Проверка идеи для стартапа: только рабочие методики

В прошлом материале в нашем блоге мы рассмотрели основные способы генерации идей для стартапов. Но теория без практики — ничто! В этой статье мы расскажем, как правильно проверить вашу гениальную и уникальную идею на жизнеспособность.
Прежде всего, задайте себе вопрос: «Что перестанут (или, наоборот, начнут) делать люди благодаря вашему продукту или услуге?» Насколько изменится их поведение и от чего они откажутся? Если эффект получается значительным — это хорошо. Если оказалось, что ничего нового, удобного, дешёвого или более качественного ваш продукт не даёт, а просто он вам нравится, круто выглядит, но повторяет уже имеющееся решение, стоит подумать ещё. Чтобы вовремя это понять, попробуйте подставить вашу идею в следующую формулу:
1. [Такие-то люди или компании] сейчас тратят деньги на [статья расходов].
2. Наш главный конкурент — [компания, продукты которой используют чаще всего].
3. Мы заменим главного конкурента за счёт того, что будем лучше по [важному для потребителя параметру в этой статье расходов].
4. Мы добьёмся этого за счёт того, что [делаем вот это по-другому, не как они].
Если идея вписывается в эту формулировку, у неё есть шанс закрепиться. Приступайте к полевым испытаниям, чтобы проверить, насколько ваш «Франкенштейн» жизнеспособен. Для этого придётся инициировать первые контакты клиента с продуктом, чтобы понять, нужен он кому-то или обречён на провал.
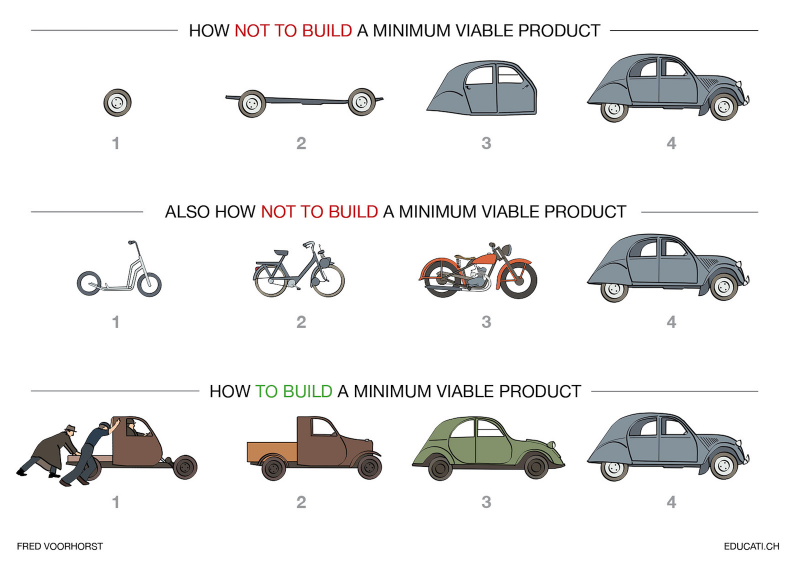
Даже если есть ресурсы, не стоит сразу браться за создания финальной версии продукта. Нельзя действовать по принципу «выпустим, а покупатель найдётся». Всегда логичнее создавать то, в чём есть потребность. Для этого логичнее выпустить MVP.
MVP — Minimal Viable Product — минимально жизнеспособный продукт. По сути, прототип финального изобретения, но с минимальным количеством функций, достаточным, чтобы проверить востребованность среди покупателей. Это важный и обязательный этап, но нельзя приступать к нему без минимального анализа рынка. Так вы рискуете сделать прототип, который будет удовлетворять потребности разработчиков, а не потребителей.
Провести опрос
Самый простой, но не самый достоверный вариант. Особенно, если опрос проводится среди знакомых ближнего круга. На этой стадии интервьюеры часто допускают одну и ту же ошибку: готовят закрытые вопросы, давая респондентам варианты ответов, а не слушая об их опыте использования продукта. Почему все так любят закрытые вопросы? Потому что закрытый вопрос — результат нашего домысливания. Он просто ближе к нашему мнению, которое мы подсознательно проецируем на оппонента. Это плохо. Вопрос должен быть открытым.
Какой вопрос считается открытым? Тот, на который нельзя дать односложный ответ. К которому нельзя подстроиться, а надо аргументировать, формулировать собственное видение проблемы. Открытые вопросы начинаются со слов: «почему», «как», «что», «опишите», «расскажите».
Частный случай беседы с открытыми вопросами — стратегия «пяти „почему“». Главная задача этой техники — выяснить первопричины, понять, почему вашему потенциальному клиенту не нравится товар и правильно отработать возражения. Для этого последовательно задаются 5 вопросов:
1. — Почему вам не нравится игра?
— Она сложная.
2. — Почему вы посчитали её сложной?
— Не смог пройти уровень.
3. — Почему вы не смогли пройти уровень?
— Не хватило жизней.
4. — Почему не хватило жизней?
— Не смог купить достаточно таблеток.
5. — Почему не смогли купить?
— Потому что слишком долго собирать золото.
Простой вывод: игроки отказываются от игры, потому что она слишком монотонная на предыдущем уровне, а не потому что сложная на следующем.
Создать фейковый лендинг

Landing Page — посадочная страница, которая сосредоточена вокруг целевого предложения для определённой аудитории. Она описывает продукт или услугу, объясняет преимущества и, что главное, обязательно содержит CTA-кнопку: купить, заказать, записаться на тест, оставить данные, получить бесплатную консультацию. Но продукта пока нет, поэтому лендинг будет, по сути, ненастоящим. Делаем лендинг по проверенной схеме, а потом смотрим, насколько предложение интересно, как часто люди кликают по CTA-элементам.
Регистрируем домен. Придумываем или заказываем текст-описание, делаем яркие фотографии продукта, расставляем заметные CTA-кнопки и формы захвата. Подключаем аналитику, настраиваем рекламу и анализируем активность на странице. Проводим А/В тестирование.
Иногда стратегия фейкового лендинга преподносится как smoke-тестирование. Главное — разработать минимально жизнеспособное предложение и узнать реакцию на него клиента на реальном трафике. Если есть база подписчиков, вместо лендинга можно использовать email-рассылку.
Провести спринт-разработку

Метод отлично подходит тем, кто медленно запрягает и потом ещё медленнее едет. Его используют для тестирования своих продуктов в Google и Slack. Основной принцип — имитировать скорый дедлайн и заставить мозги работать на 100%. Спринт — это 5 рабочих дней, когда ваша команда должна успеть выбрать решение, сделать прототип и получить обратную связь от клиентов. Для этого в команду обычно включают распорядителя, специалистов по финансам и логистике, инженеров, дизайнеров.
В понедельник выбираем долгосрочную цель. Для этого отвечаем на вопросы, почему мы вообще взялись за проект и где хотим оказаться через полгода-год. Поставленную цель записываем на доске. Далее слева на доске пишем группы клиентов, а справа — конечную цель (покупка продукта, подписка, регистрация). Между ними стрелками обозначаем все взаимодействия.
Понимание того, как клиент взаимодействует с продуктом, рождает вопросы, как эти стадии можно улучшить. Чем их больше, тем лучше. В конце понедельника вам надо выбрать одного целевого клиента и целевое событие, которое требуется прокачать. Над ними и будет вестись работа.
Вторник начинается с поиска решений для выбранного события. В идеале нарисовать скетчи — три стадии взаимодействия с продуктом по каждому решению.
В среду утром голосуем за лучшую идею, начинаем подбирать респондентов для пятничного теста. К вечеру должен быть готов сториборд — 10−15 кадров. Первый — момент, когда человек впервые видит рекламу, лендинг, иконку в AppStore.
В четверг отрисованный сториборд превращается в быстрый прототип. Не пытайтесь создать реальный продукт, ограничьтесь фасадом. Используйте Marvel, InVision, Keynote или PowerPoint, чтобы отобразить все стадии работы от первого и до последнего экрана.
В пятницу интервьюер работает с целевой аудиторией, а команда отмечает для себя, как реагируют респонденты, всё ли им понятно, правильно ли в начале спринта определили проблему.
Что нужно запомнить
- Не пытайтесь совсем уйти от конкуренции. Где нет конкуренции, там, скорее всего, нет денег
- Придумывая идею, анализируйте уже сформированные потребности людей. Посмотрите, как их можно удовлетворить быстрее, удобнее или дешевле.
- Не повторяйте то, что уже есть на рынке.
- Используйте для мозгового штурма проверенные алгоритмы («6 шляп мышления», матрица стартапов, ТРИЗ).
- Всегда проверяйте минимальную эффективность решения, прежде чем запустить его в производство.
⌘⌘⌘
Помните, что вас окружают идеи и возможности. Важно только уметь найти их и воплотить в жизнь. Расширяйте свой кругозор, общайтесь с интересными людьми, читайте книги, путешествуйте, и тогда вы обязательно найдёте идею, которая станет делом вашей жизни!
www.reg.ru