Сегодня мы запускаем наш новейший регион Google Cloud Platform в Солт-Лейк-Сити, в результате чего третий регион в западной части Соединенных Штатов, шестой в национальном масштабе, и наш глобальный общий показатель — 22.
 Область для Кремниевых Склонов
Область для Кремниевых Склонов
Силиконовые склоны Юты являются домом для многих компаний, обладающих цифровыми знаниями. Теперь открытый для клиентов Google Cloud регион
Солт-Лейк-Сити (us-west3) предоставляет вам скорость и доступность, необходимые для быстрого внедрения инноваций, создания высокопроизводительных приложений и наилучшего обслуживания местных клиентов. Кроме того, этот регион дает вам дополнительную гибкость в распределении ваших рабочих нагрузок по всей западной части США, включая наши существующие облачные регионы в Лос-Анджелесе и Орегоне.
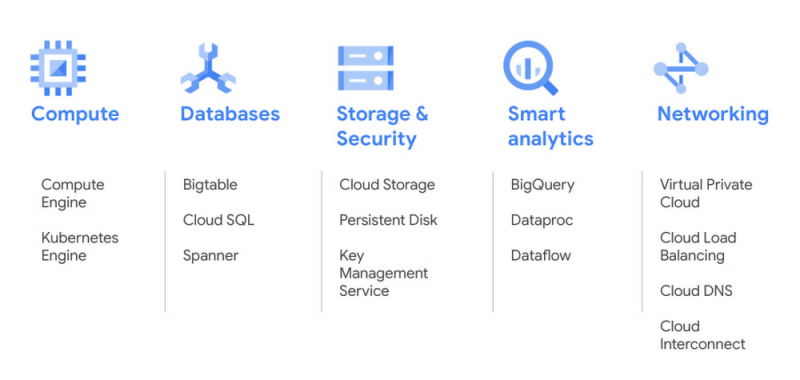
Регион Солт-Лейк-Сити предлагает немедленный доступ к трем зонам для рабочих нагрузок высокой доступности и нашему стандартному набору продуктов, включая Compute Engine, Kubernetes Engine, Bigtable, Spanner и BigQuery. Наша частная магистраль быстро и надежно соединяет Солт-Лейк-Сити с нашей глобальной сетью. Кроме того, вы можете интегрировать локальные рабочие нагрузки с нашим новым регионом, используя Cloud Interconnect. Это означает, что клиенты из Солт-Лейк-Сити могут расширяться по всему миру от своих дверей, а те, кто находится за пределами региона, могут легко добраться до своих пользователей на западе горы.
 Что говорят клиенты
Что говорят клиенты
Отрасли, включая здравоохранение, финансовые услуги и ИТ, инвестируют в Солт-Лейк-Сити. Организации по всем этим направлениям обратились к облаку Google, чтобы быстрее внедрять инновации и помогать решать самые сложные задачи.
PayPal, ведущая технологическая платформа и компания, занимающаяся цифровыми платежами, переносит ключевые части своей платежной инфраструктуры в новый регион. Подробнее о путешествии PayPal с Google Cloud читайте в сегодняшнем пресс-релизе.
Overstock, 20-летняя технологическая компания, предоставляющая лучшие в своем классе возможности для розничных клиентов, была в технологическом пространстве задолго до того, как облачные среды предприятий стали реальностью.
Наша доморощенная инфраструктура была построена в предоблачном мире и нуждалась в обновлении. При поиске партнера по облачным вычислениям мы руководствовались определенным набором критериев, учитывая нашу отрасль и глобальную клиентскую базу. Мы смогли сохранить производительность всего сайта при обновлении наших устаревших систем до гибридного пользовательского публичного / частного облака с системами Google. В этом новом регионе мы ожидаем достижения большей доступности, меньшей задержки, большей непрерывности бизнеса и улучшения качества наших услуг в будущем
сказал Джоэл Вес, технический директор Overstock.
Рекурсия, компания в области цифровой биологии, базирующаяся в Солт-Лейк-Сити и специализирующаяся на индустриализации поиска лекарств, выбрала Google Cloud в качестве основного поставщика общедоступного облака, поскольку она создает платформу для обнаружения лекарств, которая может сократить время на поиск и разработку нового лекарства путем коэффициент 10.
Продолжающиеся инвестиции Google Cloud в этот регион являются четким показателем того, что Солт-Лейк-Сити является силой, которую следует считать влиятельным техническим центром. В новом облачном регионе такие компании, как наша, имеют доступ к более быстрой и масштабируемой вычислительной инфраструктуре для лучшего обслуживания своих клиентов. Мы с нетерпением ждем возможностей, которые появятся в будущем в сотрудничестве с Google
сказал Бен Мейби, технический директор Recursion
StorageCraft, поставщик защиты и восстановления данных со штаб-квартирой в Дрейпере, штат Юта, развернет Google Cloud для поддержки роста бизнеса и обеспечения будущего портфеля облачных услуг для защиты и восстановления данных.
Облачные решения StorageCraft — это центральная часть нашей линейки продуктов и стратегии роста. По мере расширения нашего бизнеса мы будем продолжать внедрять технологии, которые оптимизируют производительность наших решений на благо наших партнеров и наших клиентов. Сотрудничество с Google Cloud близко к Наша штаб-квартира поможет нам легко масштабировать возможности наших предложений с помощью высокопроизводительных облачных сервисов. Это критическое требование партнеров и клиентов, которые полагаются на решения StorageCraft, чтобы всегда сохранять свои данные безопасными, доступными и оптимизированными
сказал Джавад. Тарик, вице-президент по проектированию, StorageCraft.
Что дальше
Мы рады приветствовать вас в нашем новом облачном регионе в Солт-Лейк-Сити и с нетерпением ждем того, что вы создадите на нашей платформе. Следите за новостями региона и выпусками в этом году, начиная с нашего
следующего региона США в Лас-Вегасе. Для получения дополнительной информации свяжитесь с отделом продаж, чтобы начать работу с Google Cloud сегодня.