«Идеальный шторм» и как это лечится
Broadcast storm (широковещательный шторм) – это такой ночной кошмар сетевиков, когда в считанные секунды парализуется передача полезного трафика во всей сети ЦОД. Как это происходит и о чем надо было раньше думать – в нашей сегодняшней программе.
Откуда есть пошла
Вначале была Ethernet, и не было в ней маршрутизации, и сейчас тоже нету, а посему приходится коммутатору отправлять пакеты данных во все порты – ну, чтобы наверняка. От адресата приходит ответ на определенный порт, коммутатор запоминает соответствие [порт — адресат] и следующая “посылка” отправляется уже не абы куда, а по памятным, так сказать, местам.
Если же ответа нет, а в момент отправки unknown unicast пара-тройка коммутаторов оказываются замкнуты в кольцо, посылка возвращается “отправителю”, который, понятно, снова забрасывает ее во все порты, поскольку ну а что ему еще делать. «Бесхозный» пакет данных опять возвращается и опять улетает. Каждый следующий виток “закольцованного” broadcast flood сопровождается экспоненциальным ростом количества пакетов в сегменте сети. Очень скоро эта лавина «забивает» полосу пропускания портов, на заднем плане красиво «вскипают» перегруженные процессоры коммутаторов – и ваша сеть превращается в памятник самой себе.
Причиной шторма может стать как хакерская атака, так и осечка вашего же инженера при настройке оборудования – или вовсе сбой протоколов. Иными словами, никто не застрахован.
Был такой случай
В 2009 году в сети одного из наших клиентов случился бродкастовый шторм, который мгновенно перекинулся к нам, парализовав работу всей сети передачи данных компании. Отвалились почта, телефония и интернет, система мониторинга «сошла с ума» – и стало невозможно даже локализовать «первоисточник». Полная перезагрузка коммутатора не помогла. Нам ничего не оставалось, кроме как последовательно отключать ВСЕ порты, клиентские и свои собственные… Такой вот «черный понедельник».
Как позже выяснилось, один из сотрудников клиента перепутал порты оборудования – и закольцевал свою топологию на уровне бродкастового домена. Бывает.
Понятно, что в группе риска здесь, в первую очередь, коммерческие ЦОДы: резервированное подключение для каждого клиента само по себе уже означает избыточность соединений между коммутаторами. Однако сетевикам корпоративных дата-центров я бы также не рекомендовал расслабляться: замкнуть по рассеянности пару коммутаторов друг на друга можно и в серверной.
Хорошая новость заключается в том, что при грамотной подготовке вы можете отделаться легким испугом там, где в противном случае получили бы простой сервиса.
С чего начать
Начните с сегментирования сети посредством VLAN: когда сеть разбита на мелкие изолированные сегменты (fault domain), шторм, “накрывший” один из участков, этим участком и ограничивается. Ну, в идеале. В действительности мощный шторм, увы, способен “вбрасывать” пакеты и в так называемые независимые виртуальные сети тоже.
По-хорошему здесь нужно отказаться от “закольцованных” VLAN как внутри собственной инфраструктуры, так и при подключении клиентов к сети (если речь о коммерческом ЦОД). Например, использовать протоколы FHRP и U-образную топологию на уровне доступа.
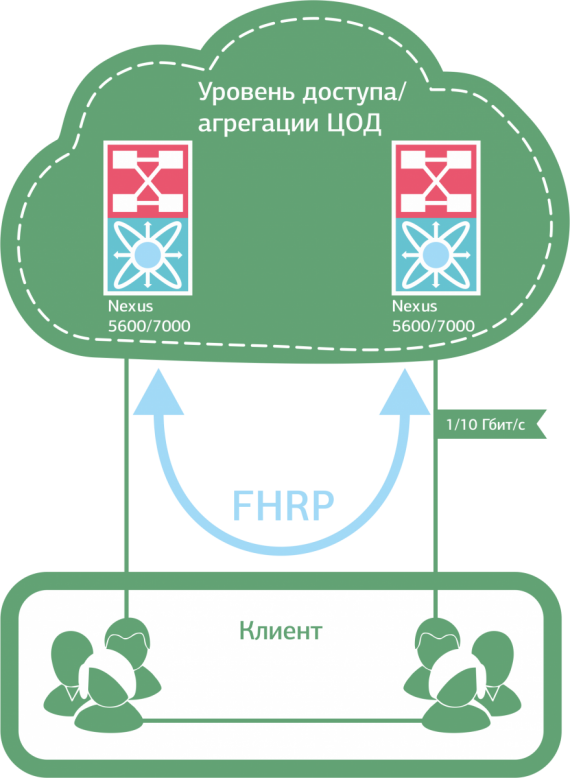
U-образная топология позволяет избежать закольцованности
В ряде случаев, впрочем, от «закольцованности» при всем желании никуда не деться. Скажем, необходимо развернуть отказоустойчивую (2N) инфраструктуру для заказчика с подключением к нашему облаку. Клиентские VLAN’ы здесь приходится «пробрасывать» внутри облачной инфраструктуры между всеми ESXi хостами кластера виртуализации, – то есть само решение подразумевает полное дублирование всех сетевых элементов.
Смотрим в картинку – видим кольцо.
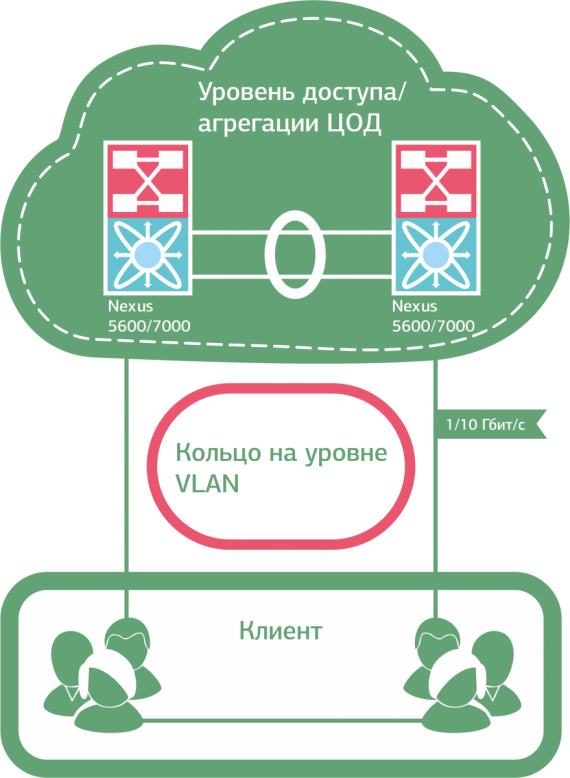
Кольцевая топология возникает при полном резервировании каналов связи и инфраструктуры заказчика
Что делать, если вы – «властелин колец»
Делать можно разное, и у каждого варианта, как водится, — свои преимущества и издержки.
Вот, например, протокол RSTP (модификация SpanningTreeProtocol) умеет быстро – в пределах 6 секунд – находить и «разбивать» бродкастовые петли. Находит он их посредством обмена BPDU (Bridge Protocol Data Unit) сообщениями между коммутаторами, а “разбивает” блокировкой резервных линков. В случае проблем с основным каналом RTSP перестраивает топологию, используя резервный порт.
Хорошая в целом штука, но есть нюанс. Под каждый VLAN выделяется один RSTP-процесс, при этом количество процессов, в отличие от VLAN, сильно ограничено, и при резком росте числа VLAN'ов в рамках одной сетки процессов RSTP может банально не хватить. То есть для корпоративного дата-центра пойдет, а для коммерческого – с постоянно растущим числом клиентов (VLAN) – уже не очень.
На этот случай имеется MSTP – улучшенное и дополненное издание RSTP. Умеет объединять несколько VLAN в один STP процесс (instance), что в хорошем смысле слова сказывается на масштабируемости сети: “потолок” здесь составляет 4096 клиентов (максимальное число VLAN). MSTP также позволяет управлять трафиком, распределяя MST процессы между основным линком и резервным, и дает возможность при необходимости разгружать “загнавшиеся” коммутаторы. Однако с MST нужно уметь работать, то есть это плюс как минимум один недешевый умник в штат (что доступно не всем).
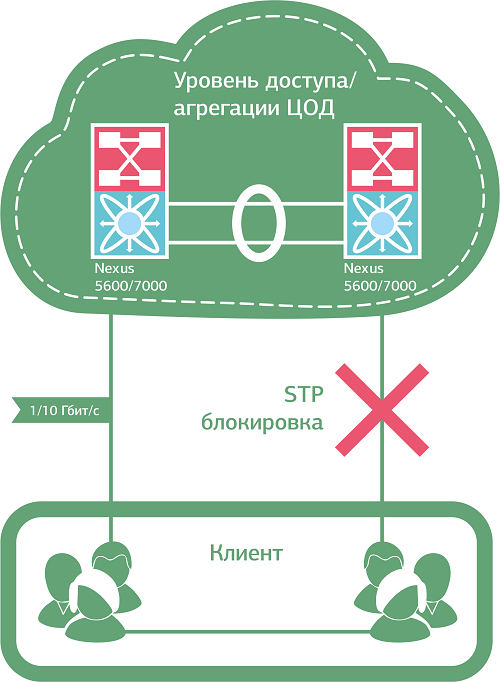
Протоколы RSTP и MST «разрывают» петлю, блокируя трафик по одному из каналов
Из проверенных альтернатив MSTP могу посоветовать FlexLinks от Cisco, который мы используем, когда на стороне клиента находится один коммутатор или стек под единым управлением. FlexLinks умеет резервировать линки коммутатора без применения STP, “назначая” в каждой паре портов основной и резервный. Используется на уровне доступа (access) при подключении оборудования разных компаний по принципу Looped Triangle в коммерческом ЦОД. Очень простой в плане настройки инструмент, что и само по себе приятно, и позволяет рассчитывать на бОльшую стабильность сервиса (по сравнению, например, с STP). Вы полюбите FlexLinks за мгновенное переключение на резервные линки и балансировку нагрузки по VLAN – а потом, возможно, разлюбите за возможность применять его исключительно в топологии Looped Triangle.
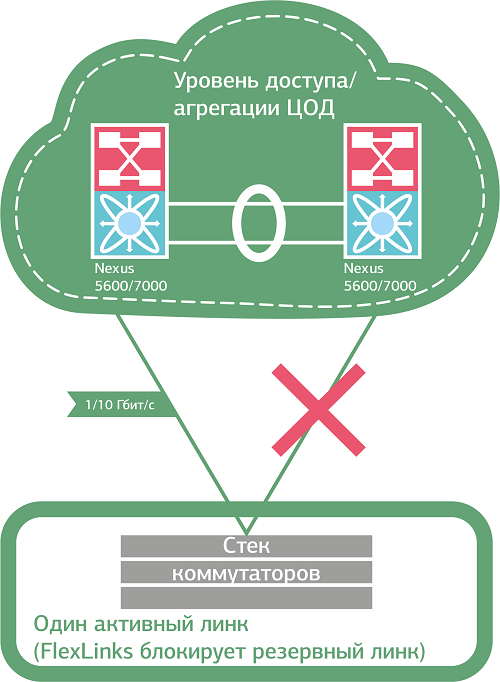
В топологии Looped Triangle можно добиться мгновенного переключения трафика между каналами в случае сбоя
Теперь отвлечемся от техники. Любите ли вы экономическую эффективность так же, как люблю ее я? Тогда вам будет интересно узнать, что и MST \ RSTP, и FlexLinks, блокируя резервные линки, фактически исключают половину портов из круговорота трафика в природе.
А вот решения, которые так не делают: Cisco VSS (Virtual Switch System), Nexus vPC (virtual port-channel), Juniper virtual router и другие mLAG-подобные (multichassis link aggregation) технологии. Хороши тем, что задействует все доступные линки, объединяя их в один логический канал EtherChannel. Получается своего рода коммутирующий кластер, в котором модуль управления одного из коммутаторов (Control-plane) “рулит” всеми линками кластера (Data-Plane). В случае выхода текущего Control-plane из строя его полномочия автоматически передаются “оставшемуся в живых”. Мы используем Cisco Nexus vPC для балансировки нагрузки между линками клиентов, у которых по одному коммутатору или стеку. Если же на стороне клиента два отдельных коммутатора, связанных общим VLAN, добавляем в схему STP.
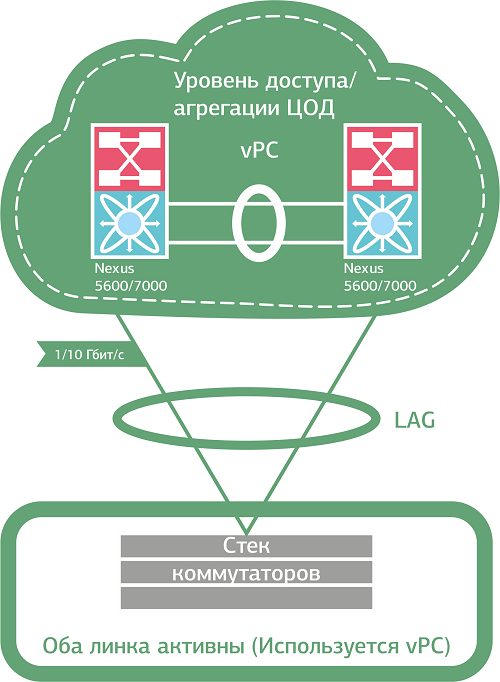
Объединение линков в один логический канал решает проблему со штормами и не сказывается на производительности
Если у вас облака
Виртуализация, катастрофоустойчивые облачные сервисы, распределенные между дата-центрами, и прочие кластерные решения – все это требует несколько иного подхода к организации Layer 2 сети. Убираем STP на антресоли – достаем TRILL.
TRILL использует механизм маршрутизации на Ethernet-уровне и сама строит свободный от петель путь для бродкастового трафика, тем самым предотвращая возникновение штормов. Ну не чудо ли? J Еще TRILL позволяет равномерно распределять нагрузку между линками (до 16 линков), объединять распределенные дата-центры в единую L2-сеть и гибко управлять трафиком. TRILL – общепринятый стандарт, у которого быстро появились вендорские варианты: FabricPath от Cisco (который используем мы) и QFabric от Juniper.
Контрольный выстрел
Какой протокол даст вам 100% защиту от шторма? Правильно, никакой. Поэтому, возможно, вас заинтересуют следующие два инструмента:
Как построить death proof сеть
Итак, какие из возможных вариантов мы проверили на себе и используем в зависимости от вводных:
U, V и П-образные топологии + RSTP (MST) + storm control + CoPP.
Базовый набор, в первую очередь, для коммерческого ЦОД, в котором приходится подключать к собственной сети большое количество внешних (неконтролируемых) сетей – и потому крайне желательно не допускать возникновения «петель» вообще. Если U, V и П-образные топологии не ваш случай, «сокращенный» вариант RSTP (MST) + storm control + CoPP тоже подойдет.
Главное – начать делать хоть что-то уже сейчас, даже если вам искренне кажется, что бродкастовый шторм это то, что бывает с другими. В реальности штормы «накрывают» сети самых разных масштабов, а нелепые ошибки совершают даже люди, которые, что называется, двадцать лет в искусстве. «И пусть это вдохновит вас на подвиг» ©.
Откуда есть пошла
Вначале была Ethernet, и не было в ней маршрутизации, и сейчас тоже нету, а посему приходится коммутатору отправлять пакеты данных во все порты – ну, чтобы наверняка. От адресата приходит ответ на определенный порт, коммутатор запоминает соответствие [порт — адресат] и следующая “посылка” отправляется уже не абы куда, а по памятным, так сказать, местам.
Если же ответа нет, а в момент отправки unknown unicast пара-тройка коммутаторов оказываются замкнуты в кольцо, посылка возвращается “отправителю”, который, понятно, снова забрасывает ее во все порты, поскольку ну а что ему еще делать. «Бесхозный» пакет данных опять возвращается и опять улетает. Каждый следующий виток “закольцованного” broadcast flood сопровождается экспоненциальным ростом количества пакетов в сегменте сети. Очень скоро эта лавина «забивает» полосу пропускания портов, на заднем плане красиво «вскипают» перегруженные процессоры коммутаторов – и ваша сеть превращается в памятник самой себе.
Причиной шторма может стать как хакерская атака, так и осечка вашего же инженера при настройке оборудования – или вовсе сбой протоколов. Иными словами, никто не застрахован.
Был такой случай
В 2009 году в сети одного из наших клиентов случился бродкастовый шторм, который мгновенно перекинулся к нам, парализовав работу всей сети передачи данных компании. Отвалились почта, телефония и интернет, система мониторинга «сошла с ума» – и стало невозможно даже локализовать «первоисточник». Полная перезагрузка коммутатора не помогла. Нам ничего не оставалось, кроме как последовательно отключать ВСЕ порты, клиентские и свои собственные… Такой вот «черный понедельник».
Как позже выяснилось, один из сотрудников клиента перепутал порты оборудования – и закольцевал свою топологию на уровне бродкастового домена. Бывает.
Понятно, что в группе риска здесь, в первую очередь, коммерческие ЦОДы: резервированное подключение для каждого клиента само по себе уже означает избыточность соединений между коммутаторами. Однако сетевикам корпоративных дата-центров я бы также не рекомендовал расслабляться: замкнуть по рассеянности пару коммутаторов друг на друга можно и в серверной.
Хорошая новость заключается в том, что при грамотной подготовке вы можете отделаться легким испугом там, где в противном случае получили бы простой сервиса.
С чего начать
Начните с сегментирования сети посредством VLAN: когда сеть разбита на мелкие изолированные сегменты (fault domain), шторм, “накрывший” один из участков, этим участком и ограничивается. Ну, в идеале. В действительности мощный шторм, увы, способен “вбрасывать” пакеты и в так называемые независимые виртуальные сети тоже.
По-хорошему здесь нужно отказаться от “закольцованных” VLAN как внутри собственной инфраструктуры, так и при подключении клиентов к сети (если речь о коммерческом ЦОД). Например, использовать протоколы FHRP и U-образную топологию на уровне доступа.
U-образная топология позволяет избежать закольцованности
В ряде случаев, впрочем, от «закольцованности» при всем желании никуда не деться. Скажем, необходимо развернуть отказоустойчивую (2N) инфраструктуру для заказчика с подключением к нашему облаку. Клиентские VLAN’ы здесь приходится «пробрасывать» внутри облачной инфраструктуры между всеми ESXi хостами кластера виртуализации, – то есть само решение подразумевает полное дублирование всех сетевых элементов.
Смотрим в картинку – видим кольцо.
Кольцевая топология возникает при полном резервировании каналов связи и инфраструктуры заказчика
Что делать, если вы – «властелин колец»
Делать можно разное, и у каждого варианта, как водится, — свои преимущества и издержки.
Вот, например, протокол RSTP (модификация SpanningTreeProtocol) умеет быстро – в пределах 6 секунд – находить и «разбивать» бродкастовые петли. Находит он их посредством обмена BPDU (Bridge Protocol Data Unit) сообщениями между коммутаторами, а “разбивает” блокировкой резервных линков. В случае проблем с основным каналом RTSP перестраивает топологию, используя резервный порт.
Хорошая в целом штука, но есть нюанс. Под каждый VLAN выделяется один RSTP-процесс, при этом количество процессов, в отличие от VLAN, сильно ограничено, и при резком росте числа VLAN'ов в рамках одной сетки процессов RSTP может банально не хватить. То есть для корпоративного дата-центра пойдет, а для коммерческого – с постоянно растущим числом клиентов (VLAN) – уже не очень.
На этот случай имеется MSTP – улучшенное и дополненное издание RSTP. Умеет объединять несколько VLAN в один STP процесс (instance), что в хорошем смысле слова сказывается на масштабируемости сети: “потолок” здесь составляет 4096 клиентов (максимальное число VLAN). MSTP также позволяет управлять трафиком, распределяя MST процессы между основным линком и резервным, и дает возможность при необходимости разгружать “загнавшиеся” коммутаторы. Однако с MST нужно уметь работать, то есть это плюс как минимум один недешевый умник в штат (что доступно не всем).
Протоколы RSTP и MST «разрывают» петлю, блокируя трафик по одному из каналов
Из проверенных альтернатив MSTP могу посоветовать FlexLinks от Cisco, который мы используем, когда на стороне клиента находится один коммутатор или стек под единым управлением. FlexLinks умеет резервировать линки коммутатора без применения STP, “назначая” в каждой паре портов основной и резервный. Используется на уровне доступа (access) при подключении оборудования разных компаний по принципу Looped Triangle в коммерческом ЦОД. Очень простой в плане настройки инструмент, что и само по себе приятно, и позволяет рассчитывать на бОльшую стабильность сервиса (по сравнению, например, с STP). Вы полюбите FlexLinks за мгновенное переключение на резервные линки и балансировку нагрузки по VLAN – а потом, возможно, разлюбите за возможность применять его исключительно в топологии Looped Triangle.
В топологии Looped Triangle можно добиться мгновенного переключения трафика между каналами в случае сбоя
Теперь отвлечемся от техники. Любите ли вы экономическую эффективность так же, как люблю ее я? Тогда вам будет интересно узнать, что и MST \ RSTP, и FlexLinks, блокируя резервные линки, фактически исключают половину портов из круговорота трафика в природе.
А вот решения, которые так не делают: Cisco VSS (Virtual Switch System), Nexus vPC (virtual port-channel), Juniper virtual router и другие mLAG-подобные (multichassis link aggregation) технологии. Хороши тем, что задействует все доступные линки, объединяя их в один логический канал EtherChannel. Получается своего рода коммутирующий кластер, в котором модуль управления одного из коммутаторов (Control-plane) “рулит” всеми линками кластера (Data-Plane). В случае выхода текущего Control-plane из строя его полномочия автоматически передаются “оставшемуся в живых”. Мы используем Cisco Nexus vPC для балансировки нагрузки между линками клиентов, у которых по одному коммутатору или стеку. Если же на стороне клиента два отдельных коммутатора, связанных общим VLAN, добавляем в схему STP.
Объединение линков в один логический канал решает проблему со штормами и не сказывается на производительности
Если у вас облака
Виртуализация, катастрофоустойчивые облачные сервисы, распределенные между дата-центрами, и прочие кластерные решения – все это требует несколько иного подхода к организации Layer 2 сети. Убираем STP на антресоли – достаем TRILL.
TRILL использует механизм маршрутизации на Ethernet-уровне и сама строит свободный от петель путь для бродкастового трафика, тем самым предотвращая возникновение штормов. Ну не чудо ли? J Еще TRILL позволяет равномерно распределять нагрузку между линками (до 16 линков), объединять распределенные дата-центры в единую L2-сеть и гибко управлять трафиком. TRILL – общепринятый стандарт, у которого быстро появились вендорские варианты: FabricPath от Cisco (который используем мы) и QFabric от Juniper.
Контрольный выстрел
Какой протокол даст вам 100% защиту от шторма? Правильно, никакой. Поэтому, возможно, вас заинтересуют следующие два инструмента:
- Storm-control
- Control—plane policing (CoPP)
Как построить death proof сеть
Итак, какие из возможных вариантов мы проверили на себе и используем в зависимости от вводных:
U, V и П-образные топологии + RSTP (MST) + storm control + CoPP.
Базовый набор, в первую очередь, для коммерческого ЦОД, в котором приходится подключать к собственной сети большое количество внешних (неконтролируемых) сетей – и потому крайне желательно не допускать возникновения «петель» вообще. Если U, V и П-образные топологии не ваш случай, «сокращенный» вариант RSTP (MST) + storm control + CoPP тоже подойдет.
- Если есть задача максимально использовать возможности оборудования и каналов, присмотритесь к варианту mLAG (VSS, vPC) + storm control + CoPP.
- Если у вас уже имеется оборудование Cisco или Juniper и нет противопоказаний по топологии, попробуйте комбинацию Flex Links/RTG + storm control + CoPP.
- Если у вас сложносочиненный случай с распределенными площадками и прочими изысками виртуализации и отказоустойчивости, ваш вариант TRILL + storm control + CoPP.
- Если вы не знаете, какой у вас случай, – мы можем поговорить об этом J.
Главное – начать делать хоть что-то уже сейчас, даже если вам искренне кажется, что бродкастовый шторм это то, что бывает с другими. В реальности штормы «накрывают» сети самых разных масштабов, а нелепые ошибки совершают даже люди, которые, что называется, двадцать лет в искусстве. «И пусть это вдохновит вас на подвиг» ©.
0 комментариев
Вставка изображения
Оставить комментарий