Мы запускали облако, но сделали много ошибок. Сейчас расскажу про основное.
Если коротко — у нас в какой-то момент было больше двух тысяч человек, примерно половина из которых не понимала, что происходит, и мы не понимали, что происходит, и при этом нам со всех сторон сыпались жалобы. Разные.
Мы давали бесплатные лимиты в облаке, но нам нужно было убедиться, что это не будут абузить. Поэтому мы сделали порог в 1 000 рублей на часть бесплатных ресурсов и порог в 5 000 рублей пополнения счёта — на полную модель.
Вот эти пополнения и вызвали большую часть попоболи.
Баннеры
В статье мы всё подробно расписали про условия акции.
А вот на баннере так сделать нереально. Детали были по ссылке. Написаны.
Люди кликали на классный заголовок, ожидая полностью бесплатного предложения, букв особо не читали, а потом по мере процесса регистрации их перебрасывало на шаг, где выяснялось, что нужно пополнить баланс на 5 000 рублей. Естественно, они приходили к нам в Телегу кричать: «А вы просите, блин! Вот я-то думал, что мне всё бесплатно дадут!»

А вот и нет, совсем бесплатно просто за регистрацию мы, конечно, ничего не дадим. Точнее, могли бы, если бы придумали способ избежать повторных регистраций по кругу. В нашей картине мира пять тысяч рублей — достаточный аргумент, что пользователь добросовестный. Особенно если ему нужно облако.
Конечно же, мы ошибались.
5 000 рублей
По закону нам нужно аутентифицировать любого пользователя хостинга, для этого подходят номер сотового (потому что паспорт — у оператора при выдаче симки), банковский платёж (потому что паспорт — у банка при выдаче карты с чипом, как у симки) или регистрация через Госуслуги (потому что они тоже каким-то чудом создают однозначную связь с паспортом). Прикручивать Госуслуги — квест не для слабонервных. Где купить тысячу сотовых номеров за приемлемые деньги, мы знаем, и это распространённый вид абуза в сфере хостинов в России, поэтому остаётся банк.
Так вот, мы даём год бесплатного использования двух виртуальных машин, еще одну такую же виртуалку — под базу данных, балансировщик, объектное хранилище, место на диске и ещё всякую требуху. И хотим, чтобы там был честный пользователь, который привыкнет к хорошему, в идеале научится мыслить управляемыми сервисами, посмотрит год на нашу стабильность и поймёт, что можно переезжать с коммерческим проектом.
Для такого пользователя 5 000 рублей на баланс — не проблема.
Но!
Нас начали подозревать в том, что всё было ради этих пяти тысяч. Почему? Потому что изначально мы думали, что вернуть их нельзя, а можно только потратить на услуги хостинга.
И вот это по какой-то причине разозлило людей. В целом мы уже догадываемся, по какой: прописать условия возврата действительно было бы справедливо.
Путаница с условиями
Тут была целая история. Изначально у нас было два типа железа — старое и новое. Старое — такое же надёжное, как и новое, только больше, теплее и медленнее. Но за два дня до запуска приехали наши крутейшие серваки с Xeon 6530 и DDR5. Успели всё воткнуть до релиза: сами поработали грузчиками, раскатили всё, что было нужно, подняли сервисы и запустились полностью на них — мощных и свежих.
Поначалу предполагалось, что на старом мы делаем более медленные ВМ и даём их при пополнении счёта на 1 000 рублей — это достаточное подтверждение. Но если хочется иметь две топовые машинки, то надо пополниться на 5 000.
Так вот, проблема с порогами пополнения возникла из-за того, что старое мы просто выкинули из ЦОДа, а вот информация про него где-то осталась. В итоге мы пришли к тому, что вариант с 1 000 рублей убрали. Баннеры проапгрейдили, а часть публикаций — нет.
Последствия не заставили себя ждать. В статье мы всё быстро пофиксили, но к тому моменту уже успели получить две категории пользователей: первые, которые радовались офигенному офферу на 5 000, и вторые, приходившие и требовавшие халяву, которую ожидали, кликнув по баннерам или прочитав старую версию статьи.
Дефицит IP-адресов
В моменте мы буквально чуть не выстрелили себе в ногу с IPv4. У того, у кого мы их берём, как раз непосредственно перед запуском не оказалось нужного количества. Просто в мире всё меньше белых v4, и даже у поставщиков запас на складе иногда заканчивается. Еле выкрутились. Получилось дороже, но зато вовремя.
Оплата в новом окне
Потом — классическая проблема 2020-х: мы сделали переход на страницу оплаты в новом окне. А в новом окне обычно открывается всякое непотребство. И, конечно, «умные» браузеры начали блокировать открытие этих внешних ссылок.
Банк же считал открытие окна событием начала оплаты со всеми вытекающими последствиями, что добавило путаницы в сессиях.
Дофига кто нажимал, а пополнения баланса не происходило: страница просто не открывалась.
Открываю статистику, вижу тысячи оплат, думаю: «Вау, красота, регистрации валят!» А вот и нет: денег меньше, это просто люди не могли понять, куда и как их кидать в экран.
Наверное, стоило видеть моё лицо в тот момент, когда я увидел сводную по данным нашего API, а не банка. Потому что банк в своей статистике все транзакции «в процессе» тоже считал за мясо.
Очень, очень дофига людей
Мы не ждали тысяч обращений за часы, поэтому на второй день внедрили лист ожидания. Пользователь заходил, мы выводили дружелюбное сообщение: «Ты в листе ожидания, как в клубе, но без фейсконтроля. Скоро мы тебя запустим». И реально скоро запускали.
Так вот, там появились ручные случаи, когда люди писали, что фейсконтроль не пускает. На деле это письмо с приглашением уходило в спам.
Письма в спаме у Яндекса
Наши письма с приглашениями и информацией у Яндекса почему-то упорно попадали в спам. Пользователи присылали скрины: «Это письмо попало в папку «Спам» по следующим причинам: в письме — невалидная dkim-подпись».
Вроде мы не совсем конченые, админим не первый год и настроили всё верно. Да и писем у нас мало.
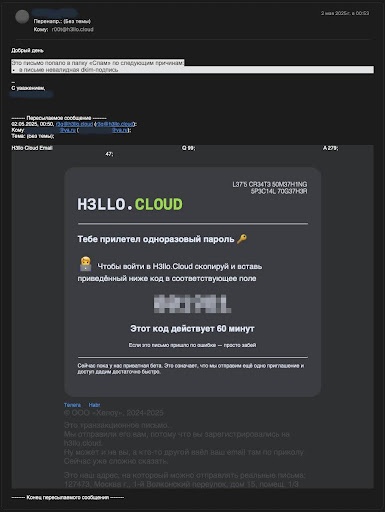
Я, естественно, ради проверки отправляю такое же письмо на гугловскую почту — Google говорит, что все подписи корректные, везде галочки. А Яндекс нашу подпись воспринимать отказывается. Единственный.
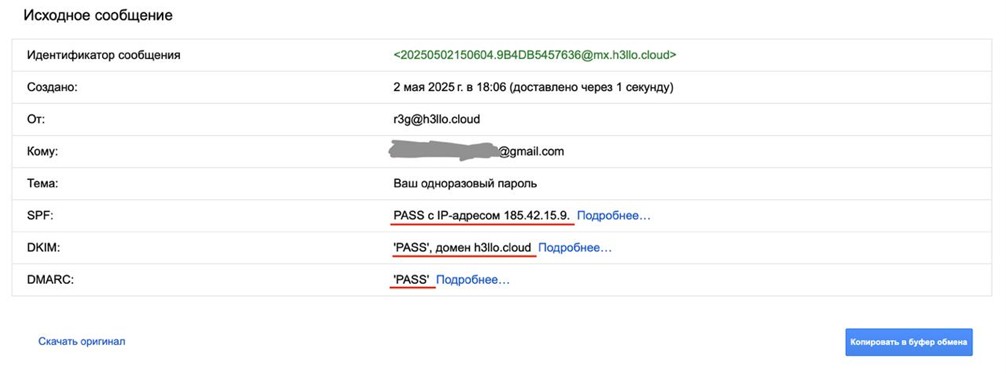
В итоге просто принял это как факт, что Яндекс не любит наших заголовков, а может, просто «Hello, Cloud». Не думаю, что они нас вообще хоть как-то заметили как конкурента (хотя мы их считаем основным будущим конкурентом), но само явление странное.
Что сделали для исправления
Править надо было на лету.
Сначала самое горячее — оплаты и лист ожидания. Сделали двухэтапную рассылку. Сначала — подтверждение регистрации, а уже потом — письмо: «Приходи, оплачивай пять тысяч, заноси деньги на баланс и получай вот это, это и это». Со всеми условиями, подробно. Это заработало. Было приятно, когда банк дублировал на почту уведомления об оплатах и они сыпались пачками.
Подробнее объяснили, что именно в бете. Мы подключаем фичи по мере их выхода из тестов. Например, балансировщика мгновенно не обещали, но как будет релиз — сразу. Люди удивлялись, что его нет сразу, и засыпали поддержку вопросами, где его найти.
Вывели все ожидаемые ресурсы в админпанель и показали, что и когда будет в бете. Подробнее написали про это в лендинге, чтобы не ждали сразу.
Повесили дисклеймер: «Дружище, это бета-версия. Здесь всё что угодно может пойти не так. Если есть вопросы, то welcome к нам в группу в Телегу и на почту». Дали прямой контакт в почте (отвечаю я) и Телегу, где отвечает вся команда.
Потом столкнулись с частой ошибкой пользователей. Люди не читали строчку в интерфейсе для подключения по SSH и пытались залогиниться с логином root вместо user. А рутовский доступ у нас везде по дефолту закрыт из соображений безопасности. Объясняли. Сделали строчку заметнее.
По возврату денег и борьбе с абузом посидели, покубатурили и решили: желающим вернуть — вернём. Но если заводить второй аккаунт, то бесплатных лимитов уже не дадим. Процедуру для вывода средств и верификации уже внедрили и протестили.
Смысл этой суммы был в том, чтобы выстроить некий фильтр и не допустить массовой регистрации ради бесплатных ресурсов.
И сейчас делаем интеграцию с Госуслугами, но нервы не выдерживают: для нас это уже ЭРЕБОР. Но надо доделать. Кому-то важно не давать поганым капиталистам ни рубля за демо, поэтому, вероятно, со временем доведём.
Многие регистрировались компаниями, и там бесила предоплата. Сейчас готовим такую механику: в аккаунте будет возможность создать компанию, некую абстракцию, и даже пригласить туда других пользователей. Это будет такой корпоративный аккаунт. К нему можно будет привязать как оплату карточкой постфактум, так и оплату через счёт, подключив ЭДО. Вот как раз для «физиков», если подключить карточку, будут удобны Госуслуги, потому что мы дадим возможность неограниченно уходить в минус (или можно пользоваться балансовой системой на личном аккаунте, чтобы не бояться внезапного масштабирования облака). Для компании подключение юрлица через ЭДО выглядит как вполне такой нормальный фильтр. И таким аккаунтам мы будем начислять, я думаю, тысяч 50 бонусных баллов на несколько месяцев. А бонусный балл в нашей сегодняшней игре равен российскому рублю. Кроме того, хотим перейти на честную постоплатную систему. Месяц пользуешься — потом тебе выставляется счёт. Даже если этот счёт выставлен на карточку, у тебя есть пять дней: можешь, если с чем-то не согласен, даже оспорить. Через пять дней мы просто захолдим сумму на карте, а ещё через пять запроцессим её. Юрлицам же даётся 10 дней — стандартная история. Понятно, что ещё есть период, когда он не оплатил, но мы его пока не блокируем, а только напоминаем. Если совсем долго не оплатил — тогда уже скажем: «Друг, ну всё, хорош это терпеть», всё остановим, но данные сохраним. У нас есть огромное холодное хранилище на два петабайта: туда можно сложить все бэкапы и ещё какое-то время его держать, если, конечно, пользователь не дал прямой команды уничтожать всё сразу при отключении.
Вот такие пироги! Ошибок мы наделали, но двигаемся дальше, учимся и спасибо, что пинаете нас. Добавили кнопку, чтобы послать нас в жопу на корпоративном сайте, прямо на главной, кстати.
Так что, если чем обидели — приходите на наш корпоративный сайт!
h3llo.cloud/ru