р./мес. 1980р. установка
Доступные локации: *FR — Франция, CA — Канада.
Установка в течении 4 часов.
Бесплатная установка
DE,FI Intel Core i7-6700 [4c-8t] (4.0GHz) / 64 GB DDR4 / 2×4 TB 1 Gbps 4485р./мес.
DE,FI Intel Core i7-6700 [4c-8t] (4.0GHz) / 64 GB DDR4 / 2×512 GB NVMe SSD 1 Gbps — 4485р./мес.
DE,FI Intel Core i7-8700 [6c-12t] (4.6GHz) / 128 GB DDR4 / 2×8 TB SATA 6 Gb/s 1 Gbps — 6785р./мес.
DE,FI Intel Core i7-8700 [6c-12t] (4.6GHz) / 128 GB DDR4 / 2×1 TB NVMe SSD 1 Gbps — 6785р./мес.
DE,FI Intel Core i9-9900K [8c-16t] (5.0GHz) / 128 DDR4 2666 MHz / 2×8 TB SATA 6 Gb/s 1 Gbps — 7935р./мес.
DE,FI Intel Core i9-9900K [8c-16t] (5.0GHz) / 128 DDR4 2666 MHz / 2×1 TB NVMe SSD 1 Gbps — 7935р./мес.
DE,FI Intel Xeon W-2145 [8c-16t] (4.5GHz) / 256 GB DDR4 ECC / 2×960 GB NVMe SSD 1 Gbps — 19800р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 128 GB DDR4 ECC / 2×960 GB NVMe SSD 1 Gbps — 13685р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 128 GB DDR4 ECC / 2×3.84 TB NVMe SSD 1 Gbps — 23650р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 128 GB DDR4 ECC / 2×12 TB SATA 1 Gbps — 18920р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 256 GB DDR4 ECC / 2×960 GB NVMe SSD 1 Gbps — 22000р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 256 GB DDR4 ECC / 2×3.84 TB NVMe SSD 1 Gbps — 28930р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 256 GB DDR4 ECC / 2×12 TB SATA 1 Gbps — 24200р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 512 GB DDR4 ECC / 2×960 GB NVMe SSD 1 Gbps — 32560р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 512 GB DDR4 ECC / 2×3.84 TB NVMe SSD 1 Gbps — 39490р./мес.
DE,FI AMD EPYC 7502P [32c-64t] (3.4GHz) / 512 GB DDR4 ECC / 2×12 TB SATA 1 Gbps — 34760р./мес.
Доступные локации: * DE — Германия, FI — Финляндия
Установка в течении 2 часов.
Автоматическая переустановка ОС/перезагрузка через панель.
Скидки 25-30% и бесплатная установка
PL,UK,FR,CA Intel Xeon-D 1521 [4c-8t] (2.7GHz) / 16GB DDR4 ECC 2133MHz / 4×4 TB HDD SATA + 1×500 GB SSD NVMe 1Gbps — 6380р./мес.
PL,UK,FR,CA Intel Xeon-D 1521 [4c-8t] (2.7GHz) / 16GB DDR4 ECC 2133MHz / 4×6 TB HDD SATA + 1×500 GB SSD NVMe 1Gbps — 9350р./мес.
PL,UK,FR,CA Intel Xeon-D 1541 [8c-16t] (2.7GHz) / 32GB DDR4 ECC 2133MHz / 4×12 TB HDD SATA + 2×240 GB SSD SATA 1Gbps — 10120р./мес.
PL,UK,FR,CA Intel Xeon-D 1541 [8c-16t] (2.7GHz) / 32GB DDR4 ECC 2133MHz / 6×12 TB HDD SATA + 1×500 GB SSD NVMe 1Gbps — 13530р./мес.
DE,PL,UK,FR,CA Intel Xeon E3-1270v6 [4c-8t] (4.2GHz) / 32GB DDR4 ECC 2400MHz / 2x2TB HDD SATA 500Mbps — 4950р./мес.
DE,PL,UK,FR,CA,AU,SGP Intel Xeon E3-1230v6 [4c-8t] (3.9GHz) / 32GB DDR4 ECC 2133MHz / 2x 450 SSD NVMe 500Mbps — 5610р./мес.
DE,PL,UK,FR,CA,AU,SGP Intel i7-7700K [4c-8t] (4.5GHz) / 32GB DDR4 ECC 2133MHz / 2x4TB HDD SATA 500Mbps — 5500р./мес.
DE,PL,UK,FR,CA,AU,SGP Intel i7-7700K [4c-8t] (4.5GHz) / 32GB DDR4 ECC 2133MHz / 2x450GB SSD NVMe 500Mbps — 6490р./мес.
FR,CA Intel Intel i7-6700K [4c-8t] (4.2GHz) / 64GB DDR4 ECC 2400MHz / 2×960 GB SSD NVMe 1Gbps — 6930р./мес.
DE,PL,UK,FR,CA Intel Xeon E5-1650v4 [6c-12t] (4.0GHz) / 64GB DDR4 ECC 2133MHz / 2x2TB HDD SATA 500Mbps — 5940р./мес.
DE,PL,UK,FR,CA Intel Xeon E5-1650v4 [6c-12t] (4.0GHz) / 64GB DDR4 ECC 2133MHz / 2x450GB SSD NVMe 500Mbps — 6930р./мес.
DE,PL,UK,FR,CA Intel Xeon E5-1650v4 [6c-12t] (4.0GHz) / 128GB DDR4 ECC 2133MHz / 2x450GB SSD NVMe 500Mbps — 9900р./мес.
FR,CA Intel 2x Xeon E5-2630v3 [16c-32t] (3.2GHz) / 128GB DDR4 ECC 1866MHz / 2x4TB HDD SATA 500Mbps — 12870р./мес.
Доступные локации: *Европа (UK, FR, DE, FI, PL,NL), С.Америка (US, CA), Автралия (AU) и Сингапур (SGP)
Установка в течении 4 часов.
Автоматическая переустановка ОС/перезагрузка через панель.
Подробнее о конфигурациях в
прайс-листе и на странице
Черной пятницы 2020 на ABCD.HOST.
Выделенные серверы:
abcd.host/all-dedicated-servers
Для заказа обращайтесь на sales@abcd.host, либо в
личный кабинет.
Спасибо что остаетесь с нами!
С уважением, ABCD.HOST.