Prescience: Представляем платформу машинного обучения OVH
Проекты машинного обучения становятся все более важной составляющей сегодняшнего поиска более эффективных и сложных производственных процессов. OVH Prescience — это платформа для машинного обучения, цель которой — облегчить концепцию, развертывание и обслуживание моделей в промышленном контексте. Система управляет конвейерами машинного обучения, от приема данных до мониторинга моделей. Это включает в себя автоматизацию предварительной обработки данных, выбор модели, оценку и развертывание в масштабируемой платформе.
Prescience поддерживает различные виды проблем, такие как регрессия, классификация, прогнозирование временных рядов и вскоре обнаружение аномалий. Решение проблем осуществляется с использованием как традиционных моделей ML, так и нейронных сетей.
Prescience в настоящее время используется в производственных масштабах для решения различных задач, с которыми сталкивается OVH, а его альфа-версия доступна для бесплатной проверки в OVH Labs. В этом сообщении мы представим Prescience и познакомим вас с типичным рабочим процессом вместе с его компонентами. Подробная презентация компонентов будет доступна в следующих публикациях в блоге.
Начало Prescience
В какой-то момент все проекты машинного обучения сталкиваются с одной и той же проблемой: как преодолеть разрыв между прототипом системы машинного обучения и ее использованием в производственном контексте. Это было краеугольным камнем развития платформы машинного обучения в OVH.
Производственные тетради
Чаще всего ученые-разработчики проектируют системы машинного обучения, которые включают обработку данных и выбор моделей в ноутбуках. Если они успешны, эти ноутбуки затем адаптируются для производственных нужд инженерами данных или разработчиками. Этот процесс обычно деликатный. Это отнимает много времени и должно повторяться каждый раз, когда модель или обработка данных требуют обновления. Эти проблемы приводят к серийным моделям, которые, хотя и являются идеальными при поставке, могут со временем сойти с реальной проблемы. На практике модели никогда не используются в производственном режиме, несмотря на их качество, только потому, что конвейер данных слишком сложен (или скучен), чтобы его можно было извлечь из ноутбука. В результате вся работа ученых-данных идет напрасно.
В свете этого первая проблема, которую Prescience необходимо было решить, заключалась в том, как обеспечить простой способ развертывания и обслуживания моделей при одновременном обеспечении мониторинга и эффективного управления моделями, включая (но не ограничиваясь этим) переподготовку моделей, оценку моделей или запрос моделей через обслуживающий REST API.
Улучшенное прототипирование
После того, как разрыв между прототипированием и производством был преодолен, второй целью было сокращение фазы прототипирования проектов машинного обучения. Базовое наблюдение состоит в том, что навыки ученых данных являются наиболее важными при применении к подготовке данных или разработке функций. По сути, задача исследователя данных состоит в том, чтобы правильно определить проблему. Это включает характеристику данных, фактическую цель и правильную метрику для оценки. Тем не менее, выбор модели — также задача, решаемая специалистом по данным — та, которая приносит гораздо меньше пользы от этого специалиста. Действительно, один из классических способов найти хорошую модель и ее параметры по-прежнему состоит в том, чтобы перебрать все возможные конфигурации в данном пространстве. В результате выбор модели может быть довольно кропотливым и трудоемким.
Следовательно, Prescience необходимо было предоставить ученым, работающим с данными, эффективный способ тестирования и оценки алгоритмов, которые позволили бы им сосредоточиться на повышении ценности данных и определении проблем. Это было достигнуто путем добавления компонента оптимизации, который, учитывая пространство конфигурации, оценивает и тестирует конфигурации внутри него, независимо от того, были ли они подобраны специалистом по данным. Поскольку архитектура масштабируема, мы можем быстро протестировать значительное количество возможностей таким образом. Компонент оптимизации также использует методы, чтобы попытаться превзойти подход грубой силы, используя байесовскую оптимизацию. Кроме того, проверенные конфигурации для данной проблемы сохраняются для последующего использования и для облегчения запуска процесса оптимизации.
Расширяя возможности
В такой компании, как OVH, много проблем можно решить с помощью методов машинного обучения. К сожалению, по каждому из этих вопросов невозможно назначить ученого, особенно если не установлено, стоит ли инвестировать. Несмотря на то, что наши специалисты по бизнесу не освоили все методы машинного обучения, они обладают обширными знаниями о данных. Опираясь на эти знания, они могут дать нам минимальное определение проблемы под рукой. Автоматизация предыдущих этапов (подготовка данных и выбор модели) позволяет специалистам быстро оценить возможные преимущества подхода машинного обучения. Тогда можно принять процесс быстрого выигрыша / быстрого отказа для потенциальных проектов. Если это удастся, мы можем, если необходимо, ввести в цикл исследователя данных.
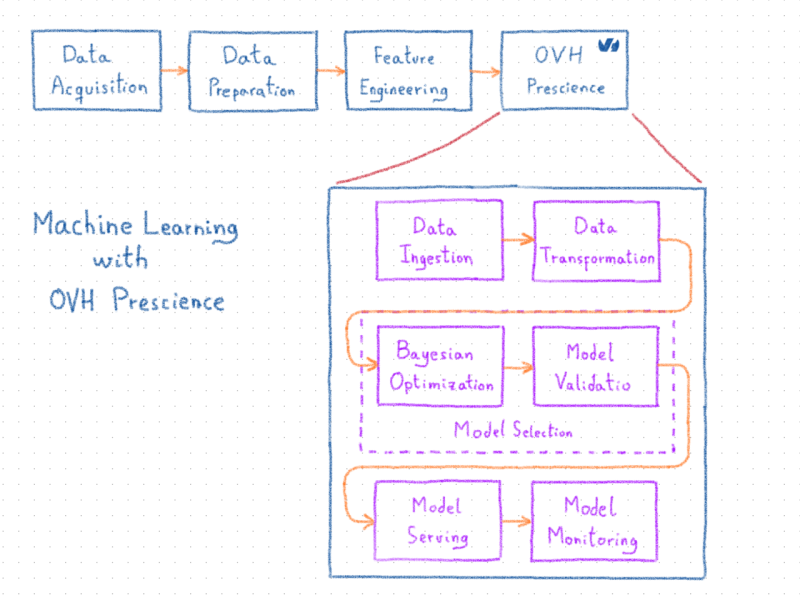
Prescience также включает в себя автоматическое управление конвейером, чтобы адаптировать необработанные данные, которые будут использоваться алгоритмами машинного обучения (то есть, предварительную обработку), затем выбрать подходящий алгоритм и его параметры (то есть выбор модели), сохраняя при этом автоматическое развертывание и мониторинг.
Архитектура Prescience и рабочие процессы машинного обучения
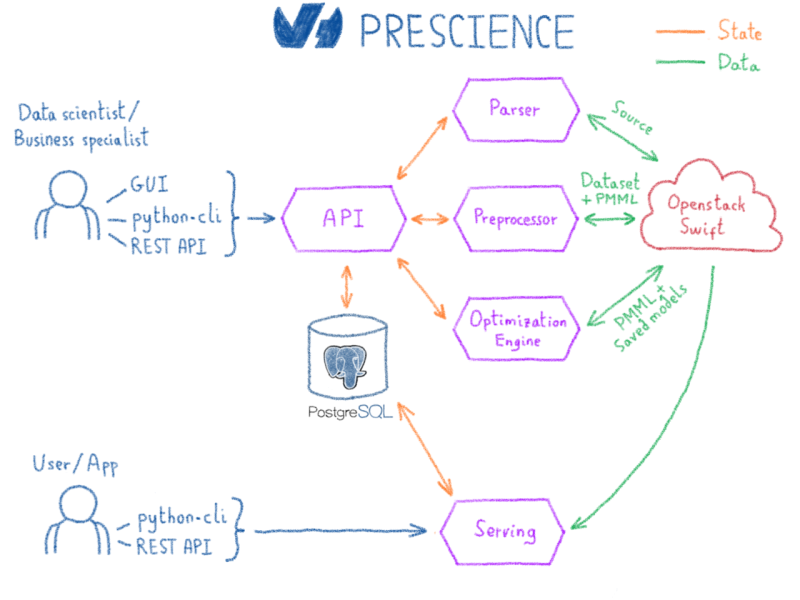
По сути, платформа Prescience основана на технологиях с открытым исходным кодом, таких как Kubernetes для операций, Spark для обработки данных и Scikit-learn, XGBoost, Spark MLlib и Tensorflow для машинного обучения. Большая часть разработок Prescience заключалась в объединении этих технологий. Кроме того, все промежуточные выходы системы, такие как предварительно обработанные данные, этапы преобразования или модели, сериализуются с использованием технологий и стандартов с открытым исходным кодом. Это предотвращает привязку пользователей к Prescience в случае необходимости использования другой системы.
Взаимодействие пользователей с платформой Prescience стало возможным благодаря следующим элементам:
Прием данных
Первый шаг рабочего процесса машинного обучения — получение пользовательских данных. В настоящее время мы поддерживаем три типа источников, которые затем будут расширены в зависимости от использования:
CSV, отраслевой стандарт
Паркет, который довольно крутой (плюс автоматически документированный и сжатый)
Временной ряд, благодаря OVH Observability, работает на Warp10
Необработанные данные, предоставляемые каждым из этих источников, редко используются как есть в алгоритмах машинного обучения. Алгоритмы обычно ожидают, что числа будут работать. Поэтому первый шаг рабочего процесса выполняется компонентом Parser. Единственная задача Parser — обнаруживать типы и имена столбцов, в случае простых текстовых форматов, таких как CSV, хотя источники Parquet и Warp10 содержат схему, что делает этот шаг спорным. После ввода данных анализатор извлекает статистику, чтобы точно ее охарактеризовать. Полученные данные вместе со статистикой хранятся в нашей серверной памяти хранилища — Public Cloud Storage, работающей на OpenStack Swift.
Преобразование данных
После того, как типы выведены и статистика извлечена, данные, как правило, должны быть обработаны, прежде чем они будут готовы к машинному обучению. Этот шаг обрабатывается препроцессором. Опираясь на вычисленную статистику и тип проблемы, он определяет лучшую стратегию для применения к источнику. Например, если у нас есть одна категория, то выполняется горячее кодирование. Однако, если у нас есть большое количество различных категорий, то выбирается более подходящий тип обработки, такой как кодирование уровня / воздействия. После вывода стратегия применяется к источнику, превращая его в набор данных, который станет основой для последующего шага выбора модели.
Препроцессор выводит не только набор данных, но и сериализованную версию преобразований. Выбранный формат для сериализации — PMML (язык разметки прогнозной модели). Это стандарт описания для совместного использования алгоритмов интеллектуального анализа данных и машинного обучения. Используя этот формат, мы сможем применить точно такое же преобразование во время обслуживания, когда столкнемся с новыми данными.
Выбор модели
Как только набор данных будет готов, следующим шагом будет попытка подобрать лучшую модель. В зависимости от проблемы пользователю предоставляется набор алгоритмов вместе с их конфигурационным пространством. В зависимости от уровня квалификации пользователь может настроить пространство конфигурации и предварительно выбрать подмножество алгоритмов, которые лучше всего подходят для данной проблемы.
Байесовская оптимизация
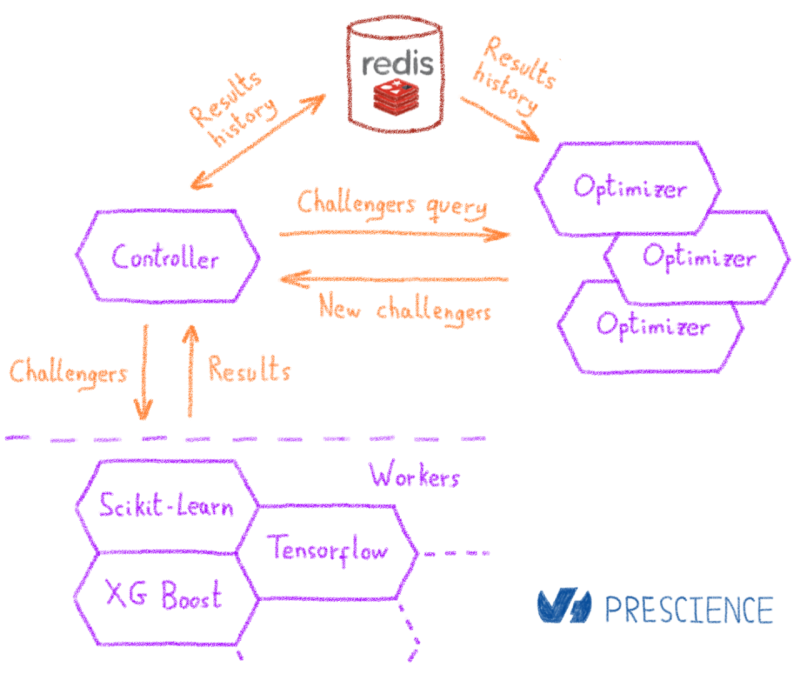
Компонент, который выполняет оптимизацию и выбор модели, является механизмом оптимизации. При запуске оптимизации подкомпонент, называемый контроллером, создает внутреннюю задачу оптимизации. Контроллер управляет планированием различных шагов оптимизации, выполняемых во время задачи. Оптимизация достигается с помощью байесовских методов. По сути, байесовский подход заключается в изучении модели, которая сможет предсказать, какая конфигурация является наилучшей. Мы можем разбить шаги следующим образом:
Проверка модели
Как только оптимизация завершена, пользователь может либо запустить новую оптимизацию, используя существующие данные (следовательно, не возвращаясь в холодное состояние), либо выбрать конфигурацию в соответствии с ее оценочными показателями. Как только подходящая конфигурация достигнута, она используется для обучения окончательной модели, которая затем сериализуется либо в формате PMML, либо в формате сохраненной модели Tensorflow. Те же ученики, которые занимались оценками, проводят фактическое обучение.
В конце концов, окончательная модель оценивается по тестовому набору, извлеченному во время предварительной обработки. Этот набор никогда не используется во время выбора модели или обучения, чтобы обеспечить беспристрастность вычисленных показателей оценки. На основе полученных показателей оценки может быть принято решение использовать модель в производстве или нет.
Модель сервировки
На этом этапе модель обучается и экспортируется и готова к обслуживанию. Последний компонент платформы Prescience — это обслуживание Prescience. Это веб-сервис, который использует PMML и сохраненные модели и предоставляет REST API поверх. Поскольку преобразования экспортируются вместе с моделью, пользователь может запросить вновь развернутую модель, используя необработанные данные. Прогнозы теперь готовы к использованию в любом приложении.
Модельный мониторинг
Кроме того, одной из характерных особенностей машинного обучения является его способность адаптироваться к новым данным. В отличие от традиционных жестко заданных бизнес-правил, модель машинного обучения способна адаптироваться к базовым шаблонам. Для этого платформа Prescience позволяет пользователям легко обновлять источники, обновлять наборы данных и переучивать модели. Эти шаги жизненного цикла помогают поддерживать актуальность модели в отношении проблемы, которую необходимо решить. Затем пользователь может сопоставить частоту переподготовки с новой квалификацией данных. Они могут даже прервать процесс обучения в случае аномалии в конвейере генерации данных. Каждый раз, когда модель переобучается, вычисляется новый набор баллов и сохраняется в OVH Observability для мониторинга.
Как мы отмечали в начале этого поста, наличие точной модели не дает никаких гарантий относительно ее способности поддерживать эту точность с течением времени. По многим причинам производительность модели может снизиться. Например, необработанные данные могут ухудшиться в качестве, могут появиться некоторые аномалии в конвейерах обработки данных или сама проблема может дрейфовать, делая текущую модель неактуальной, даже после переподготовки. Поэтому крайне важно постоянно отслеживать производительность модели на протяжении всего жизненного цикла, чтобы избежать принятия решений на основе устаревшей модели.
Движение к ИИ-управляемой компании
Prescience в настоящее время используется в OVH для решения ряда промышленных проблем, таких как предотвращение мошенничества и профилактическое обслуживание в центрах обработки данных.
С помощью этой платформы мы планируем наделить все большее число команд и служб в OVH возможностью оптимизировать свои процессы с помощью машинного обучения. Мы особенно рады нашей работе с Временными рядами, которые играют решающую роль в управлении и мониторинге сотен тысяч серверов и виртуальных машин.
Разработка Prescience проводится командой служб машинного обучения. MLS состоит из четырех инженеров машинного обучения: Маэль, Адриен, Рафаэль и я. Командой руководит Гийом, который помог мне спроектировать платформу. Кроме того, в команду входят два исследователя данных, Оливье и Клемент, которые занимались внутренними случаями использования и предоставили нам обратную связь, и, наконец, Лоран: студент CIFRE, работающий над многоцелевой оптикой.
Prescience поддерживает различные виды проблем, такие как регрессия, классификация, прогнозирование временных рядов и вскоре обнаружение аномалий. Решение проблем осуществляется с использованием как традиционных моделей ML, так и нейронных сетей.
Prescience в настоящее время используется в производственных масштабах для решения различных задач, с которыми сталкивается OVH, а его альфа-версия доступна для бесплатной проверки в OVH Labs. В этом сообщении мы представим Prescience и познакомим вас с типичным рабочим процессом вместе с его компонентами. Подробная презентация компонентов будет доступна в следующих публикациях в блоге.
Начало Prescience
В какой-то момент все проекты машинного обучения сталкиваются с одной и той же проблемой: как преодолеть разрыв между прототипом системы машинного обучения и ее использованием в производственном контексте. Это было краеугольным камнем развития платформы машинного обучения в OVH.
Производственные тетради
Чаще всего ученые-разработчики проектируют системы машинного обучения, которые включают обработку данных и выбор моделей в ноутбуках. Если они успешны, эти ноутбуки затем адаптируются для производственных нужд инженерами данных или разработчиками. Этот процесс обычно деликатный. Это отнимает много времени и должно повторяться каждый раз, когда модель или обработка данных требуют обновления. Эти проблемы приводят к серийным моделям, которые, хотя и являются идеальными при поставке, могут со временем сойти с реальной проблемы. На практике модели никогда не используются в производственном режиме, несмотря на их качество, только потому, что конвейер данных слишком сложен (или скучен), чтобы его можно было извлечь из ноутбука. В результате вся работа ученых-данных идет напрасно.
В свете этого первая проблема, которую Prescience необходимо было решить, заключалась в том, как обеспечить простой способ развертывания и обслуживания моделей при одновременном обеспечении мониторинга и эффективного управления моделями, включая (но не ограничиваясь этим) переподготовку моделей, оценку моделей или запрос моделей через обслуживающий REST API.
Улучшенное прототипирование
После того, как разрыв между прототипированием и производством был преодолен, второй целью было сокращение фазы прототипирования проектов машинного обучения. Базовое наблюдение состоит в том, что навыки ученых данных являются наиболее важными при применении к подготовке данных или разработке функций. По сути, задача исследователя данных состоит в том, чтобы правильно определить проблему. Это включает характеристику данных, фактическую цель и правильную метрику для оценки. Тем не менее, выбор модели — также задача, решаемая специалистом по данным — та, которая приносит гораздо меньше пользы от этого специалиста. Действительно, один из классических способов найти хорошую модель и ее параметры по-прежнему состоит в том, чтобы перебрать все возможные конфигурации в данном пространстве. В результате выбор модели может быть довольно кропотливым и трудоемким.
Следовательно, Prescience необходимо было предоставить ученым, работающим с данными, эффективный способ тестирования и оценки алгоритмов, которые позволили бы им сосредоточиться на повышении ценности данных и определении проблем. Это было достигнуто путем добавления компонента оптимизации, который, учитывая пространство конфигурации, оценивает и тестирует конфигурации внутри него, независимо от того, были ли они подобраны специалистом по данным. Поскольку архитектура масштабируема, мы можем быстро протестировать значительное количество возможностей таким образом. Компонент оптимизации также использует методы, чтобы попытаться превзойти подход грубой силы, используя байесовскую оптимизацию. Кроме того, проверенные конфигурации для данной проблемы сохраняются для последующего использования и для облегчения запуска процесса оптимизации.
Расширяя возможности
В такой компании, как OVH, много проблем можно решить с помощью методов машинного обучения. К сожалению, по каждому из этих вопросов невозможно назначить ученого, особенно если не установлено, стоит ли инвестировать. Несмотря на то, что наши специалисты по бизнесу не освоили все методы машинного обучения, они обладают обширными знаниями о данных. Опираясь на эти знания, они могут дать нам минимальное определение проблемы под рукой. Автоматизация предыдущих этапов (подготовка данных и выбор модели) позволяет специалистам быстро оценить возможные преимущества подхода машинного обучения. Тогда можно принять процесс быстрого выигрыша / быстрого отказа для потенциальных проектов. Если это удастся, мы можем, если необходимо, ввести в цикл исследователя данных.
Prescience также включает в себя автоматическое управление конвейером, чтобы адаптировать необработанные данные, которые будут использоваться алгоритмами машинного обучения (то есть, предварительную обработку), затем выбрать подходящий алгоритм и его параметры (то есть выбор модели), сохраняя при этом автоматическое развертывание и мониторинг.
Архитектура Prescience и рабочие процессы машинного обучения
По сути, платформа Prescience основана на технологиях с открытым исходным кодом, таких как Kubernetes для операций, Spark для обработки данных и Scikit-learn, XGBoost, Spark MLlib и Tensorflow для машинного обучения. Большая часть разработок Prescience заключалась в объединении этих технологий. Кроме того, все промежуточные выходы системы, такие как предварительно обработанные данные, этапы преобразования или модели, сериализуются с использованием технологий и стандартов с открытым исходным кодом. Это предотвращает привязку пользователей к Prescience в случае необходимости использования другой системы.
Взаимодействие пользователей с платформой Prescience стало возможным благодаря следующим элементам:
- пользовательский интерфейс
- клиент Python
- REST API
Прием данных
Первый шаг рабочего процесса машинного обучения — получение пользовательских данных. В настоящее время мы поддерживаем три типа источников, которые затем будут расширены в зависимости от использования:
CSV, отраслевой стандарт
Паркет, который довольно крутой (плюс автоматически документированный и сжатый)
Временной ряд, благодаря OVH Observability, работает на Warp10
Необработанные данные, предоставляемые каждым из этих источников, редко используются как есть в алгоритмах машинного обучения. Алгоритмы обычно ожидают, что числа будут работать. Поэтому первый шаг рабочего процесса выполняется компонентом Parser. Единственная задача Parser — обнаруживать типы и имена столбцов, в случае простых текстовых форматов, таких как CSV, хотя источники Parquet и Warp10 содержат схему, что делает этот шаг спорным. После ввода данных анализатор извлекает статистику, чтобы точно ее охарактеризовать. Полученные данные вместе со статистикой хранятся в нашей серверной памяти хранилища — Public Cloud Storage, работающей на OpenStack Swift.
Преобразование данных
После того, как типы выведены и статистика извлечена, данные, как правило, должны быть обработаны, прежде чем они будут готовы к машинному обучению. Этот шаг обрабатывается препроцессором. Опираясь на вычисленную статистику и тип проблемы, он определяет лучшую стратегию для применения к источнику. Например, если у нас есть одна категория, то выполняется горячее кодирование. Однако, если у нас есть большое количество различных категорий, то выбирается более подходящий тип обработки, такой как кодирование уровня / воздействия. После вывода стратегия применяется к источнику, превращая его в набор данных, который станет основой для последующего шага выбора модели.
Препроцессор выводит не только набор данных, но и сериализованную версию преобразований. Выбранный формат для сериализации — PMML (язык разметки прогнозной модели). Это стандарт описания для совместного использования алгоритмов интеллектуального анализа данных и машинного обучения. Используя этот формат, мы сможем применить точно такое же преобразование во время обслуживания, когда столкнемся с новыми данными.
Выбор модели
Как только набор данных будет готов, следующим шагом будет попытка подобрать лучшую модель. В зависимости от проблемы пользователю предоставляется набор алгоритмов вместе с их конфигурационным пространством. В зависимости от уровня квалификации пользователь может настроить пространство конфигурации и предварительно выбрать подмножество алгоритмов, которые лучше всего подходят для данной проблемы.
Байесовская оптимизация
Компонент, который выполняет оптимизацию и выбор модели, является механизмом оптимизации. При запуске оптимизации подкомпонент, называемый контроллером, создает внутреннюю задачу оптимизации. Контроллер управляет планированием различных шагов оптимизации, выполняемых во время задачи. Оптимизация достигается с помощью байесовских методов. По сути, байесовский подход заключается в изучении модели, которая сможет предсказать, какая конфигурация является наилучшей. Мы можем разбить шаги следующим образом:
- Модель в холодном состоянии. Оптимизатор возвращает набор настроек по умолчанию для контроллера
- Контроллер распределяет начальные конфигурации по кластеру учащихся
- По завершении начальных конфигураций контроллер сохраняет результаты
- Оптимизатор запускает вторую итерацию и обучает модель на основе доступных данных.
- На основе полученной модели оптимизатор выводит лучших претендентов, которые можно попробовать. Рассматривается как их потенциальная эффективность, так и объем информации, который она предоставит для улучшения модели выбора.
- Контроллер распределяет новый набор конфигураций по кластеру и ждет новой информации, a.k.a вновь оцененных конфигураций. Конфигурации оцениваются с использованием K-кратной перекрестной проверки, чтобы избежать переоснащения.
- Когда доступна новая информация, запускается новая итерация оптимизации, и процесс начинается снова на шаге 4
- После предварительно определенного числа итераций оптимизация останавливается
Проверка модели
Как только оптимизация завершена, пользователь может либо запустить новую оптимизацию, используя существующие данные (следовательно, не возвращаясь в холодное состояние), либо выбрать конфигурацию в соответствии с ее оценочными показателями. Как только подходящая конфигурация достигнута, она используется для обучения окончательной модели, которая затем сериализуется либо в формате PMML, либо в формате сохраненной модели Tensorflow. Те же ученики, которые занимались оценками, проводят фактическое обучение.
В конце концов, окончательная модель оценивается по тестовому набору, извлеченному во время предварительной обработки. Этот набор никогда не используется во время выбора модели или обучения, чтобы обеспечить беспристрастность вычисленных показателей оценки. На основе полученных показателей оценки может быть принято решение использовать модель в производстве или нет.
Модель сервировки
На этом этапе модель обучается и экспортируется и готова к обслуживанию. Последний компонент платформы Prescience — это обслуживание Prescience. Это веб-сервис, который использует PMML и сохраненные модели и предоставляет REST API поверх. Поскольку преобразования экспортируются вместе с моделью, пользователь может запросить вновь развернутую модель, используя необработанные данные. Прогнозы теперь готовы к использованию в любом приложении.
Модельный мониторинг
Кроме того, одной из характерных особенностей машинного обучения является его способность адаптироваться к новым данным. В отличие от традиционных жестко заданных бизнес-правил, модель машинного обучения способна адаптироваться к базовым шаблонам. Для этого платформа Prescience позволяет пользователям легко обновлять источники, обновлять наборы данных и переучивать модели. Эти шаги жизненного цикла помогают поддерживать актуальность модели в отношении проблемы, которую необходимо решить. Затем пользователь может сопоставить частоту переподготовки с новой квалификацией данных. Они могут даже прервать процесс обучения в случае аномалии в конвейере генерации данных. Каждый раз, когда модель переобучается, вычисляется новый набор баллов и сохраняется в OVH Observability для мониторинга.
Как мы отмечали в начале этого поста, наличие точной модели не дает никаких гарантий относительно ее способности поддерживать эту точность с течением времени. По многим причинам производительность модели может снизиться. Например, необработанные данные могут ухудшиться в качестве, могут появиться некоторые аномалии в конвейерах обработки данных или сама проблема может дрейфовать, делая текущую модель неактуальной, даже после переподготовки. Поэтому крайне важно постоянно отслеживать производительность модели на протяжении всего жизненного цикла, чтобы избежать принятия решений на основе устаревшей модели.
Движение к ИИ-управляемой компании
Prescience в настоящее время используется в OVH для решения ряда промышленных проблем, таких как предотвращение мошенничества и профилактическое обслуживание в центрах обработки данных.
С помощью этой платформы мы планируем наделить все большее число команд и служб в OVH возможностью оптимизировать свои процессы с помощью машинного обучения. Мы особенно рады нашей работе с Временными рядами, которые играют решающую роль в управлении и мониторинге сотен тысяч серверов и виртуальных машин.
Разработка Prescience проводится командой служб машинного обучения. MLS состоит из четырех инженеров машинного обучения: Маэль, Адриен, Рафаэль и я. Командой руководит Гийом, который помог мне спроектировать платформу. Кроме того, в команду входят два исследователя данных, Оливье и Клемент, которые занимались внутренними случаями использования и предоставили нам обратную связь, и, наконец, Лоран: студент CIFRE, работающий над многоцелевой оптикой.
0 комментариев
Вставка изображения
Оставить комментарий