Группа исследователей из Университета Клемсона достигла замечательной вехи при изучении моделирования темы, важного компонента машинного обучения, связанного с обработкой естественного языка, нарушая рекорд для создания крупнейшего высокопроизводительного кластера в облаке, используя более 1100 000 vCPU на Amazon Экземпляры EC2 работают в одном регионе AWS. Исследователи провели почти полмиллиона экспериментов по моделированию томов, чтобы изучить, как человеческий язык обрабатывается компьютерами. Моделирование тем помогает выявить основные темы, которые присутствуют в коллекции документов. Модели темы важны, потому что они используются для прогнозирования тенденций в бизнесе и помощи в принятии решений о политике или финансировании. Эти тематические модели могут быть запущены со множеством различных параметров, и целью экспериментов является изучение того, как эти параметры влияют на результаты модели.
Эксперимент
Профессор Amy Apon, содиректор Института сложных систем, аналитики и визуализации в Университете Клемсона с профессором Александром Херцогом и аспирантами Брэндоном Поузи и Кристофером Гроппом в сотрудничестве с членами команды AWS, а также с партнером AWS Omnibond провели эксперименты. Они использовали программную инфраструктуру на основе CloudCluster, которая обеспечивает высокопроизводительные вычислительные кластеры для динамически распределенных ресурсов AWS с использованием Amazon EC2 Spot Fleet. Spot Fleet — это совокупность экземпляров спот-дисков в EC2, отвечающих за поддержание целевой емкости, указанной во время запроса. Планировщик SLURM использовался в качестве накладного менеджера виртуальной рабочей нагрузки для рабочих процессов аналитики данных. Команда разработала дополнительное программное обеспечение для автоматизации инициализации и документооборота, как показано ниже для проектирования и организации экспериментов. Эта настройка позволяла им оценивать различные модели тем для разных наборов данных с массивно-параллельными развертками параметров на динамически распределенных ресурсах AWS. Эта структура может быть легко использована за пределами текущего исследования для других научных приложений, использующих параллельные вычисления.
 Увеличение до 1,1 млн. VCPU
Увеличение до 1,1 млн. VCPU
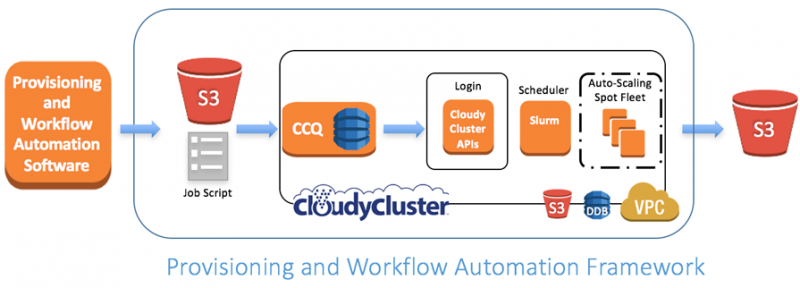
На приведенном ниже рисунке показано эластичное, автоматическое расширение ресурсов в зависимости от времени в регионе США (Северная Вирджиния). Сразу после 21:40 (GMT-1) 26 августа 2017 года количество используемых vCPU составило 1,119,196. Исследователи Clemson также воспользовались новой оплатой за каждую секунду для экземпляров EC2, которые они запускали. Использование счетчика vCPU сопоставимо с количеством ядер на крупнейших суперкомпьютерах в мире.
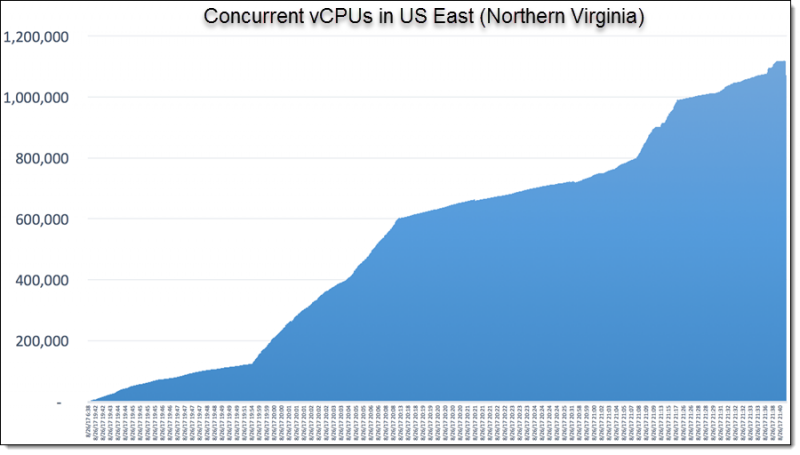 Вот разбивка типов экземпляров EC2, которые они использовали:
Вот разбивка типов экземпляров EC2, которые они использовали:
Ресурсы кампуса в Клемсоне, финансируемые Национальным научным фондом, были использованы для определения эффективной конфигурации экспериментов AWS по сравнению с ресурсами кампуса, а облачные ресурсы AWS дополняют ресурсы кампуса для крупномасштабных экспериментов.
Встретить команду
Вот команда, которая провела эксперимент (профессор Александр Херцог, аспиранты Кристофер Гропп и Брэндон Поузи и профессор Эми Апон):
 Профессор Апон сказал об эксперименте:
Профессор Апон сказал об эксперименте:
Я абсолютно в восторге от результатов этого эксперимента. Ученики-выпускники проекта потрясающие. Они использовали ресурсы от AWS и Omnibond и разработали новую программную инфраструктуру для проведения исследований по шкале, а время до завершения невозможно с использованием только ресурсов кампуса. Вторым биллинг был ключевым фактором этих экспериментов.
Бойд Уилсон (генеральный директор Omnibond, член сети партнеров AWS) сказал:
Участие в этом проекте было захватывающим, видя, как команда Clemson разработала инструмент автоматизации и обработки рабочего процесса, который привязан к CloudCluster для создания огромного суперкомпьютера Spot Fleet в одном регионе в AWS.
О эксперименте
Эксперименты проверяют комбинации параметров по ряду тем и другим параметрам, используемым в модели темы. Выходы модели темы хранятся в Amazon S3 и в настоящее время анализируются. Модели были применены к 17 годам рефератов журнала компьютерных наук (533 560 документов и 32 551 540 слов) и полнотекстовым документам конференции NIPS (Neural Information Processing Systems) (2 484 документа и 3280 697 слов). Это исследование позволяет научно-исследовательской группе систематически измерять и анализировать влияние параметров и выбор модели на конвергенцию модели, состав темы и качество.
Жду с нетерпением
Это исследование представляет собой взаимодействие между информатикой, искусственным интеллектом и высокопроизводительными вычислениями. Документы, описывающие полное исследование, представляются для рецензируемой публикации. Я надеюсь, что вам понравилось это краткое представление о том, как AWS помогает нарушить границы в границах обработки естественного языка!
— Санджай Падхи, доктор философии, AWS Research and Technical Computing