Инфраструктура внутренних баз данных OVHcloud
Сегодня большинство приложений прямо или косвенно полагаются на базы данных. Я бы даже сделал ставку и сказал, что большая часть из них — это реляционные базы данных. В OVHcloud мы опираемся на несколько десятков кластеров, содержащих сотни баз данных, для поддержки тысяч приложений. Большинство из этих баз данных поддерживают наш API, информацию о счете хоста и информацию о клиенте.

Как часть команды, ответственной за эту инфраструктуру, я могу сказать, что это огромная ответственность за поддержание столь важной части бьющегося сердца OVHcloud.
В этой новой серии постов мы рассмотрим инфраструктуру внутренних реляционных баз данных OVHcloud. Этот первый пост посвящен инфраструктуре внутренних баз данных. В OVHcloud мы используем 3 основные СУБД (системы управления базами данных), PostgreSQL MariaDB и MySQL, каждая из которых опирается на одну кластерную архитектуру.
Но сначала, что такое кластер? Кластер — это группа узлов (физических или виртуальных), работающих вместе для предоставления службы SQL.
В OVHcloud у нас есть открытый исходный код и культура «сделай сам». Это позволяет нам контролировать наши расходы и, что более важно, осваивать технологии, на которые мы опираемся.
Вот почему в течение последних двух лет мы проектировали, развертывали, совершенствовали и запускали отказоустойчивые кластерные топологии, а затем внедряли их в промышленную эксплуатацию. Чтобы удовлетворить наши требования к надежности, производительности и функциональности, мы выбрали общую топологию для всех этих кластеров. Давайте выясним, как это выглядит!
Каждый кластер состоит из 3 узлов, каждый из которых выполняет свою роль — основной, реплика и резервное копирование.
Основной узел принимает рабочие нагрузки для чтения и записи, в то время как реплики обрабатывают только запросы только для чтения. Когда основной узел выходит из строя, мы продвигаем узел реплики, чтобы он стал основным. Поскольку в подавляющем большинстве случаев базы данных обрабатывают гораздо больше запросов только на чтение, чем запросы на чтение и запись, узлы реплики можно добавлять для масштабирования возможностей кластера только для чтения. Это называется горизонтальным масштабированием. Наш последний узел посвящен операциям резервного копирования. Резервные копии невероятно важны, о них мы поговорим чуть позже.
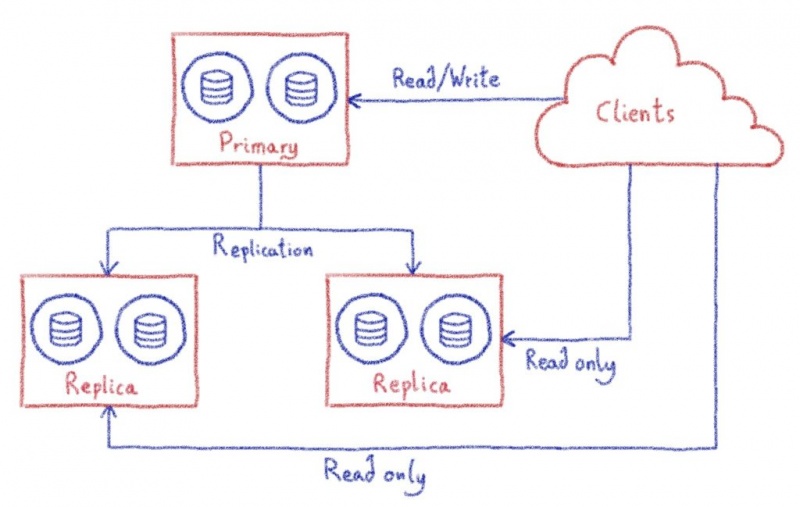
Поскольку каждый узел в кластере может быть повышен до основного, они должны иметь возможность обрабатывать одну и ту же рабочую нагрузку. Таким образом, они должны иметь одинаковые ресурсы (процессор, оперативная память, диск, сеть ...). Это особенно важно, когда нам нужно продвигать реплику, потому что она должна будет обрабатывать ту же рабочую нагрузку. В этом случае наличие первичной копии и реплики не одинакового размера может иметь катастрофические последствия для вашей рабочей нагрузки. С нашими кластерами и работающими мы можем начать запрашивать их. Каждый кластер может содержать одну или несколько баз данных в зависимости от нескольких факторов, таких как стоимость инфраструктуры и типы рабочей нагрузки (критически важные для бизнеса, транзакционные или аналитические ...).
Таким образом, один кластер может содержать от одной большой базы данных до десятков меньших. В этом контексте малые и большие определяются не только количеством данных, но и ожидаемой частотой запросов. По этой причине мы тщательно настраиваем каждый кластер, чтобы обеспечить их соответствующим образом. Когда база данных растет и кластер больше не имеет соответствующего размера, мы переносим базу данных в новый кластер.
Помимо производства у нас есть еще одна небольшая среда, которая удовлетворяет две потребности. Это наша среда разработки. Мы используем его для тестирования наших резервных копий и обеспечения наших разработчиков средой тестирования. Мы вернемся к этому вопросу всего за несколько строк.
Теперь давайте поговорим о резервных копиях. Как я упоминал ранее, резервные копии являются важной частью баз данных корпоративного уровня. Чтобы избежать необходимости поддерживать разные процессы для разных разновидностей СУБД, мы разработали общий процесс резервного копирования, который мы применяем ко всем этим.
Это позволило нам автоматизировать его более эффективно и абстрагировать сложность различных программ.
Как вы уже, наверное, догадались, резервное копирование выполняется узлом резервного копирования. Этот узел является частью кластера, и на него синхронно реплицируются данные, но он не получает никакого запроса. Когда выполняется моментальный снимок, процесс СУБД останавливается, и снимок файловой системы берется и отправляется на сервер хранения за пределами кластера для архивирования и обеспечения отказоустойчивости. Для этой цели мы используем ZFS из-за его надежности и из-за дополнительной пропускной способности, которая снижает затраты на хранение, связанные с архивированием снимков.
Но главная причина наличия отдельного узла резервного копирования заключается в следующем: резервное копирование никак не влияет на кластер. Действительно, резервное копирование полной базы данных может оказать очень заметное влияние на производительность (блокировки, потребление ресурсов ЦП и ОЗУ и т. Д.), И мы не хотим этого делать на производственных узлах.
Но резервные копии бесполезны, если их невозможно восстановить. Поэтому каждый день мы восстанавливаем последний снимок каждого кластера на отдельном выделенном узле. Это позволяет нам убить двух зайцев одним выстрелом, так как эта недавно восстановленная резервная копия также используется нашей командой разработчиков для создания почти современной среды разработки в дополнение к тому, что мы можем восстанавливать резервные копии.
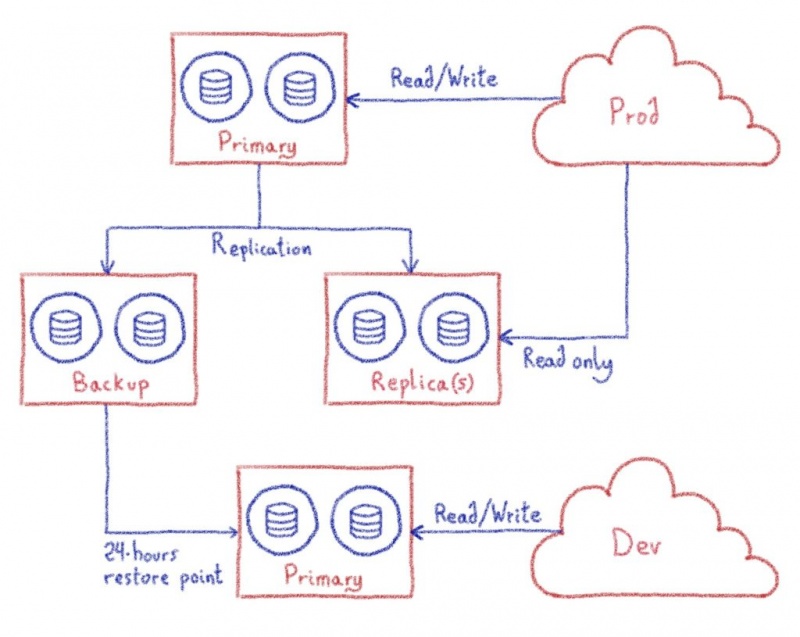
Подводя итог: наши кластеры баз данных являются модульными, но следуют общей топологии. Кластеры могут содержать различное количество баз данных в зависимости от их ожидаемых рабочих нагрузок. Каждая из этих баз данных масштабируется горизонтально для операций только для чтения, предлагая различные соединения для операций только для чтения и операций чтения и записи. Кроме того, узлы резервного копирования используются для регулярного резервного копирования без влияния на производственные базы данных. Внутренне эти резервные копии затем восстанавливаются на отдельных узлах как свежая среда разработки.
На этом мы завершаем обзор внутренней инфраструктуры базы данных OVHcloud, и вы готовы к следующему посту, посвященному репликации. Будьте на связи!
Как часть команды, ответственной за эту инфраструктуру, я могу сказать, что это огромная ответственность за поддержание столь важной части бьющегося сердца OVHcloud.
В этой новой серии постов мы рассмотрим инфраструктуру внутренних реляционных баз данных OVHcloud. Этот первый пост посвящен инфраструктуре внутренних баз данных. В OVHcloud мы используем 3 основные СУБД (системы управления базами данных), PostgreSQL MariaDB и MySQL, каждая из которых опирается на одну кластерную архитектуру.
Но сначала, что такое кластер? Кластер — это группа узлов (физических или виртуальных), работающих вместе для предоставления службы SQL.
В OVHcloud у нас есть открытый исходный код и культура «сделай сам». Это позволяет нам контролировать наши расходы и, что более важно, осваивать технологии, на которые мы опираемся.
Вот почему в течение последних двух лет мы проектировали, развертывали, совершенствовали и запускали отказоустойчивые кластерные топологии, а затем внедряли их в промышленную эксплуатацию. Чтобы удовлетворить наши требования к надежности, производительности и функциональности, мы выбрали общую топологию для всех этих кластеров. Давайте выясним, как это выглядит!
Каждый кластер состоит из 3 узлов, каждый из которых выполняет свою роль — основной, реплика и резервное копирование.
Основной узел принимает рабочие нагрузки для чтения и записи, в то время как реплики обрабатывают только запросы только для чтения. Когда основной узел выходит из строя, мы продвигаем узел реплики, чтобы он стал основным. Поскольку в подавляющем большинстве случаев базы данных обрабатывают гораздо больше запросов только на чтение, чем запросы на чтение и запись, узлы реплики можно добавлять для масштабирования возможностей кластера только для чтения. Это называется горизонтальным масштабированием. Наш последний узел посвящен операциям резервного копирования. Резервные копии невероятно важны, о них мы поговорим чуть позже.
Поскольку каждый узел в кластере может быть повышен до основного, они должны иметь возможность обрабатывать одну и ту же рабочую нагрузку. Таким образом, они должны иметь одинаковые ресурсы (процессор, оперативная память, диск, сеть ...). Это особенно важно, когда нам нужно продвигать реплику, потому что она должна будет обрабатывать ту же рабочую нагрузку. В этом случае наличие первичной копии и реплики не одинакового размера может иметь катастрофические последствия для вашей рабочей нагрузки. С нашими кластерами и работающими мы можем начать запрашивать их. Каждый кластер может содержать одну или несколько баз данных в зависимости от нескольких факторов, таких как стоимость инфраструктуры и типы рабочей нагрузки (критически важные для бизнеса, транзакционные или аналитические ...).
Таким образом, один кластер может содержать от одной большой базы данных до десятков меньших. В этом контексте малые и большие определяются не только количеством данных, но и ожидаемой частотой запросов. По этой причине мы тщательно настраиваем каждый кластер, чтобы обеспечить их соответствующим образом. Когда база данных растет и кластер больше не имеет соответствующего размера, мы переносим базу данных в новый кластер.
Помимо производства у нас есть еще одна небольшая среда, которая удовлетворяет две потребности. Это наша среда разработки. Мы используем его для тестирования наших резервных копий и обеспечения наших разработчиков средой тестирования. Мы вернемся к этому вопросу всего за несколько строк.
Теперь давайте поговорим о резервных копиях. Как я упоминал ранее, резервные копии являются важной частью баз данных корпоративного уровня. Чтобы избежать необходимости поддерживать разные процессы для разных разновидностей СУБД, мы разработали общий процесс резервного копирования, который мы применяем ко всем этим.
Это позволило нам автоматизировать его более эффективно и абстрагировать сложность различных программ.
Как вы уже, наверное, догадались, резервное копирование выполняется узлом резервного копирования. Этот узел является частью кластера, и на него синхронно реплицируются данные, но он не получает никакого запроса. Когда выполняется моментальный снимок, процесс СУБД останавливается, и снимок файловой системы берется и отправляется на сервер хранения за пределами кластера для архивирования и обеспечения отказоустойчивости. Для этой цели мы используем ZFS из-за его надежности и из-за дополнительной пропускной способности, которая снижает затраты на хранение, связанные с архивированием снимков.
Но главная причина наличия отдельного узла резервного копирования заключается в следующем: резервное копирование никак не влияет на кластер. Действительно, резервное копирование полной базы данных может оказать очень заметное влияние на производительность (блокировки, потребление ресурсов ЦП и ОЗУ и т. Д.), И мы не хотим этого делать на производственных узлах.
Но резервные копии бесполезны, если их невозможно восстановить. Поэтому каждый день мы восстанавливаем последний снимок каждого кластера на отдельном выделенном узле. Это позволяет нам убить двух зайцев одним выстрелом, так как эта недавно восстановленная резервная копия также используется нашей командой разработчиков для создания почти современной среды разработки в дополнение к тому, что мы можем восстанавливать резервные копии.
Подводя итог: наши кластеры баз данных являются модульными, но следуют общей топологии. Кластеры могут содержать различное количество баз данных в зависимости от их ожидаемых рабочих нагрузок. Каждая из этих баз данных масштабируется горизонтально для операций только для чтения, предлагая различные соединения для операций только для чтения и операций чтения и записи. Кроме того, узлы резервного копирования используются для регулярного резервного копирования без влияния на производственные базы данных. Внутренне эти резервные копии затем восстанавливаются на отдельных узлах как свежая среда разработки.
На этом мы завершаем обзор внутренней инфраструктуры базы данных OVHcloud, и вы готовы к следующему посту, посвященному репликации. Будьте на связи!
0 комментариев
Вставка изображения
Оставить комментарий