R & D и отзывы клиентов развивают OverTheBox
Первоначально было доказано, что доказательство концепции объединения интернет-соединений для обеспечения лучшей пропускной способности стало все более необходимым решением для продвижения облачных приложений, требующих высоких скоростей, и для преодоления цифрового разрыва. К тому моменту, когда OverTheBox недавно испытал новую версию.
«Что делает меня самым гордым, так это то, что TheOverTheBox (OTB) — это чистый проект наших исследований и разработок и обогащенный обратной связью с клиентами», — говорит Башир Эсса, инженер-исследователь по телекоммуникациям в OVH. Первоначальная идея заключалась в том, чтобы найти продукт, который обеспечит его доступ в Интернет и увеличит его скорость. После многих исследований и тестов появилась первая версия OverTheBox. «С течением времени появились новые идеи. Клиенты сделали много возвратов использования, которые мы приняли во внимание, потому что использование первой версии OTB было «слишком сложным» для подавляющего большинства пользователей. И с нашей стороны, мы, вундеркинды R & D, мы всегда ищем прирост производительности и добавленные функции, микро-настройки. С этими двумя дополнительными предубеждениями мы пришли ко второй версии OTB. "
В частности, новая версия изначально в 3 раза мощнее, чем ее предшественница, с максимальной зашифрованной скоростью 400 Мбит / с против 130 прежде, благодаря использованию очень мощного и недавнего сообщества, поэтому недавнее, что это должен был изменить наше ядро, чтобы иметь возможность отключить окно!
Среди других новинок коммутатор был интегрирован на передней панели, он является важным компонентом для упрощения конфигурации, поскольку клиентам больше не нужно отключать DHCP своих ящиков для работы службы, которая была черная точка v1. Этот коммутатор имеет 14 портов, в том числе 2 WAN по умолчанию, но все легко модифицируется клиентом, если он пожелает. Эргономика корпуса также была пересмотрена, чтобы предложить «стойкий» формат. Это подходит для наших новых профессиональных клиентов, которые полагаются на OTB для своей сети.
Аппаратная часть является лишь частью нового OTBv2, который поставляется с полной реорганизацией системы. Однако эта система остается очень сложной, и ее разработка по-прежнему пытается максимально упростить ее.
Адриен Галлоу, разработчик OTB, поднимает капюшон для любопытных, чтобы понять, как все это работает.
В OTBv2 есть две технологии агрегации. С одной стороны, MPTCP, основанный на TCP, позволяет объединять только TCP-соединения, а с другой, MUD, основанный на UDP, позволяет агрегировать все протоколы. Каждая из этих технологий имеет разные характеристики. MPTCP пытается максимизировать пропускную способность, поддерживая хорошую задержку, в то время как MUD пытается минимизировать задержку, пытаясь сохранить хороший битрейт.
Первая версия OTB запускалась в туннеле TCP для трафика, отличного от TCP (который не агрегируется MPTCP). Агрегация пожертвовала латентностью в пользу пропускной способности, что не всегда соответствовало трафику, особенно VoIP. Поэтому мы добавили новый туннель на основе MUD для агрегирования чувствительных к задержкам сообщений (и, в частности, дрожания).
Мы предлагаем три различные технологии агрегации:
Выбор режима агрегации осуществляется через DSCP и полностью настраивается клиентом, но мы предлагаем конфигурацию по умолчанию, достаточную для обычных целей.
Одна из главных критических замечаний, высказанных клиентами, через форумы или во время событий, особенно в ходе Саммита 2017 года, действительно была сложностью конфигурации. «Первая версия потребовала много настроек и предоставила пользователю возможность настраивать практически любой параметр», — говорит Grégoire Delattre, DevOps по проекту с самого начала. Это предполагает, что он сам знает, что у него есть навыки, в противном случае риск велик, что он не может получить желаемое качество. Вот почему для этой второй версии мы выбрали конфигурацию, предложенную по умолчанию. Это намного проще для подавляющего большинства пользователей, и полученные результаты в среднем намного лучше. Разумеется, самая знающая воля всегда будет в состоянии настраивать и настраивать по своему усмотрению, как объяснил Адриен.
«Мы всегда хотим сделать лучше. У нас уже есть другие потенциальные улучшения, такие как интеграция решения частной сети vRack в службу OverTheBox, чтобы сделать OTB шлюзом для всех служб OVH, — говорит Grégoire. Тем временем, версия 2 выполняет свои обещания в том смысле, что клиент, который вызвал нас при малейшем падении потока, который он нашел, никогда не связывается с нами сейчас, потому что его решение OTB автоматически решает проблему! ».
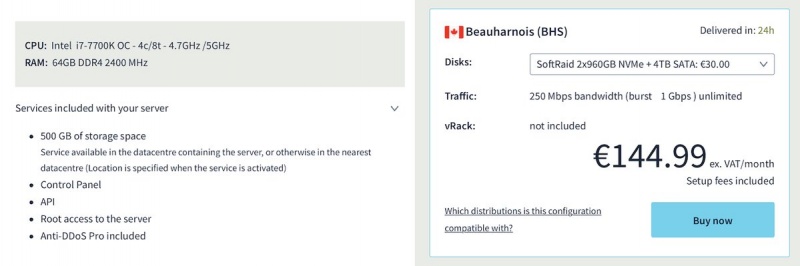
Что касается предложений, теперь предлагаются три решения, и поскольку OverTheBox был разработан с открытым исходным кодом, можно подписаться только на ежемесячную подписку, не покупая ящик. Просто загрузите исходный код программного обеспечения и установите его на совместимое стороннее оборудование. Для тех, кто уже имеет первую версию и хочет перейти на новую, просто обратитесь в службу поддержки, которая будет выполнять необходимую миграцию. Если клиент удовлетворен v1 и не нуждается в большей стабильности и мощности, он всегда жизнеспособен и обновляется.
«Что делает меня самым гордым, так это то, что TheOverTheBox (OTB) — это чистый проект наших исследований и разработок и обогащенный обратной связью с клиентами», — говорит Башир Эсса, инженер-исследователь по телекоммуникациям в OVH. Первоначальная идея заключалась в том, чтобы найти продукт, который обеспечит его доступ в Интернет и увеличит его скорость. После многих исследований и тестов появилась первая версия OverTheBox. «С течением времени появились новые идеи. Клиенты сделали много возвратов использования, которые мы приняли во внимание, потому что использование первой версии OTB было «слишком сложным» для подавляющего большинства пользователей. И с нашей стороны, мы, вундеркинды R & D, мы всегда ищем прирост производительности и добавленные функции, микро-настройки. С этими двумя дополнительными предубеждениями мы пришли ко второй версии OTB. "
В частности, новая версия изначально в 3 раза мощнее, чем ее предшественница, с максимальной зашифрованной скоростью 400 Мбит / с против 130 прежде, благодаря использованию очень мощного и недавнего сообщества, поэтому недавнее, что это должен был изменить наше ядро, чтобы иметь возможность отключить окно!
Среди других новинок коммутатор был интегрирован на передней панели, он является важным компонентом для упрощения конфигурации, поскольку клиентам больше не нужно отключать DHCP своих ящиков для работы службы, которая была черная точка v1. Этот коммутатор имеет 14 портов, в том числе 2 WAN по умолчанию, но все легко модифицируется клиентом, если он пожелает. Эргономика корпуса также была пересмотрена, чтобы предложить «стойкий» формат. Это подходит для наших новых профессиональных клиентов, которые полагаются на OTB для своей сети.
Аппаратная часть является лишь частью нового OTBv2, который поставляется с полной реорганизацией системы. Однако эта система остается очень сложной, и ее разработка по-прежнему пытается максимально упростить ее.
Адриен Галлоу, разработчик OTB, поднимает капюшон для любопытных, чтобы понять, как все это работает.
В OTBv2 есть две технологии агрегации. С одной стороны, MPTCP, основанный на TCP, позволяет объединять только TCP-соединения, а с другой, MUD, основанный на UDP, позволяет агрегировать все протоколы. Каждая из этих технологий имеет разные характеристики. MPTCP пытается максимизировать пропускную способность, поддерживая хорошую задержку, в то время как MUD пытается минимизировать задержку, пытаясь сохранить хороший битрейт.
Первая версия OTB запускалась в туннеле TCP для трафика, отличного от TCP (который не агрегируется MPTCP). Агрегация пожертвовала латентностью в пользу пропускной способности, что не всегда соответствовало трафику, особенно VoIP. Поэтому мы добавили новый туннель на основе MUD для агрегирования чувствительных к задержкам сообщений (и, в частности, дрожания).
Мы предлагаем три различные технологии агрегации:
- прокси-сервер TCP, который позволяет агрегировать весь TCP-трафик с помощью MPTCP;
- TCP-туннель, который позволяет собирать не-TCP-трафик, но не чувствительный к задержке и джиттеру;
- туннель UDP, который позволяет агрегировать все остальное.
Выбор режима агрегации осуществляется через DSCP и полностью настраивается клиентом, но мы предлагаем конфигурацию по умолчанию, достаточную для обычных целей.
Одна из главных критических замечаний, высказанных клиентами, через форумы или во время событий, особенно в ходе Саммита 2017 года, действительно была сложностью конфигурации. «Первая версия потребовала много настроек и предоставила пользователю возможность настраивать практически любой параметр», — говорит Grégoire Delattre, DevOps по проекту с самого начала. Это предполагает, что он сам знает, что у него есть навыки, в противном случае риск велик, что он не может получить желаемое качество. Вот почему для этой второй версии мы выбрали конфигурацию, предложенную по умолчанию. Это намного проще для подавляющего большинства пользователей, и полученные результаты в среднем намного лучше. Разумеется, самая знающая воля всегда будет в состоянии настраивать и настраивать по своему усмотрению, как объяснил Адриен.
«Мы всегда хотим сделать лучше. У нас уже есть другие потенциальные улучшения, такие как интеграция решения частной сети vRack в службу OverTheBox, чтобы сделать OTB шлюзом для всех служб OVH, — говорит Grégoire. Тем временем, версия 2 выполняет свои обещания в том смысле, что клиент, который вызвал нас при малейшем падении потока, который он нашел, никогда не связывается с нами сейчас, потому что его решение OTB автоматически решает проблему! ».
Что касается предложений, теперь предлагаются три решения, и поскольку OverTheBox был разработан с открытым исходным кодом, можно подписаться только на ежемесячную подписку, не покупая ящик. Просто загрузите исходный код программного обеспечения и установите его на совместимое стороннее оборудование. Для тех, кто уже имеет первую версию и хочет перейти на новую, просто обратитесь в службу поддержки, которая будет выполнять необходимую миграцию. Если клиент удовлетворен v1 и не нуждается в большей стабильности и мощности, он всегда жизнеспособен и обновляется.