Выделенный сервер - это то, что Вы давно искали

Мы предлагаем варианты:
- Количество ядер: 6-12
- Оперативная память 32-128 Gb
- Объем дисков 240-2000 Gb
Цена бомба — от 41€
С таким сервером у Вас в кармане неограниченные действия, круглосуточный мониторинг, мощность, качественное оборудование, стабильная и бесперебойная работа даже при высоких нагрузках и, конечно же, полная защищенность данных.
zomro.com/dedicated.html
Добавили новые тарифы ОВХ
CLO: облачные серверы по новым ценам

Облачные серверы на проекте CLO стали ещё доступнее. Стоимость начальных конфигураций существенно снизилась: например, сервер с 1vCPU, 2 Гб RAM и 10 Гб диска стоит 170 рублей в месяц вместо 440 руб/мес (без учёта IP-адреса).

clo.ru/prices
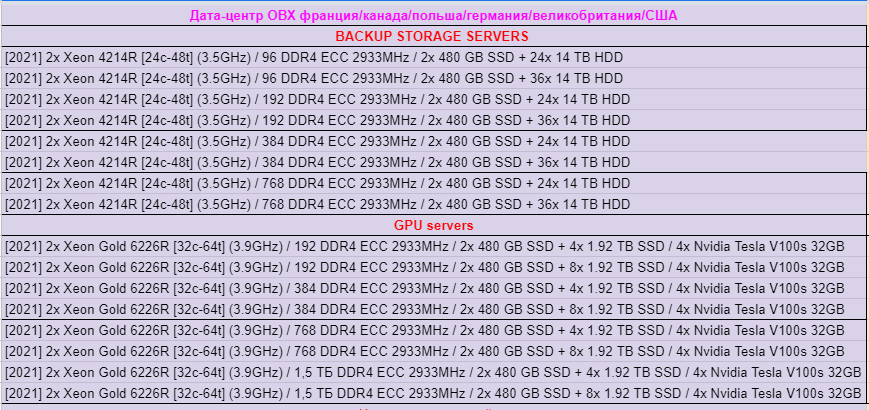
Новые тарифы Xeon Gold 6256 4.5 ГГц в Германии по старым ценам!

С превеликой гордостью сообщаем о запуске обновленных тарифов в Германии!
Для новых тарифов мы используем самый мощный процессор Xeon Gold 6256 с частотой до 4.5 ГГц, который аналогичен по производительности i9-9900K, но стоимость тарифов оставили старой:
1 CPU, 1GB, 10GB NVMe = 327₽/мес или 14₽/день
2 CPU, 2GB, 20GB NVMe = 647₽/мес или 27₽/день
3 CPU, 4GB, 80GB NVMe = 1.117₽/мес или 46₽/день
4 CPU, 8GB, 120GB NVMe = 1.748₽/мес или 72₽/день
6 CPU, 12GB, 180GB NVMe = 2.626₽/мес или 107₽/день
8 CPU, 16GB, 240GB NVMe = 3.470₽/мес или 140₽/день
Все серверы расположены в ЦОД OVH в Германии и имеют перманент защиту от DDoS атак от OVH.
Для существующих клиентов с серверами в Германии есть возможность бесплатного перехода на новое оборудование без потери данных и IP.
Установка серверов происходит в течение 120 секунд после оплаты.
Приглашаем всех протестировать новые тарифы и поделиться мнением:
Сайт: msk.host/products/vds
Биллинг: my.msk.host
Остались вопросы? Пишите в онлайн-чат на сайте: msk.host
Эстония - новая локация на карте BlueVPS

Мы открыли новую точку присутствия в Прибалтике, столице Эстонии – Таллинн.
Оборудование размещается в Дата центре InfonetDC, класса Tier 3. Уровень отказоустойчивости составляет 99,9%.
Удобное географическое положение и связность с Латвией, Россией, Финляндией, Швецией, Беларусью, Польшей, Германией, Украиной и рядом других государств Восточной и Центральной Европы.
Гарантированные ресурсы (KVM) и отсутствие лимитов позволит вам избежать дополнительных трат и проблем связанных с ограничениями.
Как и в остальных наших локациях мы предлагает 1 Гбит шаред порт без ограничений потребления трафика.
Наша техническая поддержка доступна 24/7/365 и готова помочь в настройке по вашему запросу.
bluevps.ru
Обновление тарифов Веб-хостинга
Дорогие пользователи, мы выпустили полное обновление для услуги Веб-хостинга. Теперь 3 разных тарифа заменяют один старый!
Представляем новинки:
• Start — 89 руб.
5 Gb SSD
2 домена
• Standard — 179 руб.
12 Gb SSD
5 доменов
• Premium — 319 руб.
25 Gb SSD
15 доменов
В скором времени будут добавлены новые локации размещения сайтов.
До 23 апреля Вы можете приобрести новый Хостинг для своего сайта со скидкой 10% по промокоду NewWebHost.
Размещайте веб-сайты на надежном оборудовании.
© Провайдер SpaceCore.
Остались вопросы? Мы ответим!
Сайт: https://spacecore.pro
Биллинг: https://billing.spacecore.pro
Email: support@spacecore.pro
Telegram: @spacecore_pro
VK: vk.com/spacecore_pro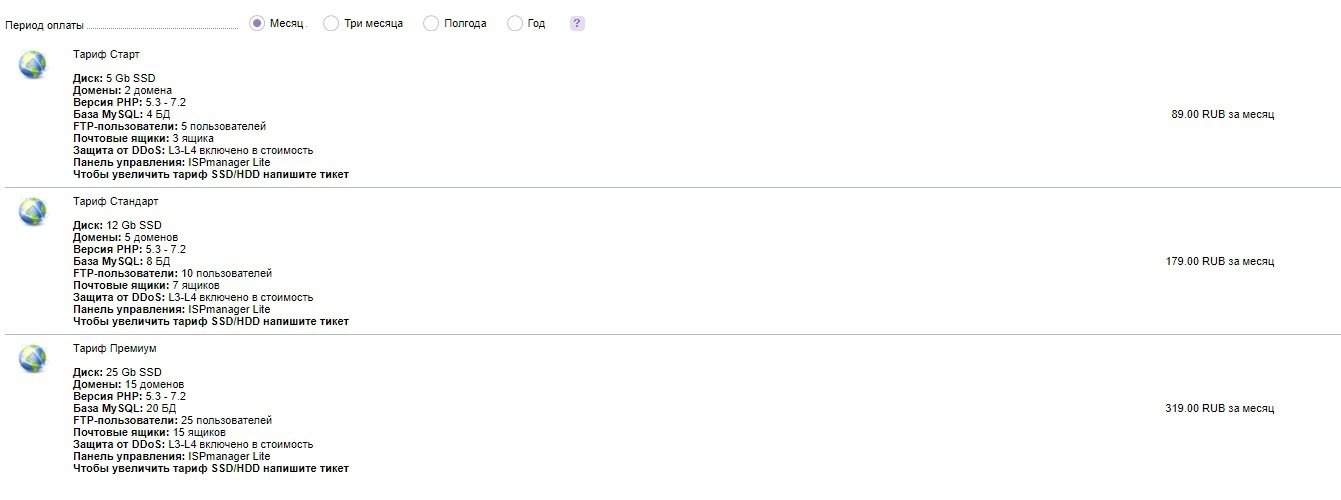
Представляем новинки:
• Start — 89 руб.
5 Gb SSD
2 домена
• Standard — 179 руб.
12 Gb SSD
5 доменов
• Premium — 319 руб.
25 Gb SSD
15 доменов
В скором времени будут добавлены новые локации размещения сайтов.
До 23 апреля Вы можете приобрести новый Хостинг для своего сайта со скидкой 10% по промокоду NewWebHost.
Размещайте веб-сайты на надежном оборудовании.
© Провайдер SpaceCore.
Остались вопросы? Мы ответим!
Сайт: https://spacecore.pro
Биллинг: https://billing.spacecore.pro
Email: support@spacecore.pro
Telegram: @spacecore_pro
VK: vk.com/spacecore_pro
Сервис Yandex Managed Service for Elasticsearch вышел в общий доступ с официальными подписками Elastic Stack

Сервис стал общедоступным
13 апреля Managed Service for Elasticsearch, сервис для управления кластерами Elasticsearch, перешел в общедоступную версию. Managed Services for Elasticsearch усиливает экосистему сервисов Yandex.Cloud для создания бизнес-решений на нашей платформе данных. Теперь в облаке возможно реализовать еще больше бизнес-сценариев, связанных с хранением, анализом и принятием решений на основе данных. Применение Еlasticsearch позволяет улучшить пользовательский опыт: повысить стабильность и скорость работы, предлагать новые функции на основе анализа действий пользователя.
cloud.yandex.ru/services/managed-elasticsearch
Еlasticsearch хорошо подходит для проектов, которые должны стабильно работать при стремительном росте обращений к данным. Сервис позволяет в несколько кликов увеличить или уменьшить потребление облачных ресурсов при изменениях нагрузки. Заняв место между аналитическими СУБД и инструментами мониторинга, Elasticsearch решает задачи: поиска в реальном времени по внутренним и внешним ресурсам компании, анализа логов или других документов.
Также Еlasticsearch предоставляет набор аналитических инструментов, с помощью которых можно получать информацию и принимать решения на основе журналов событий и метрик, повышать эффективность операций в ИТ, сокращать время принятия решений, получать данные для разработки и информационной безопасности.
Разворачивая кластеры Еlasticsearch в облаке, вы передаете большинство работ по установке необходимых обновлений и настройке продукта облачной платформе, а сами можете сфокусироваться на разработке и настройке поиска в вашем приложении.
Сервис доступен всем пользователям Yandex.Cloud. Теперь для него действуют соглашение об уровне обслуживания (SLA) и правила тарификации. yandex.ru/legal/cloud_sla_mdb/
Начните пользоваться управляемым Elasticsearch в Yandex.Cloud console.cloud.yandex.ru/link/managed-elasticsearch/
Партнерство с Elastic NV
Платформа Yandex.Cloud и компания Elastic, разработчик решений Еlasticsearch и Elastic Stack, договорились о стратегическом партнерстве. Yandex.Cloud стала первой в России облачной платформой, которая предоставляет Elasticsearch как управляемый сервис в публичном облаке.
www.elastic.co
В Managed Services for Еlasticsearch вы можете выбрать любой вариант подписки из трех: Basic, Gold и Platinum. В лицензиях с расширенным функционалом доступны, например, сервис SIEM (Security Information & Event Management), который позволяет реализовать критически важные сценарии обеспечения безопасности, различные виды визуализаций в Kibana и интеграция со сторонними провайдерами аутентификации и авторизации (SAML). Также как официальный партнер Yandex.Cloud имеет прямой доступ к технической поддержке Elasticsearch.
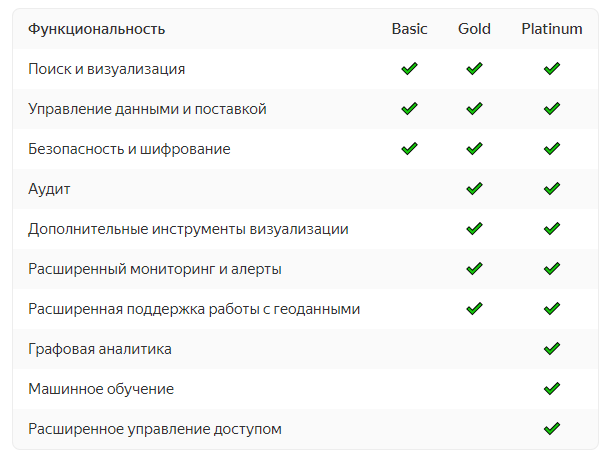
Выбрать тип подписки вы можете при создании нового кластера Managed Service for Elasticsearch в консоли управления.
console.cloud.yandex.ru/link/managed-elasticsearch/
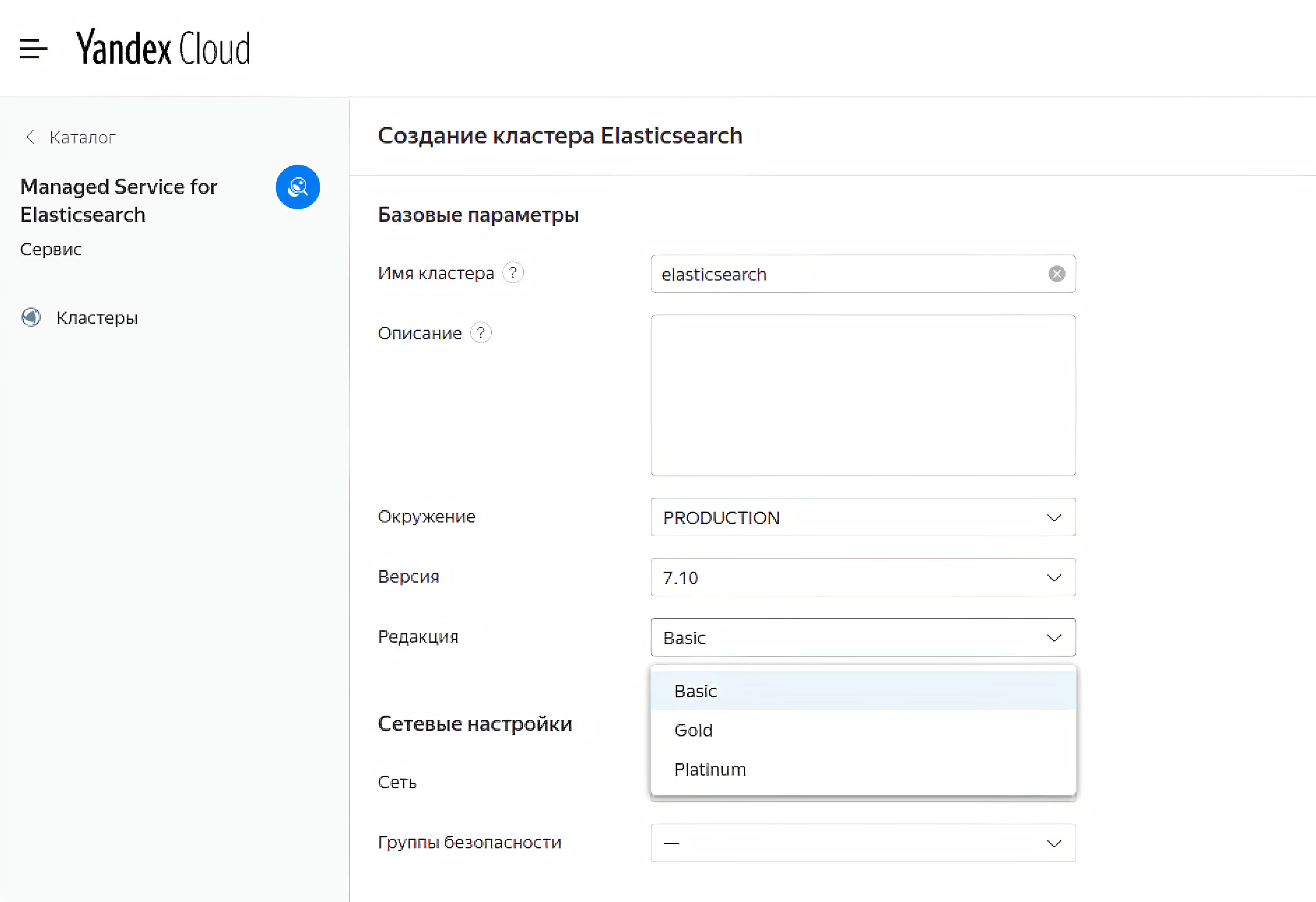
Уже существующие кластеры по умолчанию переведены на подписку Basic. Изменить тип подписки существующего кластера можно без остановки и перезапуска. Подробнее о работе с сервисом Managed Service for Elasticsearch читайте в документации.
cloud.yandex.ru/docs/managed-elasticsearch
Подробная информация об инциденте с балансировщиком нагрузки FR-PAR-1 07/04/2021

7 апреля в 16:35 по всемирному координированному времени компания Scaleway столкнулась с серьезным инцидентом в зоне доступности FR-PAR-1, который повлиял на наш продукт Load Balancer. Часть инфраструктуры балансировщика нагрузки была недоступна во время инцидента. В результате также пострадали продукты Database, Kubernetes Kapsule и IoT Hub, которые полагаются на Load Balancer как часть своей инфраструктуры.
Проблема была обнаружена и устранена к 17:18 по всемирному координированному времени специалистами по сетевым продуктам и пользователям и API.
Был запущен процесс Scaleway Incident, побудивший всех участников собраться вместе и скоординировать задачи, необходимые для восстановления затронутых служб, и обеспечить бесперебойную связь. Работая удаленно более года, мы собирались не в физической комнате, а в виртуальной, с несколькими каналами связи, которые оставались открытыми в течение ночи, чтобы обеспечить эффективный и доступный поток информации в эти критические моменты.
Сразу началось восстановление сервисов. Большинство сервисов Load Balancer были восстановлены к 20:34 по всемирному координированному времени, а несколько критических случаев заставили нашу команду по надежности сайта и инженеров по продуктам работать до 0:04 по всемирному координированному времени 8 апреля. Продолжительность основного отключения составила почти 4 часа, а общий инцидент длился 7 часов 29 минут.
Приносим извинения за неудобства, вызванные отключением, и благодарим вас за терпение в этот период недоступности. Ваши данные были в безопасности и всегда были защищены, и данные не были потеряны.
Это сообщение в блоге призвано объяснить подробности воздействия, основную причину инцидента, шаги, которые мы предприняли для его устранения, а также меры, принятые для предотвращения возникновения подобной проблемы в будущем.
Анализ воздействия
Инцидент затронул несколько продуктов Scaleway.
Что касается Load Balancer, только 1574 экземпляра Load Balancer, принадлежащих 775 организациям-клиентам, были отключены до того, как мы исправили проблему и начали процедуру восстановления. Эти балансировщики нагрузки и их серверы были недоступны во время инцидента. После инцидента все ресурсы Load Balancer были восстановлены до нормального состояния.
Для базы данных было задействовано до 50 балансировщиков нагрузки, и был потерян доступ к соответствующим базам данных (до 500). Во время инцидента данные были в полной безопасности, но недоступны. В период восстановления создание базы данных и обновление «Разрешенных IP-адресов» было невозможно. Резервные копии оставались доступными и экспортируемыми в любое время.
Kubernetes Kapsule затронул 229 кластеров, принадлежащих 207 организациям-клиентам. Kapsule использует балансировщики нагрузки как часть своей инфраструктуры между узлами кластера и плоскостью управления. Во время инцидента клиенты, отключившие функцию автоматического восстановления, не смогли связаться со своими плоскостями управления, но их экземпляры и службы, запущенные на узлах кластера, были по-прежнему доступны. Клиенты, использующие функцию автоматического восстановления, потеряли свои услуги, поскольку плоскость управления начала создавать новые узлы, но не могла связаться с ними из-за недоступности балансировщиков нагрузки.
Что касается Интернета вещей, это затронуло 33 клиента. Поскольку Центр Интернета вещей использует балансировщик нагрузки, базу данных и Kubernetes Kapsule, служба была недоступна во время инцидента. После инцидента все клиентские ресурсы Центра Интернета вещей были восстановлены в нормальном режиме.
Основная причина и решение проблемы
Инцидент был вызван ручным вызовом API-интерфейса Load Balancer Trust and Safety (T&S) с запросом на удаление ресурсов злонамеренного пользователя. Этот конкретный вызов не был частью обычного рабочего процесса; он состоял в созданном запросе, который должен был выдать ошибку. К сожалению, ошибка в API, представленная ранее реализацией функции «Проекты», вызвала обход проверок безопасности и спровоцировала лавинную недействительность экземпляров Load Balancer.
Хронологию инцидента можно найти здесь, на странице статуса Scaleway.
Звонок был сделан 7 апреля в 16:35 по всемирному координированному времени, а сигналы тревоги были включены в наш внутренний канал мониторинга в 16:45 по всемирному координированному времени.
Команда немедленно начала процедуру содержания и восстановления.
- 7 апреля 2021 г., 16:53 по всемирному координированному времени. API балансировщика нагрузки был переведен в режим только для чтения, чтобы избежать дальнейших операций со стороны клиентов.
- 7 апреля 2021 г., 17:20 по всемирному координированному времени. Конфигурации балансировщика нагрузки были восстановлены из нашей внутренней резервной копии базы данных, сделанной часом ранее. Данные не были потеряны, так как балансировщики нагрузки не имеют состояния.
- 7 апреля 2021 г., 17:54 UTC. Запущен процесс восстановления экземпляра Load Balancer.
- 7 апреля 2021 г., 20:10 по всемирному координированному времени 1400 экземпляров были успешно вылечены, 110 по-прежнему не работали и требовали ручного лечения.
- 7 апреля 2021 г., 20:35 по всемирному координированному времени. Все экземпляры Load Balancer были успешно восстановлены. Некоторые критические дела еще предстояло расследовать.
- 7 апреля 2021 г., 22:12 по всемирному координированному времени. Службы базы данных и IoT Hub вернулись в нормальное состояние. Некоторые крайние случаи с парой балансировщиков нагрузки и Kubernetes Kapsule все еще решались.
- — Пользовательские сертификаты TLS были недоступны, и их приходилось восстанавливать из безопасного хранилища сертификатов.
- — Обнаружение живучести серверной части не удалось из-за фильтрации IP-адресов на внутренних серверах и того факта, что IP-адреса балансировщика нагрузки изменились.
- 8 апреля 2021 г., 00:04 UTC. Все экземпляры Load Balancer были восстановлены и исправлены. Все услуги вернулись в нормальное состояние.
Как мы предотвратим повторение этого
После анализа происшествия сразу были приняты следующие меры:
- Ошибка Load Balancer T&S API была исправлена, и в тестовые наборы были немедленно добавлены дополнительные тесты.
- Процедура тестирования T&S API была обновлена с дополнительными межгрупповыми проверками и обзорами.
- Kubernetes Kapsule теперь проверяет состояние балансировщика нагрузки перед запуском автоматического восстановления.
- Улучшение рекомендаций по реализации T&S API.
- Улучшите тестовое покрытие Load Balancer T&S API и используйте инструменты анализа покрытия.
- Развертывайте и разрабатывайте инструменты для улучшения и ускорения общей процедуры восстановления Load Balancer.
- Продукт Database в рамках постоянного улучшения производительности в настоящее время модернизирует свою инфраструктуру Load Balancer, чтобы сделать ее менее подверженной сбоям.
Заключение
При написании этого сообщения в блоге мы хотели предоставить нашим пользователям подробное представление об инциденте и о том, как мы его обнаружили, сдержали и разрешили.
Проблема была вызвана ошибкой в наших API, которую мы быстро обнаружили и исправили. Помимо устранения самой проблемы, в процессе мы определили несколько направлений улучшения. Мы уже внедрили меры роботизации и продолжим их улучшать и расширять в ближайшем будущем.
Данные клиентов были в безопасности и всегда были защищены, и потери данных не происходили. Производительность и надежность наших продуктов имеют для нас первостепенное значение, и мы постоянно работаем над улучшением наших услуг.
Новый POP в Испании!

Команда разработчиков ClouDNS неустанно работает над обновлением наших услуг. Теперь мы представляем самые свежие новости от нас!
Наша 31-я точка присутствия уже доступна! Он находится в Испании, в Мадриде! POP находится в дата-центре Interxion Madrid. Он имеет прямое соединение с DE-CIX Madrid и DE-CIX Lisbon, а также с Telefonica и другими крупными интернет-провайдерами в стране. Учить больше!
Здесь вы можете найти список всех дата-центров ClouDNS Anycast и некоторую информацию о них!
www.cloudns.net/premium/