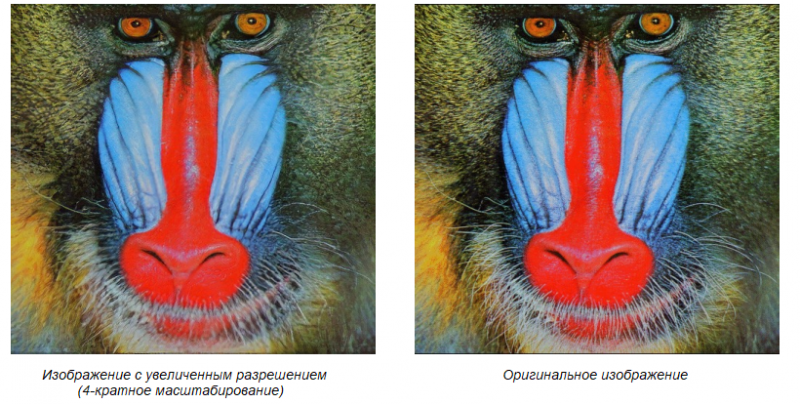
Повышение разрешения изображения с помощью AI

Все мы помним, как часто в фильмах и сериалах кадры из сжатого видео увеличивают в несколько раз и получают чёткое изображение улики или человека в толпе. Мы подготовили для вас краткий перевод статьи, из которой вы сможете узнать, что такой трюк действительно возможен.
Увеличение разрешения изображения — задача по восстановлению фотографии с высоким разрешением из её аналога с низким разрешением. Алгоритмы с более быстрыми и глубокими свёрточными нейронными сетями демонстрируют впечатляющую точность и скорость. Но остаётся нерешённой существенная проблема: как восстановить мелкие детали текстуры при больших коэффициентах масштабирования. Цель последних работ в этой области — минимизация среднеквадратичной ошибки при реконструкции изображений, но в результатах при увеличении разрешения часто терялась точность воспроизведения.
В этой статье мы расскажем о SRGAN — генеративно-состязательной сети (Generative Adversarial Network, GAN) для повышения разрешения изображений (image superresolution). На сегодняшний день это первое решение, способное восстанавливать исходные текстуры из изображений, уменьшенных в четыре раза. Средняя экспертная оценка (MOS — mean opinion score) показывает значительный прирост качества при использовании SRGAN: результаты оказались близки к значениям оригинальных изображений с высоким разрешением, чего не удавалось достичь с помощью других современных методов. Вы сможете сами убедиться в этом, если после ознакомления с принципами работы SRGAN обучите нейросеть или же воспользуетесь готовой моделью.
1. Описание модели
Методы, направленные на качественное увеличение разрешения исходного изображения, называются super-resolution (SR). Мы рассмотрим работу с одним изображением (Single Image Super-Resolution, SISR) и не будем затрагивать тему восстанавливления высокого разрешения из нескольких снимков.
Первые подходы к решению проблемы SISR основывались на прогнозировании. Например, линейная фильтрация, бикубическая фильтрация, фильтрация Ланцоша. Эти методы работают быстро, но выдают решения с чрезмерно гладкими текстурами. Более мощные подходы нацелены на создание сложного отображения между снимками с низким (Low Resolution, LR) и высоким (High Resolution, HR) разрешением и обычно основаны на данных обучения. Такие методы полагаются на примеры пар LR-HR, то есть на те тренировочные шаблоны LR, для которых известны подходящие аналоги HR.
Более глубокие сетевые архитектуры сложнее обучить, однако они могут моделировать сложные отображения, а значит — существенно повысить точность реконструкции. Для эффективного обучения таких сетей часто используется пакетная нормализация, чтобы избежать внутреннего ковариационного сдвига. Глубокие сетевые архитектуры также увеличивают эффективность SISR.
Для многих подходов часто применяются попиксельные (pixel-wise) функции потерь (например, среднеквадратичная ошибка), которые пытаются справиться с неопределённостью при восстановлении текстуры изображения. Минимизация ошибки позволяет находить средние вероятностные решения для каждого пикселя, но они получаются слишком гладкими и, следовательно, имеют низкое качество восприятия, как показано на рисунке ниже. Основными критериями качества в задаче SR являются пиковое отношение сигнала к шуму (peak signal-to-noise ratio, PNSR) и индекс структурного сходства (structure similarity, SSIM), также указанные на рисунке.

Для решения проблемы сглаженных пикселей можно использовать генеративно-состязательные сети (GAN) и применять, например, функции потерь, основанные на евклидовых расстояниях, вычисленных в пространстве признаков нейронных сетей в сочетании с состязательным обучением. Также можно использовать признаки, извлечённые из предварительно обученной VGG (Visual Geometry Group) нейросети, формулируя функцию потерь как евклидово расстояние между картами этих признаков. Результаты, полученные с применением этих подходов, показали высокую эффективность как при работе с SR, так и при передаче художественного стиля (artistic style-transfer).
GAN обеспечивают мощную основу для создания правдоподобных SR-изображений с высоким качеством восприятия. В этой статье мы описываем глубокую архитектуру ResNet, использующую концепцию GAN для фотореалистичного SISR. Основные особенности:
- увеличение разрешения изображения с высокими коэффициентами масштабирования (4x);
- использование функции потерь восприятия (perceptual loss function), рассчитанной с помощью карт признаков VGG сети, которые более инвариантны к изменениям пикселей;
- высокие результаты средней экспертной оценки MOS на общедоступных наборах данных.
2. Архитектура сети
Цель SISR — реконструировать изображение с высоким разрешением (SR) из входного изображения с низким разрешением (LR), которое является уменьшенной копией изначального снимка (HR). Изображения HR доступны только во время обучения, а LR создаются применением к ним фильтра Гаусса с последующей операцией понижения дискретизации (downsampling) и описываются с помощью действительного тензора.
Задача состоит в том, чтобы обучить генеративную функцию, которая для входного LR-изображения оценивает соответствующий HR аналог. Для этого мы обучаем GAN как cвёрточную нейронную сеть (convolutional neural network, CNN) прямого распространения с оптимизацией специфичной для SISR функции потерь восприятия.
Функция потерь восприятия генерируется как взвешенная комбинация нескольких компонентов, которые моделируют различные желаемые характеристики восстановленного SR-изображения.
Далее мы определяем дискриминаторную сеть (Discriminator Network, дискриминатор) и последовательно оптимизируем её вместе с генеративной сетью (генератором) для решения состязательной проблемы min-max. Общая идея заключается в том, чтобы обучить генеративную модель «обманывать» дискриминатор, который обучен отличать SR изображения от реальных. С помощью такого подхода генератор может научиться создавать решения, очень похожие на реальные изображения, и, следовательно, трудно классифицируемые дискриминатором.
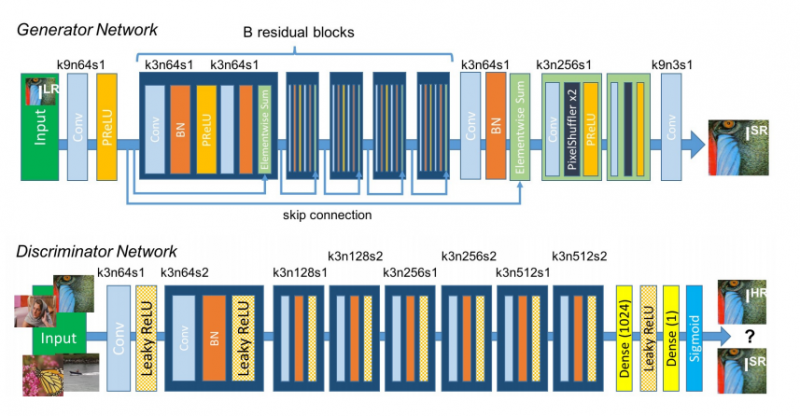
В основе генеративной сети находятся B остаточных блоков с идентичной компоновкой. В каждом блоке находятся два свёрточных слоя с небольшими ядрами 3×3 и 64 картами признаков, за которыми расположены слои пакетной нормализации. В качестве функции активации используется PReLU (Parametric Rectified Linear Unit). Входное изображение увеличивается попиксельно с помощью двух свёрточных слоев.
Чтобы отличить реальные HR-снимки от сгенерированных образцов SR, необходимо обучить дискриминаторную сеть, используя функцию активации LeakyReLU и избегая формирования подвыборочных слоёв во всей нейросети. Дискриминаторная сеть содержит 8 свёрточных слоёв с возрастающим числом ядер фильтра 3×3 (с 64 до 512, каждый раз увеличиваясь в 2 раза, как в VGG сети). Пошаговые свёртки используются для уменьшения разрешения изображения каждый раз, когда число признаков удваивается. Полученные 512 карт признаков сопровождаются двумя плотными слоями и конечной сигмоидной функцией активации, чтобы получить вероятность классификации объекта.
Архитектуры обеих сетей показаны на рисунке.
3. Функция потерь восприятия
Определение функции потерь важно для эффективной работы генеративной сети. Обычно функция моделируется на основе среднеквадратичной ошибки, но в этой работе используется её улучшенный вариант. Мы оцениваем решение с учётом значимых характеристик восприятия — взвешенной суммы потерь содержания и состязательных потерь.
Потери содержания определяются на основе слоёв активации ReLU предварительно обученной VGG сети и определяются как евклидово расстояние между признаками восстановленного и опорного изображений.
Потери восприятия заставляют сеть отдавать предпочтение естественным изображениям, пытаясь обмануть дискриминатор. Они определяются на основе вероятности того, что восстановленное изображение является исходным HR-изображением.
4. Эксперименты
Эксперименты проводились на трёх широко используемых наборах данных Set5, Set14 и BSD100, тестовом наборе BSD300. Все опыты выполнены с коэффициентом 4x между снимками с низким и высоким разрешением. Это соответствует 16-кратному уменьшению пикселей изображения. Для достоверного сравнения все измеренные значения PSNR [дБ] и SSIM были рассчитаны на Y-канале с центральным кадрированием и удалением полосы шириной в 4 пикселя у каждой границы изображения.
Обучение проводилось на графическом процессоре NVIDIA Tesla M40 с использованием случайной выборки из 350 тысяч изображений, взятых из базы данных ImageNet. Изображения LR были получены путём понижения дискретизации HR-изображений (BGR) с использованием бикубического ядра.
Для каждого мини-пакета обрезаются 16 случайно выбранных частей HR-изображения с разрешением 96×96 (мы можем применить генеративную модель к снимкам произвольного размера, так как она полностью является свёрточной). Далее входные LR-изображения масштабируются в диапазоне [0, 1], а HR — в диапазоне [-1, 1]. Таким образом, потери среднеквадратичной ошибки рассчитываются в диапазоне интенсивностей [-1, 1].
Для оптимизации используется алгоритм Adam (adaptive moment estimation). В качестве инициализации при обучении сети GAN использовалась ранее обученная нейросеть SRResNet, чтобы избежать нежелательных локальных минимумов.
Все варианты SRGAN прошли обучение с 105 обновляемыми итерациями со скоростью обучения 10−4, и затем ещё с 105 итерациями с более низкой скоростью 10−5, при этом чередуя обновления для генеративной и дискриминаторной сети. Генеративная сеть имеет 16 идентичных (B=16) остаточных блоков. Во время тестирования обновления пакетной нормализации отключены, чтобы получить результат, зависящий только от исходных данных.
5. Оценка качества и результаты
Для количественной оценки способности различных подходов восстанавливать высокое разрешение изображений был выполнен тест MOS. В тесте участвовали 26 оценщиков; они присваивали балл от 1 (плохое качество) до 5 (отличное качество) восстановленным SR-изображениям. Калибровка проводилась на 20 парах изображений с низким и высоким разрешением из набора BSD300. Оценщики сравнили 12 версий каждого изображения из Set5, Set14 и BSD100 для различных упомянутых выше подходов SISR, а также для оригинальных HR-изображений. Каждый оценщик протестировал 1128 экземпляров (12 версий 19 изображений плюс 9 версий 100 изображений) в случайном порядке. Результаты показали хорошую надёжность и никаких существенных различий между оценками идентичных изображений, что продемонстрировано на рисунке ниже.
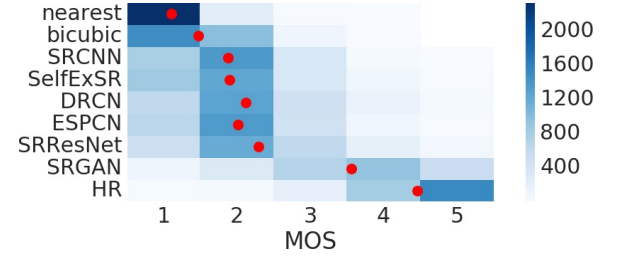
Качественные оценки потерь для различных методов на визуальном примере:

Количественные оценки:
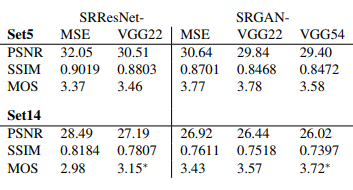
Решение, основанное на среднеквадратичной ошибке, получает самое высокое значение PSNR, но при этом получается довольно гладким и менее убедительным, чем результаты, полученные с более чувствительным коэффициентом потерь.
Таким образом, эксперименты подтверждают, что SRGAN превосходит все существующие методы с большим отрывом и открывает новые возможности для создания фотореалистичных SR-изображений. Ниже приведены примеры обработки нескольких снимков.

6. Обучение собственной нейросети для SISR
Используя материалы из этой статьи, вы можете обучить свою нейросеть для получения изображений с высоким разрешением. Исходный код доступен на github. Для начала работы вам необходимо:
Подготовить данные и предварительно обученную нейросеть VGG
- Загрузите предварительно обученную VGG сеть отсюда.
- Подготовьте изображения с высоким разрешением для обучения.
В качестве эксперимента использовались изображения из соревнования DIV2K — bicubic downscaling x4 competition, поэтому параметры обучения в файле config.py установлены в соответствии с этим набором данных. Если ваш датасет будет больше, то вы можете уменьшить число эпох обучения.
Также можно использовать набор данных Yahoo MirFlickr25k, загрузив их прямо из main.py:
train_hr_imgs = tl.files.load_flickr25k_dataset(tag=None)Если вы хотите использовать собственные изображения, укажите путь к папке с ними в файле
config.py с помощью config.TRAIN.hr_img_pathЗапустить программу
Установите папку с изображениями в config. py (если вы используете датасет DIV2K — ничего не меняйте):
config.TRAIN.img_path = "your_image_folder/"
Ссылки на набор DIV2K: <a href="https://data.vision.ee.ethz.ch/cvl/DIV2K/validation_release/DIV2K_test_LR_bicubic_X4.zip">test_LR_bicubic_X4</a>, <a href="https://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_HR.zip">train_HR</a>, <a href="https://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_train_LR_bicubic_X4.zip">train_LR_bicubic_X4</a>, <a href="https://data.vision.ee.ethz.ch/cvl/DIV2K/validation_release/DIV2K_valid_HR.zip">valid_HR</a>, <a href="https://data.vision.ee.ethz.ch/cvl/DIV2K/DIV2K_valid_LR_bicubic_X4.zip">valid_LR_bicubic_X4</a>Начните обучение:
python main.pyНачните оценку (можете воспользоваться предварительно обученной на DIV2K моделью):
python main.py --mode=evaluateТеперь вы можете использовать нейросеть для восстановления высокого разрешения изображений.
Все, кто на практике воспользовался рекомендациями по обучению генеративно-состязательной нейросети, делитесь в комментариях результатами: было ли это просто или возникали сложности. Всегда готовы обсудить с вами все возникающие вопросы.
С оригинальной статьёй можно ознакомиться на портале arxiv.org.
0 комментариев
Вставка изображения
Оставить комментарий