Ошибки предпринимателя в оценке сроков запуска интернет-магазина, выборе партнёра-разработчика и хостинга обычно связаны с недостатком базовой технической экспертизы или нехваткой опыта. Владельца бизнеса могут не волновать детали ИТ-инфраструктуры и хостинг, но всегда волнуют затраты на них. Хотя любые сервисные изменения в интернет-магазине зависят от ИТ-инфраструктуры.
Выбор инфраструктуры определяет дальнейшие возможность бизнеса (доступность, надежность, масштабируемость). А эффективное масштабирование требует понимания ключевых затрат, в том числе затрат на инфраструктуру и особенностей технологической платформы.
В этой статье обсуждаем:
- Как проблемы в обслуживании интернет-магазина связаны с выбором хостинга
- Преимущества платформы Яндекс.Облако для интернет-магазина
- С чего начать подготовку к запуску интернет-магазина и как составить требования к ИТ-инфраструктуре
Нам помогает
Алексей Васильев, директор и владелец
веб-студии «Интернет-Эксперт», партнёра Яндекс.Облака. Компания с 2007 года запускает и сопровождает интернет-магазины и устраняет потери лидов, автоматизируя все этапы процесса интернет-продаж. Последние 5 лет специализируется на обслуживании магазинов, у которых несколько тысяч товаров в каталоге, больше двадцати заказов в день и требуются личные кабинеты пользователям. На момент публикации статьи на обслуживании 70 таких проектов и больше 300 созданных сайтов и магазинов в портфолио.
Студия «Интернет-Эксперт» выбирает 1С-Битрикс как одну из самых функциональных CMS и платформу Яндекс.Облако для создания надежных, отказоустойчивых и легко масштабируемых интернет-магазинов.
Как проблемы в обслуживании интернет-магазина связаны с выбором хостинга
- Сбор данных для каталога товаров и другие периодические задачи
- Поддержка актуальности каталога товаров и цен
- Мониторинг работы магазина
- Подготовка к масштабированию
- Доступность интернет-магазина для клиентов 24/7
1. Сбор данных для каталога товаров и другие периодические задачи
По опыту студии «Интернет-Эксперт» разработка интернет-магазина длится 2-3 месяца. К этому моменту сайт может быть готов к старту маркетинговых кампаний и привлечению трафика.
Этот срок может затянуться, если заказчик не может собрать данные для каталога товаров. Компания-разработчик может сразу автоматизировать эту задачу. Она напишет и настроит под прайс-листы поставщиков товара парсер — программу, которая будет периодически собирать информацию о товарах из заданных источников и загружать ее в базу данных сайта или 1С. Если каталог товаров большой, задача становится ресурсоемкой. Кроме парсеров со временем появляются другие ресурсоемкие выгрузки для агрегаторов, партнёров, диллеров, магазинов в социальных сетях.
Такие задачи среди прочих задают требования к инфраструктуре. И если маленький магазин с товарным каталогом в несколько сотен позиций может решить её в рамках базовых ресурсов стандартного хостинга, то большому магазину, где больше тысячи товаров нужна настройка инфраструктуры и профессиональная инженерная экспертиза.
Например, чтобы решить проблему оттягивания ресурсов под эту задачу у основного сервера (процессора и памяти), обычно разворачивают отдельный сервер. Но часть времени он может простаивать из-за периодичности таких задач. А на массовых хостингах вы чаще всего платите за весь период аренды независимо от загрузки мощностей.
Поэтому при выборе хостинга стоит рассмотреть возможность не заказывать избыточно мощный сервер в сборке, а подобрать достаточный под свои задачи с возможностью платить только за фактическое потребление ресурсов на такие задачи. А также оценить доступность масштабирования (добавления новых ресурсов).
2. Поддержка актуальности каталога товаров и цен
Если в магазине больше 1000 товаров, есть склад, остатки в учётной системе и многофакторная система ценообразования, обязательно необходим корректный обмен данными между 1С и CMS.
Что такое обмен данными и как он работает
В 1С есть штатный модуль обмена данными с сайтом. Он отправляет на сайт информацию о товарном каталоге и выгружает с сайта заказы. Обменом также называют саму выгрузку данных большого объёма. Есть два типа обмена: полный — загружает каталог полностью; выгрузка только изменений — сохраняет изменения с предыдущей выгрузки и требует меньше ИТ-ресурсов и времени.
В нашей практике самый долгий обмен на 100 тысяч товаров длился 28 часов. А цены магазина были привязаны к валюте и обновлялись в 1С каждые 20 минут. При этом каждая выгрузка изменений становилась полной, так как менялись все цены, это требовало много ресурсов. Мы разбили выгрузки на несколько отдельных обменов (самостоятельных выгрузок): товары, свойства, картинки, контрагенты, заказы, цен, ценовые группы и т. д. Благодаря тому, что выгрузки стали проходить отдельно и сливаться на сайте, время разовой выгрузки сократилось до 7 минут, а полной — до часа
приводит пример Алексей Васильев
Что важно для работы обменов:
- На стороне сайта — производительный сервер, достаточное количество памяти и времени выполнения для интерпретатора скриптов.
- На стороне 1С — также производительный сервер и грамотная настройка под специфику магазина, которая, по мнению Алексея Васильева, требуется в каждом случае.
В каталоге товаров порядка 1500 номенклатурных единиц и включен учет в разрезе характеристик. У каждой модели одежды есть номенклатурный номер, и, допустим, 30 цветов на 8 размерных рядов — это дает 240 комбинаций торговых предложений для сайта. В результате 1,5 тысячи товаров дают порядка 360 000 комбинаций характеристик. А покупатели на сайте выбирают именно комбинацию характеристик, наличие которой еще нужно проверить на складе адресного хранения. Чтобы обмен учитывал все это, требуется изменение стандартных настроек модуля обмена или доработка
разъясняет Алексей специфику магазина одежды
Алексей также поясняет, что стандартный обмен рассчитан на обработку 5-7 характеристик. При этом его алгоритм использования памяти сейчас реализован так, что требования к памяти геометрически растут с ростом характеристик. Никто не поручится, что после добавления нескольких единиц нового товара или новых характеристик обмен будет корректно работать и своевременно подгружать данные, не забирая ресурсы у сервера сайта. Когда ресурсов не хватает, обмен «тормозит» и «падает», а на сайте отражается неактуальная информация.
Чтобы устранить эту проблему, кроме доработки нужна оптимальная площадка для хостинга с производительными серверами и возможностью быстрого масштабирования, чтобы нехватка памяти не стала критичным ограничением в работе магазина.
Что мешает обмену на массовых хостингах На массовых хостингах есть ограничения, которые прерывают обмен при превышении лимитов времени на операцию, лимитов нагрузки на CPU или объема используемой памяти. Когда лимит превышен, хостинг расценивает это как длинный «connect» и прерывает операцию. В среднем на популярных хостингах типовое ограничение по выполнению обмена 120 секунд и меньше. Максимально допустимое время на операцию, которое встречала команда Алексея Васильева на массовых хостингах, 300 секунд. На практике же обмен может длиться от 20 минут до нескольких часов.
3. Мониторинг работы магазина
Одних клиентов, в первую очередь, интересует контроль над работоспособностью сервисов и очень волнует надежность. Они хотят своими глазами видеть отчёты о работоспособности и контролировать устойчивость
делится наблюдениями Алексей Васильев.
Если мелкие интернет-магазины (до 15 заявок в день) при запуске чаще всего фокусируются на видимой пользователю части сайта (дизайн, фронтенд), то более опытные — выдвигают требования к функциональности «админки» сайта, чтобы управлять заказами и автоматизировать работу магазина. Часто популярные CMS сравнивают по функциональности «админки» и необходимости ее доработок.
С хостингами похожая история: удобный и функциональный кабинет (консоль) дает понимание, как текущая работа инфраструктуры влияет на доступность магазина и сколько денег вы тратите ежедневно.
При выборе обратите внимание, даёт ли платформа детальные мониторинги доступности и производительности сервисов и детализацию затрат по дням и ресурсам, насколько понятно представлены данные, легко ли организовать доступ к дашбордам.
Инфраструктура интернет-магазина и мониторинг должны быть прозрачны и одинаково доступны как администраторам интернет-магазина, так и управляющим бизнесом. Обратите внимание на возможности настройки уровня доступов.
4. Подготовка к масштабированию
Когда заказы растут, нужна локализация сайта для дилерской сети и регионов. Нагрузка на инфраструктуру и операционная нагрузка могут сильно вырасти, а система и процессы к этому не готовы. Например, при запуске платного продвижения и региональных поддоменов резко возрастает трафик и требования к производительности. В этой ситуации многие веб-сервисы сталкиваются с ограничениями массовых хостингов.
Алексей Васильев, владелец веб-студии «Интернет-Эксперт»
Часто встречаю ситуации, когда публичные хостинги принудительно останавливают работу сайтов из-за высокой нагрузки на свою инфраструктуру
Частые лимиты массовых хостингов, которые ограничивают интернет-магазины:
- Лимит на количество объектов файловой системы ограничивает количество картинок, которые необходимы в интернет-магазине в больших количествах. Каждый товар в среднем требует 6 превью (для списка товаров, для корзины, для карточки товара и т. д.). Кроме того, для ускорения работы фильтров в каталогах товаров, CMS интернет-магазина генерируют большое количество файлов кэша. Если сайт упирается в лимит объектов файловой системы — это резко сказывается на его производительности и функционировании в целом.
- Лимиты на время выполнения скриптов. Для CMS бывают отдельные тарифы с расширенными лимитами и повышенной стоимость, но также существуют ограничения.
- Лимит на количество запросов.
- Лимит на количество одновременных процессов.
Алексей приводит другой пример
Компания запускает 150 поддоменов своего сайта для разных городов. С точки зрения нагрузки даже от поисковых роботов-индексаторов — это десятикратный рост, потому что каждый поддомен обходит отдельный индексатор. И требуется 4 типа таких сайтов под нишевые продукты, это увеличит нагрузку еще в 4 раза. Сравнили железный сервер и облако, поняли, что облако для них в 2 раза дешевле. И облако даёт возможность поэтапно развернуть ресурсы под такую задачу без покупок в прок и ограничений массовых хостингов
5. Доступность интернет-магазина для клиентов 24/7
Есть разные способы сократить время простоя в случае инцидентов и их количество. Рассмотрим некоторые из них.
- Как заложить отказоустойчивость на этапе разработки
- Об отказоустойчивости и бэкапах
- Как база данных влияет на производительность интернет-магазина
- Отказоустойчивое хранение и раздача контента
1. Как заложить отказоустойчивость на этапе разработки
Работоспособность может пострадать при внесении изменений, накатывании нового функционала. Например, видите посторонние артефакты на экране, или не открываются картинки. Даже минорное отличие версий программного обеспечения и окружения при разработке, тестировании и в рабочей среде магазина может вызывать сбои. Например, обновление библиотеки обработки графики создает сбой в показе картинок.
Мы решаем эту проблему с помощью Docker-контейнеров. Они позволяют нам создать изолированную среду и на единой архитектуре разрабатывать тестировать и запускать очень разнородные сервисы с разными требованиями к этой инфраструктуре. Например, сервис генерации печатных форм в формате PDF использует среду исполнения, включающую Headless Chrome и библиотеки рендеринга графики и шрифтов. Его окружение никак не связано со средой исполнения сайта, включающей интерпретатор кода, базу данных и веб-сервер. Но мы можем запустить рядом, на одном сервере 2 контейнера с изолированными приложениями и нужной им средой исполнения. Таким образом сервис генерации печатных форм становится доступен для сайта
говорит Алексей Васильев
Эту задачу можно решить, развернув отдельные виртуальные машины. Но это увеличивает время на развертывание и настройку, усложняет перенос и снижает надёжность. В результате вырастает цена разработки и риски для заказчика.
Docker-контейнеры по мнению студии «Интернет-Эксперт» расширяют возможности масштабирования: при миграции с одной виртуальной машины на кластер система сохраняет стабильность.
2. Об отказоустойчивости и бэкапах
Алексей продолжает: «Каждый день наши заказчики просят нас восстановить данные (удалённые пункты меню, страницы, данные клиентов). Где бы ни размещался клиент, мы не полагаемся на обещания хостингов о частоте и качестве бэкапов. Мы не раз убеждались, что обещанные хостинг-провайдерами бэкапы либо не создаются, либо копии могут быть устаревшими, например, трехмесячной давности. Поэтому для каждого клиента мы настраиваем сервис резервного копирования.
Наше инфраструктурное решение по хранению бэкапов, развернуто в Object Storage Яндекс.Облака. Для создания резервных копий используется утилита duplicity. Мы храним в Object Storage ежедневные инкрементальные данные как минимум за последние 90 дней и можем восстановить копию файла, актуальную на любой день из этого периода. Утилита duplicity позволяет разрабатывать гибкую стратегию резервного копирования: можно выбрать расписание создания полных и инкрементальных копий. Программа сама вычисляет изменения, сжимает и складывает их в архив. Она использует библиотеку librsync и утилиту rdiffdir для рекурсивной обработки директорий, что позволяет создавать бэкапы очень быстро и многопоточно. Мы создали для себя удобный интерфейс для восстановления файлов и таблиц базы данных, но обнаружили что его простота стимулирует клиентов пользоваться сервисом самостоятельно, и мы даем к нему доступ по запросу».
3. Как база данных влияет на производительность интернет-магазина
От базы данных зависит 80% работы интернет-магазина. В проектах по-разному устроен каталог товаров, который хранится в базе, требуется разный объём памяти под профиль выполнения запросов конкретного интернет-магазина. Поэтому возможность настройки базы данных под проект радикально влияет на производительность сервиса.
Частые ограничения массовых хостингов в работе баз данных
Обычно на хостинге создан один централизованный сервер базы данных, на котором раздаются права доступа для разных клиентов. Так как сервер единый, он использует единый кэш для всех проектов на этом сервере без возможности конфигурирования. И запросы по конкретному сайту постепенно замещаются в кэше информацией других сайтов, что сильно снижает производительность. Для интернет-магазина желательно иметь свой независимый инстанс базы данных, а объёмы кэша должны соответствовать объёмам и профилям запросов, исполняемым на конкретном интернет-магазине.
4. Отказоустойчивое хранение и раздача контента
Хранение и раздача статического контента могут тратить ресурсы сервера, которые часто ограничены по объёмам, и это может увеличивать время отклика сайта. В качестве альтернативы можно использовать объектное хранилище (например, Object Storage Яндекс.Облака), которое не ограничено по размеру и не создаёт дополнительную нагрузку на веб-сервер, где «размещён» сайт. Это позволяет создавать несколько потоков раздачи контента, а хранение и раздача стоят дешевле.
В итоге это повышает отзывчивость и скорость работы сайта для пользователя, что особенно важно при масштабировании.
Алексей Васильев делится, как студия «Интернет-Эксперт» оптимизирует раздачу контента с помощью Object Storage
Мы привязываем Object Storage к сайту как отдельный домен. Такое разделение позволяет браузеру поддерживать два отдельных параллельных потока загрузки ассетов. С хоста сайта грузится динамика, а с хоста Object Storage — статика. Это можно отследить в панели сети браузера. Технически сложно вручную сделать распределение по нескольким хостам, а с Object Storage мы получаем эту функциональность без лишних затрат на разработку
Подробнее о способах создания и поддержания отказоустойчивости интернет-магазина — в записи нашего
вебинара.
Преимущества Яндекс.Облака для интернет-магазина
- Гибкие конфигурации и прозрачное масштабирование
- Автоматическая загрузка данных без переплаты за ИТ-ресурсы
- Надежная управляемая база данных для стабильной работы интернет-магазина
- Отказоустойчивое безлимитное хранение в Object Storage
- Удобный мониторинг, диагностика неисправностей и оценка затрат
- Подробная документация и помощь проверенных партнёров
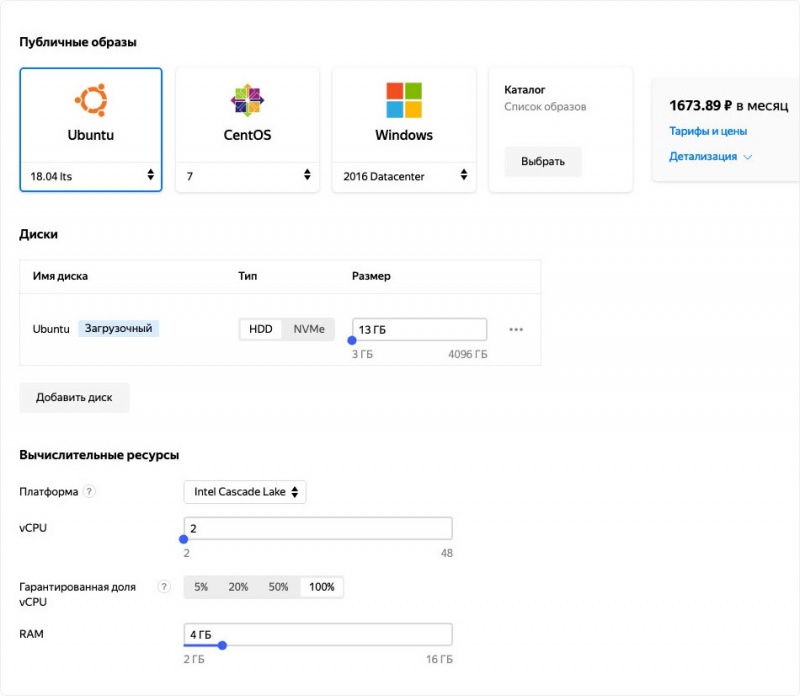
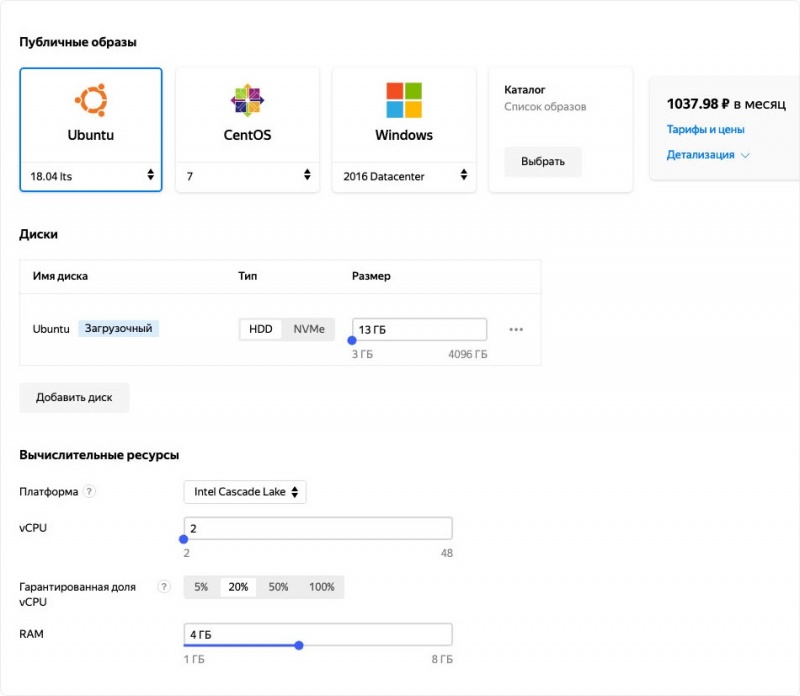
1. Гибкая настройка виртуальных машин и баз данных, прозрачное масштабирование
Благодаря тому, что Яндекс.Облако предоставляет виртуальные машины с гибкими настройками, конфигурация серверов на старте сразу соответствует требованиям интернет-магазина. По мере роста проекта ресурсы можно прозрачно масштабировать: добавлять ядра процессора, память и диски, запускать новые виртуальные машины и сервисы.
При работе с группами виртуальных машин вы можете использовать автоматическое масштабирование — автоматическое добавление и удаление виртуальных машин при всплесках нагрузки.
Возможности выбора параметров виртуальных машин, дисков и баз данных в Яндекс.Облаке:
- 2 платформы Intel Broadwell и Intel Cascade Lake (с увеличенной производительностью);
- возможность выбрать чётное количество ядер в диапазоне 1-32 для Intel Broadwell и 2-48 для Intel Cascade Lake;
- от 1 до 16 Гб RAM без привязки к количеству ядер процессора;
- виртуальные машины с частичным использованием ядра 5-20-50-100%;
- прерываемые виртуальные машины с жизненным циклом 24 часа;
- выбор объема HDD/SSD диска от 1 до 4096 Гб.
Алексей Васильев
Цена старта в Яндекс.Облаке такая же как на других площадках или ниже. При этом доступны более функциональные и мощные сервисы и цена масштабирования существенно ниже. Не нужно мигрировать сайт, достаточно добавить ресурсы работающим сервисам и увеличить производительность
2. Автоматическая загрузка данных о товарах и другие периодические задачи без переплаты за ИТ-ресурсы
Яндекс.Облако позволяет экономить на всех периодических задачах и не только, благодаря гибким тарифам и ресурсам под разные сценарии:
- Все машины доступны по требованию (on demand). Это подходит при значительных колебаниях в уровне загрузки процессора и неизвестных темпах роста. Клиент платит только за используемые ресурсы. Тарификация посекундная.
- Прерываемые ВМ подходят для высокопроизводительных и кратковременных вычислений и тестирования. Могут быть прерваны в течение 24 часов по инициативе Яндекс.Облака. Скидка 60-70% от цены по требованию.
- Если вы уверены в прогнозе ваших нагрузок, то можете оставить заявку на вычислительные мощности на 1 или 3 года вперёд и получить скидку не менее 20% (фиксированное потребление предоставляется по запросу).
3. Надежная управляемая база данных для стабильной работы интернет-магазина
В Яндекс.Облаке доступны управляемые базы данных PostgreSQL, MongoDB и MySQL, ClickHouse, Redis™. Можно создать кластеры с синхронной репликацией для всех доступных БД (от 2 до 7 хостов в любой зоне доступности). Пользователь сам может решить, какой уровень отказоустойчивости для него важен, создать хосты в нескольких зонах доступности или в одной. Хосты можно добавлять в процессе эксплуатации. Вам также доступно автоматическое и ручное резервное копирование баз данных.
Так как на массовых хостингах пользователи часто делят один инстанс базы между собой, в случае уязвимости на хостинге данные могут стать доступны этой СУБД или другим клиентам. В Облаке это невозможно — базы данных разных пользователей изолированы. Инстанс управляемой базы данных в Яндекс.Облаке создаётся исключительно для конкретного клиента.
В каждой управляемой базе данных Яндекс.Облака автоматизирована часть операций по настройке и сопровождению базы. Это разгружает команду разработки и может снизить счёт владельца интернет-магазина за услуги администрирования.
Подробнее о преимуществах управляемых баз данных.
4. Отказоустойчивое безлимитное хранение и раздача контента на базе Object Storage
Object Storage — универсальное масштабируемое решение для хранения данных. Оно подходит как для высоконагруженных сервисов, которым требуется надёжный и быстрый доступ к данным, так и для проектов с невысокими требованиями к инфраструктуре хранения. Для доступа к данным можно использовать популярные инструменты для работы с объектными хранилищами — API сервиса совместим с Amazon S3 API.
В Yandex Object Storage предоставляется столько места, сколько нужно интернет-магазину. Данные автоматически сохраняются в трёх географически распределённых зонах доступности. Для всех этих данных действует репликация: при редактировании, создании и удалении файла меняется каждая копия.
Пример от студии Интернет-Эксперт
Агентство элитной недвижимости размещалось на голландском хостинге: VPS с диском на 50ГБ, из которых сайт занимал 35 ГБ. Все файлы хранили на диске виртуальной машины. Объектов недвижимости стало больше и понадобилось увеличить количество картинок в 6 раз. Объём картинок превысил объём диска на виртуальной машине. VPS не масштабируется, она не облачная. Мы описали клиенту варианты решения: покупка дополнительной VPS, масштабируемый сетевой диск в Яндекс.Облаке или объектное хранилище Object Storage. Когда клиент согласился на миграцию в Яндекс.Облако и хранение контента в Object Storage, место на диске перестало быть ограничивающим фактором. Стоимость хранения сократилась на 20%
5. Удобный мониторинг инфраструктуры, диагностика неисправностей и оценка затрат
Сервис
Yandex Monitoring подходит для сбора метрик состояния ресурсов и загрузки сервисов. Собрав метрики на одном дашборде, можно контролировать работу приложений, быстрее находить причины неисправностей и взаимосвязи между различными показателями. Анализируя
преднастроенные дашборды, вы можете планировать ресурсы и затраты на них.
Отследить затраты помогает сервис
Yandex DataLens. Данные о потреблении за день можно выгружать в формате csv-файлов. Yandex DataLens позволяет настроить дашборды на основе этих датасетов и ежедневно отслеживать затраты на вашу инфраструктуру до уровня каждого сервиса.
6. Подробная документация и помощь проверенных партнёров
Вы можете самостоятельно развернуть интернет-магазин и инфраструктуру для него или воспользоваться помощью партнёра Яндекс.Облака.
Полезные статьи в документации для запуска интернет-магазина:
С чего начать подготовку к запуску интернет-магазина и оценку требований к ИТ-инфраструктуре
Определите
- поставщиков, объём и формат предоставления данных о товаре и его источники;
- куда будете заливать данные: в базу 1С или в базу сайта;
- частоту обмена данными и актуализации цен и валют;
- варианты хостинга.
Тот, кто разрабатывает и сопровождает сайт, обязан решать следующие задачи: конфигурация серверов и баз данных под текущие требования, мониторинг роста требований, выбор площадки с возможностью быстрого масштабирования.
Что влияет на требования к ИТ-инфраструктуре:
- объем товарной базы, количество сочетаний и характеристик;
- количество регионов продаж и количество поддоменов;
- потенциальный траффик, который зависит от вашей целевой воронки;
- план развития на год и прогноз роста потребностей в ИТ инфраструктуре.
В Яндекс.Облаке вы можете быстро стартовать с теми ресурсами, которые нужны при запуске, затем добавлять их по необходимости без дополнительных затрат на миграцию инфраструктуры в будущем.
cloud.yandex.ru