Это был тяжёлый год, был он тяжелей, чем тот.
В этом году Центробанк выставил высокие ставки и фактически перекрыл возможность строить ЦОДы за кредитные деньги. А если что, то дата-центры строятся за колоссальные деньги. То есть исключительно на кредиты — с тем, чтобы потом продавать их мощности и постепенно отбивать кредитные деньги. То же самое происходит в других областях бизнеса, и почти везде практическая невозможность взять кредит означает стагнацию многих направлений бизнеса. За ипотеку же вообще можно слетать в космос!
Почему нельзя взять кредит? Потому что почти нет такого бизнеса, который даст денег больше, чем если просто положить их на счёт в банк. Правда, банкам я бы тоже не стал доверять на 100 % даже в случае депозитов, но это уже другая история.
А дефицит стойко-мест растёт. Уже в прошлые годы всё, что строилось, на 80 % раскупалось ещё на стадии строительства. То есть речь идёт даже не про текущие свободные стойки, а про предзаказы на то, что будет готово только в следующем году.
Цена размещения стойки уже выросла на 9–21 % в зависимости от колокации в России.
Кстати, познакомьтесь со звездой рынка — киргизскими серверами:

Это экспорт из Германии в Кыргызстан. Примерно такие же графики — по Польше, Австрии, Италии и т. п.
Дорожают сами серверы
Особенно если они покупаются новыми. А мы их покупаем новыми, и я знаю, что есть ещё ряд участников рынка, которые тоже покупают их новыми. Конечно, они часто покупались за кредитные деньги, то есть на заёмный капитал, но сейчас при таких ставках это тоже становится абсурдным.
Раньше мы покупали для Казахстана в Казахстане, и нам продавали. А сейчас нам не продают в Казахстане. В смысле даже для внутренних казахстанских ЦОДов не продают.
То есть да, там вроде можно получить все эти разрешения, написать в Минпромторг, но в итоге всё это очень дорого. Конечно, мы покупаем в России и других странах, несмотря на такие проблемы, однако это сильно увеличивает конечную стоимость железа.
ВНЕЗАПНО акционерный капитал стал выгоднее, чем заёмный
Именно поэтому куча всяких провайдеров объявляет о своих планах на IPO. Потому что дешевле продать долю в компании через акции, чем привлечь кредит под развитие. Звучит как бы логично, но именно с точки зрения IPO момент на рынке сейчас неоднозначный. Можно разместиться, привлечь капитал, но сама компания будет оценена не очень высоко. Те, кто всего боится, говорят: «Неблагоприятная обстановка на рынке». Те, кто посмелее, говорят, что это неопределённость, связанная с СВО. Высоких оценок тоже не будет, потому что наш рынок сейчас лишён зарубежных инвестиций.
То есть можно выйти на IPO, но за мелкий прайс. Хотя есть отдельные стратеги, которые смотрят и на 10 лет вперёд, но таких внутри рынка мало. Казалось бы, тут должны появляться наши азиатские друзья и братские народы, но их тоже пока что-то нет.
Вот, например, смешная новость про то, как Селектел хотел-хотел на IPO, но пока бежал, концепция поменялась. Там это назвали «не видит подходящего окна для IPO на фоне рыночной ситуации». Вообще, когда вы проводите IPO, гораздо сложнее манипулировать отчётами и говорить, что у вас первое место на рынке, второе, третье и так далее. Отчётность аудируется очень внимательными и занудными людьми, потом они дадут предварительные оценки, которые могут не сойтись с фантазиями. Возможно, параллельно они ведут торг с каким-то крупным игроком рынка, не знаю, хотят так продать целиком компанию, но это всё мои домыслы. В целом IPO или слияние-поглощение провести сейчас дешевле, чем привлечь кредитные деньги.
Налоговая реформа
Впервые чуть ли не за 20 лет — системно: новые правила, новые налоговые режимы.
Раньше все упрощенцы работали на одной налоговой ставке без НДС. Теперь порог для нулевого НДС снижен до 60 миллионов рублей. Компании с оборотом от 60 до 300 миллионов будут платить НДС по ставке 5 %, а от 300 до 480 миллионов рублей — по ставке 7 %.
Это значит, что многие компании, ранее не платившие НДС, теперь включат его в свои цены. То есть наши поставщики увеличат цены на размер этого НДС. А зачесть его нельзя: если в случае основного (не УСН) налогообложения НДС можно «передавать по цепочке» и каждый раз списывать в вычет, то вот этот НДС УСН-компаний так не умеет. Всем придётся либо повышать цены на свои услуги и товары, либо сокращать маржу, чтобы сохранить прибыльность. Вторых случаев на российском рынке я почти не помню, если что.
Особенно сильно это влияет на отрасли, где много компаний на УСН, например, IT-сектор. Многие IT-компании не зарегистрированы в реестре программного обеспечения и не имеют льгот по НДС. Они выбирали УСН, чтобы не вести отчётность и платить меньший налог. Теперь им придётся адаптироваться к новым условиям и либо оставаться на этой схеме и вести учёт (плюс затраты на софт, кстати), либо переходить на ОСН и тоже менять кучу процессов и строить отдел бухгалтерии. ОСН-компании этого почти не заметят, если их поставщики — тоже ОСН. Но таких на рынке хостинга можно пересчитать по пальцам.
Админы
А админов нет!
Мы недавно искали, прособеседовали где-то порядка 200 человек и взяли двоих. Это не считая тех, кто отсеялся до собеседования. Все эйчары, конечно, сильно недовольны работой с нами. Но мы тоже недовольны работой с ними.
Казалось бы, толпы бездомных голодных девопсов ходят по Долине и ищут, где бы поработать, но при этом в России админы всё ещё дико востребованы. И будут востребованы ещё долго. Ситуация на рынке остаётся напряжённой, и хороших спецов пылесосят, как обычно.
По крайней мере, в ближайшие годы админов будет всасывать Сбер: сейчас они начинают создание крупнейшего хостинг-провайдера. Там куча железа, которое надо обслуживать.
В целом, глядя на рынок, можно сказать, что сейчас создать новую хостинговую компанию, если, конечно, вы не Сбер и не Яндекс, просто невозможно. Потому что раньше команда искалась два-три месяца, а сейчас — год. Плюс смотрите выше про кредиты.
То есть в следующем году новые бизнесы запускаться не будут. По крайней мере, в нашей сфере. Ну только если слабоумие, отвага, Сбер и Яндекс.
Передел рынка
В одном из прошлых постов я ванговал, что сейчас сильные замочат или купят слабых и будет невиданный передел рынка. Так вот, он прошёл тише, чем ожидалось. Мы все были неправы, и из-за влияния регуляторки ничего крупного не случилось: требуемые меры оказались не так страшны, не стоит переживать. Все боялись, а это были просто расходы. Но по сравнению с инфляцией они оказались не очень значимыми. Сейчас надо либо каждый месяц поднимать цены, либо из-за падающей рентабельности экономить на качестве.
Экономить на качестве проще всего, закупая б/у железо, к примеру. Мы не можем так делать, мы ни разу не покупали ненадёжное и некорпоративное. И мы не собираемся отходить от парадигмы, потому что очень большая часть модели — гомогенное железо по всему миру, которое в разы проще админить, чем зоопарки. Значит, будем повышать цены, что делать… Два года мы их не повышали, уже пора.
Что стало с мелкими игроками за год? Мы думали, что они не смогут выполнить требований государства и потому будут вынуждены продаться. Но мелкие разделились на две части: первые не стали входить в реестр, стараясь изо всех сил делать вид, что эта ситуация происходит не с ними. Вторые понесли соответствующие расходы, повысив цены или на какое-то время став неприбыльными. Но при этом никто их не купил.
Почему не купил? Потому что — та-дам! — сделки требуют большого кредитного финансирования. Сейчас именно сделки слияния-поглощения, которых мы все ожидали из-за того, что ставки начали расти, не случились. Типа крупный провайдер должен взять у банка ВТБ кредит, чтобы купить кого-нибудь поменьше. Но крупный провайдер — не идиот и понимает, что с такими ставками эта покупка может быть, мягко говоря, невыгодна. Кроме того, банк понимает, что, может быть, это не лучшая идея — дать денег. И никто никого не покупает по всему рынку. Единственное, что мы наблюдали, — самой громкой сделкой была не прямая покупка, а обмен долями, когда
ГК «Астра» купили Rusonyx. Это скорее симбиотическое слияние. Возможно, в экстазе. Там не было потрачено никаких денег. Так что будут вот такие синергии и коллаборации.
Доля винды, конечно, продолжает падать
У нас некогда был чуть ли не стопроцентно виндовый хостинг. По России у нас под ней только 25 % виртуалок. Например, с 1 августа у нас было создано только 4 % виртуальных машин на Windows. Это очень мало.
Кто сидел на окнах — перешёл на Linux. Те, кто мог перейти, уже перешли. А есть те, кто не мог, например, работающие под специальным бухгалтерским софтом, проектировочным софтом для винды или ещё чём-то специальным. Я считаю, что окошки пока рано хоронить: есть большой сегмент около 1С, околобухгалтерского ПО, тонкие клиенты, удалённые рабочие столы, там, где всякие специализированные CRM, торговля, ресторанный бизнес.
Плюс Linux тоже оказался способен на сюрпризы, как мы видели.
Что делают клиенты? Если не могут добраться до лицензии, то берут виртуалку и катят туда десктопную винду, происхождения которой я не могу комментировать: это уже ответственность клиента.
У нас, кстати, винда лицензионная до сих пор. Обсмеётесь! Схема лицензирования сложная и через одно место, но она полностью чистая и белая. Дело в том, что у нас есть некоторые клиенты, которые требуют раскрытия цепочки лицензирования. Это нужно по политикам безопасности или другим аудитам. Конечно, мы подтверждаем аутентичность.
Но и поднимать паруса опять перестали бояться. Даже те, кто раньше был на лицензиях.
Кризис происходит и в Европе
И это вызывает несколько очень смешных следствий. Вот, например, есть такая компания Cogent. Они долго нас атаковали предложениями о сотрудничестве и в начале 2022 года мы хотели входить с ними в партнёрство, а потом в районе марта они взяли и без предупреждения вырубили все российские серверы: просто выключили — и всё! Там были высказывания вроде «Мы не работаем с русскими» и так далее.
Этим летом от них приходит спам типа давайте к нам. Мы посмеялись, мол, с таким таргетом — удачи!
И вот буквально в начале осени звонит телефон:
— Мы Cogent!
— Хорошо. Вы знаете, что мы русские? Идите на …! Зачем вы тратите наше и ваше время?
— Ну погодите, не спешите. Мы тут вернулись в Россию, можно платить на российское юрлицо, вернитесь, мы всё простим! Всё равно хотим работать, давайте поговорим.
Есть другой пример в это же время, когда довольно старый партнёр, который не принимал от нас платежей, а для возможности как-то продолжать работу с ним приходилось всякий раз изобретать способ оплаты, в итоге открыл юрлицо в России и сам прислал письмо, что они рады снова работать напрямую, а для удобства оплаты — вот русское лицо со счётом. То есть вот эти засранцы, кто нас так сильно не мог терпеть и выключал серверы, просто поняли, что без наших денег им грустно. Открыли какое-то ООО, соблюдают законодательство и говорят: «Идите к нам». Про разные интересные моменты говорят: «Нет, сейчас всё поменялось».
Ну, конечно, фразу я им договорил. Разборчиво и чётко. И они — не единственные.
Вообще раньше глобализация была из-за ПО. Очень многих объединяли винда, тот же Linux. А сейчас NIX — у всех свой: китайцев послали, русских послали — теперь не удивляйтесь сюрпризам. Теперь от глобальных решений отворачиваются уже многие, а это только начало пути. Многие в России тоже заявляют, что хотят сделать свои архитектуры виртуализации (!). Это всё вроде хорошо. Но, с другой стороны, лично я недоумеваю, насколько будет возможным всё это со временем администрировать. Представьте, что у вас — Чебурашка v1.0b, а вам искать команду админов. Мне хотелось бы, чтобы у нас был свой софт, но не ценой всего.
Информационная безопасность в ж…
Чем больше разных стандартов, тем меньше они аудируются людьми и пользователями. И, соответственно, больше будет уязвимости. Это минус и самопального ПО.
С другой стороны, зоопарки ПО означают историю Неуловимого Джо, когда мотивация ломать неглобальное решение ниже.
Весь год идут огромные кибератаки, которые фиксируют провайдеры, и активность снова резко выросла в октябре. Речь идёт про атаки на сетевую инфраструктуру, в частности, маршрутизаторы. У кого-то это привело к большим простоям.
Тренд в безопасности такой, что никому ничего не надо доверять. Оптимально — самописные решения, если у вас есть нормальная команда их написать. Как показала практика, крупные фреймворки и даже крупный опенсорс могут оказаться с дыркой (или бекдором) в любой момент. Опять же конкурентам нужно будет как-то договариваться между собой, чтобы противодействовать угрозам.
И напоследок
Некоторые боялись проблем с трансграничной связностью. Пока я их не видел. Понятно, что тренд идёт на борьбу с обходами блокировок. Если что-то случится, то это будет очень постепенно и плавно. Минцифры, кажется, реально обеспокоено ростом компьютерной грамотности благодаря действиям РКН. Сейчас VPN поставили даже те, кто их не ставил никогда, просто не зная, что это и зачем. Блокировка Ютуба подтолкнула людей не к российским платформам (это моё личное субъективное оценочное суждение), а к мобильным операторам (где «оборудование Гугла» не так тормозило) и к установке VPN на домашние роутеры. Я такое видел даже у дремучих пенсионеров, чему удивился невероятно! В общем, похоже, немного переборщили. Понятно, что государству необходимо контролировать медиа. Но для Интернета нужны огромные инвестиции в платформу. Это не вопрос коммерческой компании — это вопрос непосредственно госпроекта. Китай такое затащил. Ну, кстати, может и нам затащит, если не повезёт.
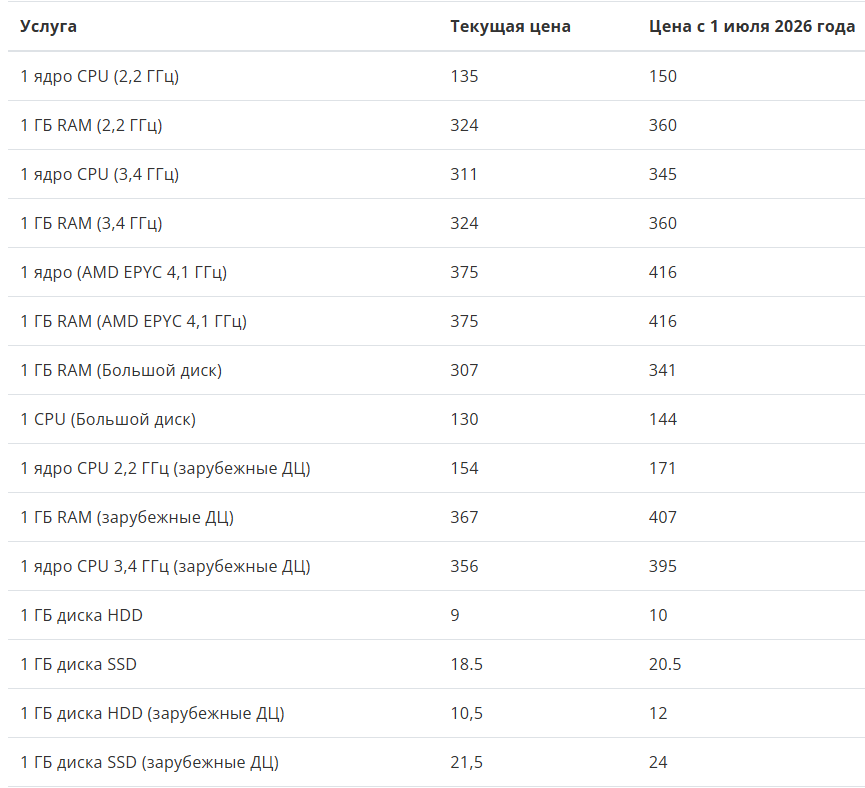
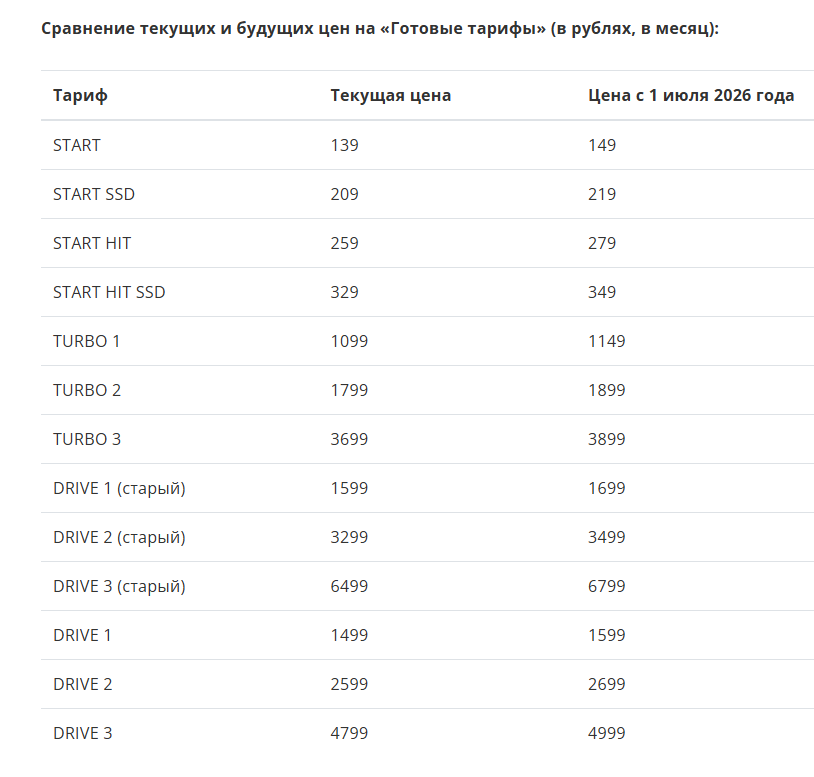
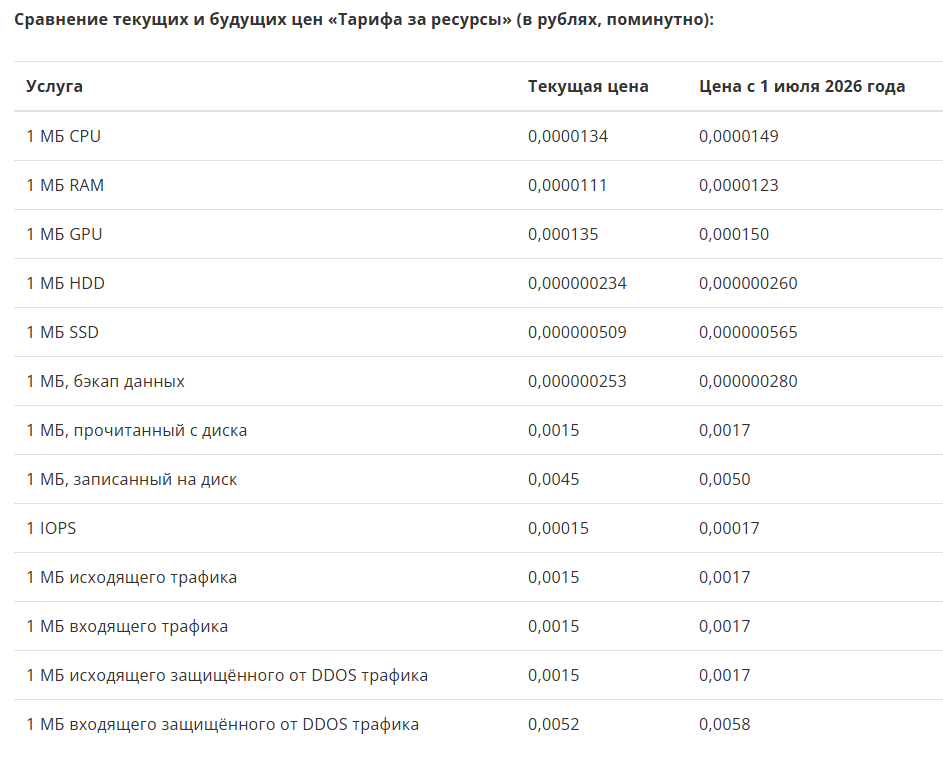
Ещё из анонсов: как я говорил, два года мы не повышали цен, и пора подняться примерно на 10 %. Опять хотим запускать спутник (новый, на этот раз, надеюсь, он будет летать в рабочем состоянии) и там дадим доступ к Powershell’у его борткомпьютера. Без прямой возможности его ушатать, конечно, но поиграть будет можно.
В общем, удачного вам нового года!