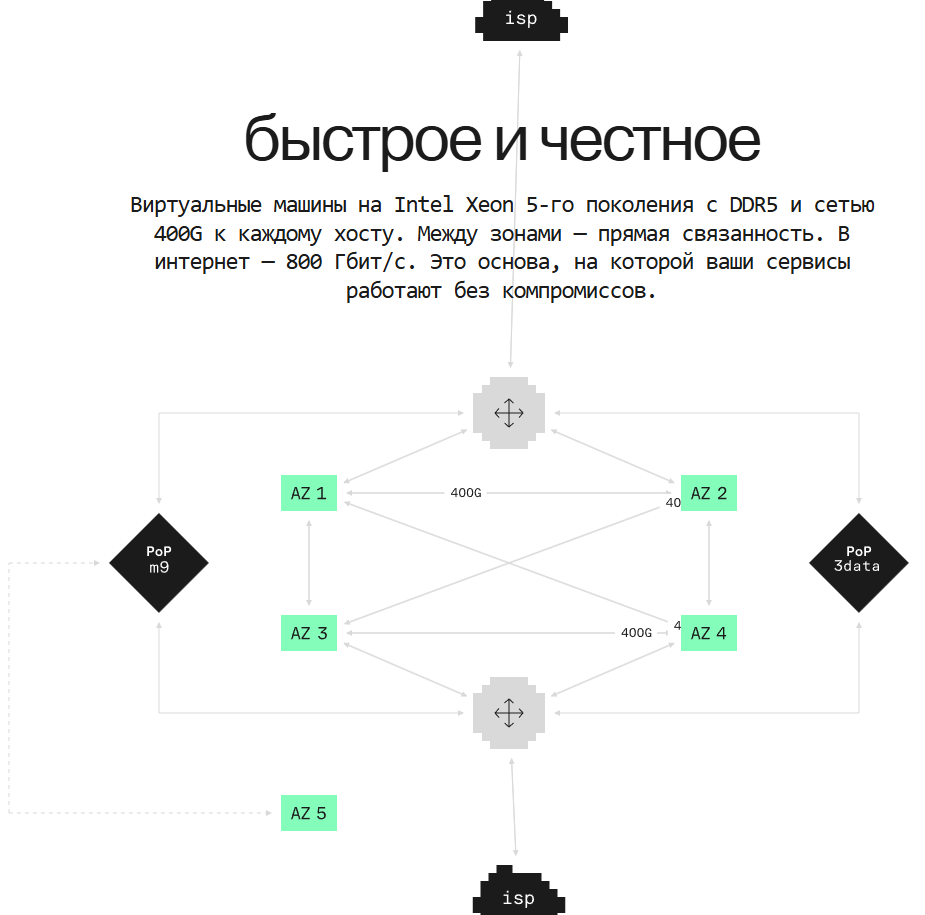
Мы строили-строили и наконец-то построили последнее коммерческое облако в РФ.
Почему последнее — потому что теперь конкурировать с крупными корпоратами из-за кучи ограничений, экономики, высокого порога входа по бюрократии и теперь ещё цене железа (из-за улетевшей в космос по цене оперативки) почти нереально. Возможно, года через 3–4 появится ещё кто-то, кто сможет бросить вызов Яндексу, Сберу, Селектелу и ещё паре игроков, но пока тут только мы.
И мы ненавидим корпоративный подход.
Он медленный, неэффективный, поддержка у них часто считает пользователя за пустое место. Почему я всё это знаю — потому что сам работал с Ростелекомом.
Чуть позже я расскажу про то, как прошла бета, и там оказалось, что самое главное — просто не быть козлами. Это даже важнее, чем быстрое железо.
Но, возможно, вам всё это не очень интересно, а интересна халява. Поэтому перехожу сразу к ней.
Халява
Вот ресурсы, которые получает участник акции «Год в облаке бесплатно» при создании аккаунта и пополнении баланса на 5000 ₽:
- 2 виртуальные машины по 2 vCPU /4 Гб RAM
- База данных 2 vCPU / 2 Гб RAM
- 40 Гб сетевых дисков
- Балансировщик нагрузки
- Белый IPv4
- 10 Гб объектного хранилища
Участвовать можно только один раз, если что-то не понравится — возвращаем деньги при предъявлении паспорта.
Действует по 31 декабря 2025, то есть ещё несколько дней.
Подробнее тут
limits.h3llo.cloud
Этого хватает попробовать основные фичи. Один человек рассказывал, как развернул там учебный Кубер — одна машина контрол-плейн, вторая — кластер. Так делать уже не надо (если только из мазохизма желания научиться ставить Кубер ручками) — есть менеджед-сервис.
Ещё у нас отдельно есть помощь для стартапов — там нужны объёмы больше, чем в тестовых пакетах. Для них у нас есть история с грантами. Мы готовы новым проектам давать не только инфраструктуру, но и экспертизу — помогать правильно заезжать на наше облако и т.п. Тут приходите в личку или в почту world@h3llo.cloud
Коротко, что поменялось от беты к релизу 1.0
Начали в мае с первой публичной беты. Она несколько раз менялась, в частности, мы избавлялись от кусков cozy stack и наследия его архитектуры. Там же появилось нормальное геораспределение. После летней миграции мы очень усердно навалились на продуктовую часть: переписали кучу всего внутри платформы, отладили биллинг, связали его с логикой акций и лимитов, выстроили процессы поддержки.
Сейчас добавили:
- Полноценно работающие VPC, качественную дисковую подсистему с репликацией (в том числе мультизональной) и гибкое управление инстансами — можно настраивать CPU и RAM под свои нужды.
- Уже готовы и работают Managed Kubernetes и базы данных (PostgreSQL/MariaDB). Мы сейчас переводим на этот стек остальные сервисы, так что скоро после рефакторинга вернутся Redis, OpenSearch и ClickHouse.
- Load Balancer работает из коробки, и он умнее, чем кажется. Например, он умеет разруливать трафик по портам: если у вас группа машин, где часть слушает порт 8080, а часть — 9000, балансировщик поймёт, куда и что направлять, если выставить эти порты наружу. Скоро выкатим продвинутую версию с ACL и выбором стратегии балансировки.
- Внедряем аренду Bare Metal. Пока выдаём серверы вручную по запросу, но строим автоматизированный Bare Metal as a Service, в том числе Managed Kubernetes на голом железе. Для автоматизации уже готов Terraform-провайдер, сейчас допиливаем и полируем Public API.
Главное отличие релиза от того, что было полгода назад, — это стабильность и архитектурная зрелость. В первой бете мы честно говорили: «Ребята, всё может пойти не так, делайте бекапы». И ситуации были разные. Бекапы много кому пригодились.
Самая показательная история произошла с нашей дисковой системой Linstor. Изначально мы, ориентируясь на референсы (в духе Cozy Stack), держали Linstor в оверлейной сети. То есть дисковая подсистема зависела от сетевой виртуализации. Как следствие — если ломалась сеть, падали и диски. В Кубере, чтобы диски работали в отдельной сети, нужно приложить специальные усилия, иначе трафик по дефолту идёт через оверлей.
Мы вынесли сторадж в отдельную физическую сеть. Сложность была в том, что платформа уже работала, там жили пользователи. Нам пришлось перестраивать фундамент на живую.
Это дало колоссальный опыт и готовые ранбуки для разных подобных инцидентов.
Мы внедрили жёсткую изоляцию по тенантам. Теперь система работает как современный корабль с переборками: если у одного клиента случается пробоина, это инкапсулируется внутри его проекта и не топит соседей. Глобальных падений, затрагивающих всех, больше нет.
Проблемы с доступом: это не мы, это ТСПУ
Интересный момент, который мы выловили на тестах: иногда пользователи жаловались на недоступность виртуалок по SSH. Мы начали копать и выяснили, что проблема не на нашей стороне. У некоторых провайдеров (включая мобильных операторов) блокируются зашифрованные соединения. Это похоже на борьбу с мессенджерами, но под раздачу попадает администрирование серверов по SSH.
Мы проверили: с того же провайдера через VPN — работает. На нестандартном порту — работает. Проблема наблюдается не только у нас, но и у DigitalOcean, и у Selectel. Наша поддержка теперь умеет это быстро диагностировать.
SLA
В бете никаких гарантий не было. Теперь для коммерческих заказчиков действуют полноценные SLA с финансовой ответственностью. Компенсация идёт скидкой от месячного периода.
Гарантируем доступность виртуальной машины — 99,95%. Виртуальная машина с GPU — 99,5%
При доступности:
- От 99,95 до 99,00% — скидка 10%
- От 99,00 до 95,00% — 15%
- Ниже 95,00% — 30%
Для пользователей бесплатной акции SLA тоже формально есть, но так как цена ресурса ноль, то и компенсация нулевая.
Мы можем гарантировать SLA выше и нести ответственность не по модели AS IS, это есть в отдельных корпоративных зонах. Если вам важно пережить чёрную пятницу, сделать вычисление в НИИ или обеспечить 5 девяток доступности, мы можем нести ответственность за доступность кластера с существенно большей финансовой ответственностью — но и тарифы будут вообще другими. Это обсуждается индивидуально для корпоративных заказчиков.
Недоступность фиксируется при потере сетевой связности или загрузочного диска по вине провайдера более 5 минут. Требование к состоянию виртуальных машин — статус Running. SLA не покрывает последствия пользовательских настроек, DoS/DDoS-атак и изменений гостевых ОС.
Ну и раньше люди запускали виртуалки, чтобы просто «потыкать». Теперь мы видим в аккаунтах машины с именами prod и stage. Пользователи начинают размещать серьёзные нагрузки, берут мощные виртуалки и доверяют нам свои рабочие среды. Это значит, что рынок готов воспринимать нас всерьёз.