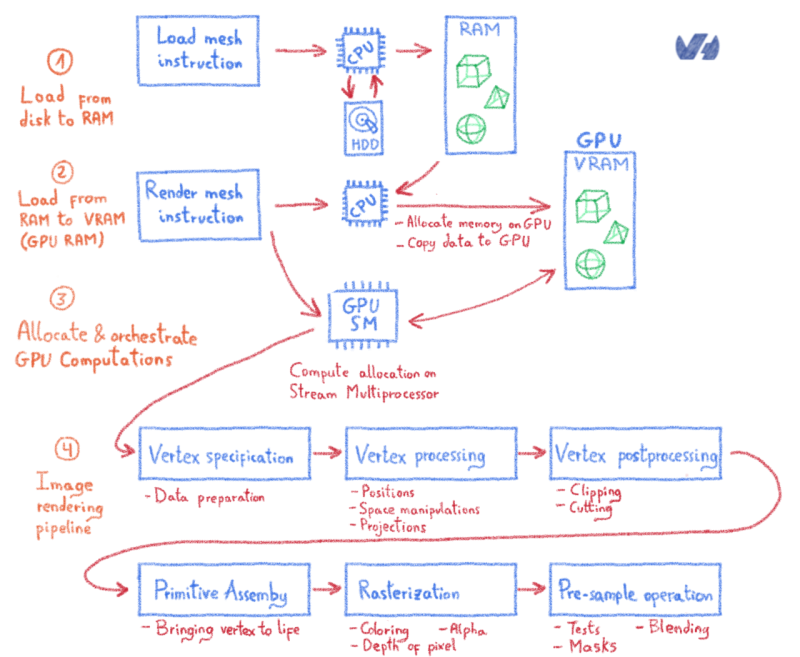
Федерация — это бета-функция, предлагаемая всем пользователям OVH Private Cloud с vCenter 6.5. Если вы хотите принять участие в бета-тестировании, свяжитесь с нашей службой поддержки. Это позволяет использовать внешний Microsoft Active Directory в качестве источника аутентификации для доступа к серверу VMware vCenter. Реализация этой функции стала возможной благодаря команде DevOps OVH, которая разработала инновационный и уникальный API, который добавляет дополнительные функции к тем, которые предлагает VMware. Действительно, в настоящее время невозможно настроить источники удостоверений через собственный API vCenter.
Зачем?
По умолчанию права доступа к vCenter в частном облаке управляются непосредственно этим vCenter. Пользователи создаются локально (localos или домен SSO), а все механизмы управления на основе доступа (RBAC) управляются службой SSO. Включение федерации делегирует управление пользователями в Microsoft Active Directory (AD). В результате сервер vCenter будет взаимодействовать с контроллером домена, чтобы гарантировать, что пользователь, пытающийся подключиться, является тем, кем он себя считает. VCenter сохраняет управление ролями и привилегиями для объектов, которыми он управляет. После настройки федерации можно связать пользователей AD с ролями vCenter, чтобы они могли получать доступ и / или управлять определенными объектами в инфраструктуре (виртуальные машины, сети, папки и т. Д.).
Одним из основных применений этого будет облегчение доступа vCenter для администраторов за счет сокращения количества учетных записей, необходимых для поддержки различных элементов инфраструктуры. Кроме того, станет возможным расширить и унифицировать политику управления паролями между Active Directory и vCenter Private Cloud.
Тот факт, что Федерацией можно управлять через API OVH, позволяет автоматизировать конфигурацию, а также обеспечить ее поддержание в рабочем состоянии. Наконец, очень просто добавить проверки в любой инструмент мониторинга (Nagios, Zabbix, Sensu и т. Д.), Чтобы отслеживать состояние Федерации и права, назначенные пользователям.
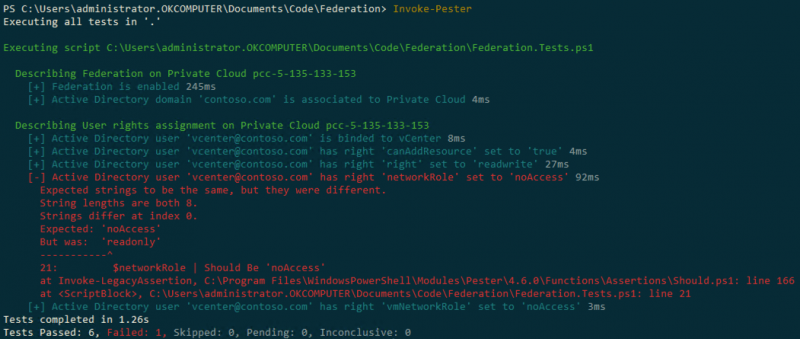
Вот пример простого скрипта PowerShell, который будет периодически проверять, находится ли конфигурация федерации в желаемом состоянии:
 Архитектура и предпосылки
Архитектура и предпосылки
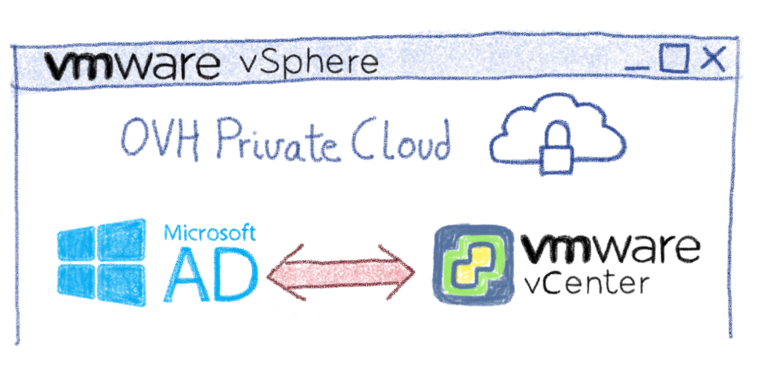
Поскольку vCenter должен будет обмениваться данными с контроллерами домена, первым шагом будет разрешение потоков между этими элементами. Есть несколько способов достижения этой цели, например, объединение OVHCloud Connect с частным шлюзом. Изучение всех этих возможностей потребует целой статьи, поэтому мы советуем вам связаться с OVH или одним из наших партнеров, чтобы помочь вам выбрать наиболее подходящую архитектуру. Следующая диаграмма дает вам упрощенный обзор того, как это может выглядеть:
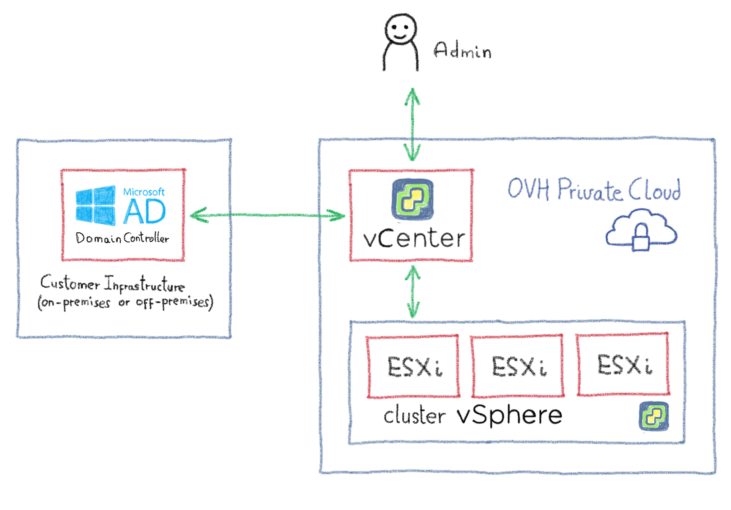
После подключения вам необходимо убедиться, что вы собрали следующую информацию перед началом процесса настройки:
- Ваши учетные данные OVH (ник и пароль)
- Название вашего частного облака (в форме pcc-X-X-X-X)
- Требуемая информация об инфраструктуре Active Directory, а именно:
- Короткое и длинное имя домена Active Directory (например, contoso и contoso.com)
- IP-адрес контроллера домена
- Имя пользователя и пароль учетной записи AD с достаточными правами для просмотра каталога
- Расположение групп и пользователей в иерархии AD как «базовое DN» (пример: OU = Users, DC = contoso, DC = com). Следует отметить, что хотя информация о группе является обязательной, в настоящее время ее невозможно использовать для управления аутентификацией.
- Список пользователей Active Directory, которых вы хотите привязать к vCenter. Необходимо будет указать имена пользователей в форме username@FQDN.domain (например, federation@contoso.com).
Обратите внимание, что в настоящее время невозможно иметь несколько пользователей с одним и тем же коротким именем, независимо от того, управляются ли они локально или с помощью Active Directory.
Активация и настройка
Как только вы соберете всю необходимую информацию, появится возможность активировать и настроить Федерацию. Операция будет проходить в три этапа:
- Активация связи между Active Directory и частным облаком
- Привязка одного или нескольких пользователей AD к частному облаку
- Назначение прав пользователям
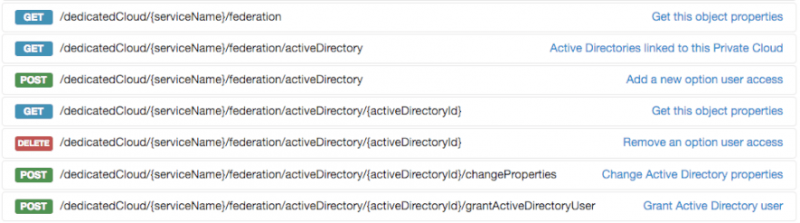
На данный момент конфигурация доступна только через API OVH, но в среднесрочной перспективе должна быть возможность сделать это через Панель управления OVH. API предлагает все необходимые опции для активации, настройки или даже удаления федерации вашего частного облака:
 Включение соединения между AD и частным облаком
Включение соединения между AD и частным облаком
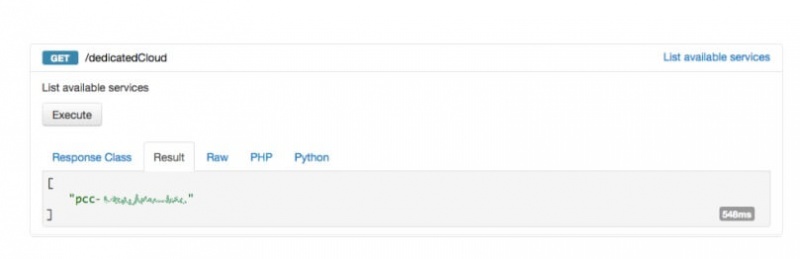
Перейдите на сайт обозревателя API и выполните аутентификацию, используя свои учетные данные OVH. Если у вас его еще нет, получите имя (также называемое serviceName в API) вашего частного облака, так как оно будет обязательным для всех остальных этапов настройки. Вы можете получить доступ к этой информации, выполнив GET для /edicCloud URI:
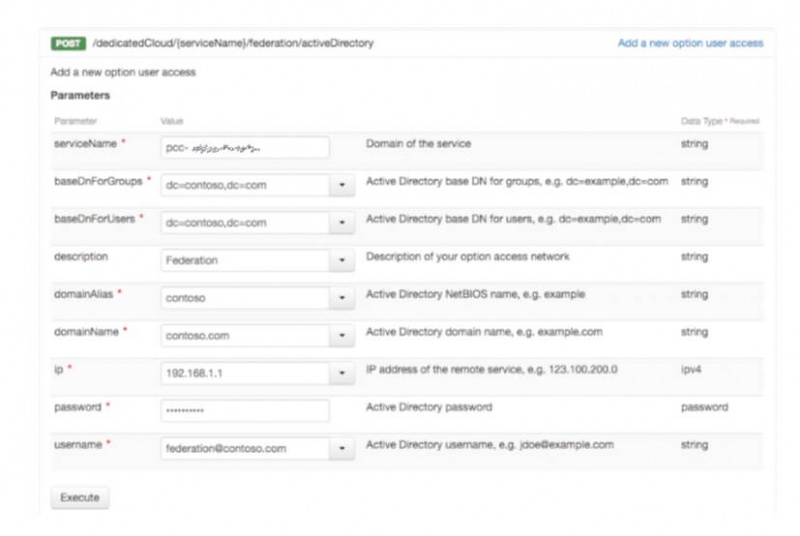
Включите федерацию, предоставив всю информацию о вашей Active Directory через POST в URI /edicCloud / {имя_службы} / federation / activeDirectory. Вся запрашиваемая информация обязательна:
Активация федерации займет некоторое время и пройдет в фоновом режиме. Вы можете следить за ходом операции через панель управления OVH:
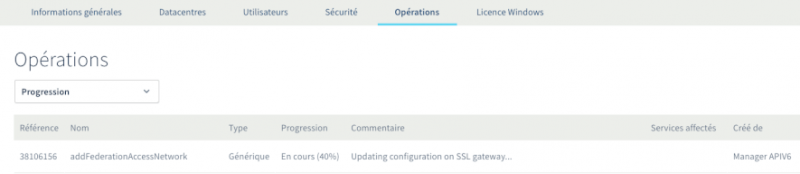
По завершении вы можете получить идентификатор федерации, отправив запрос GET на URI-адрес /edicCloud / {имя-службы} / federation / activeDirectory:
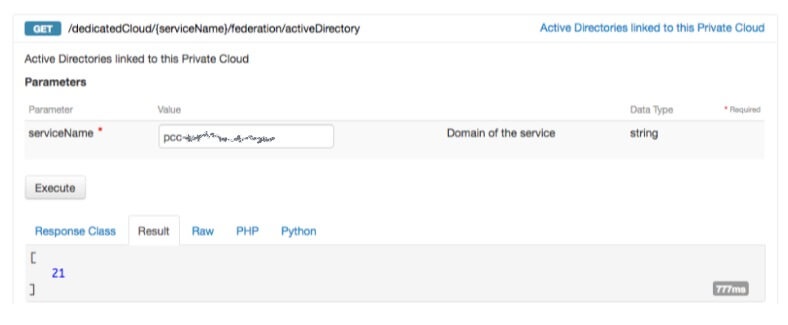 Связывание одного или нескольких пользователей AD
Связывание одного или нескольких пользователей AD
Теперь, когда ваша AD объявлена в vCenter Private Cloud, мы сможем привязать к ней пользователей Active Directory. Обратите внимание, что даже если ваши пользователи связаны, у них не будет связанных ролей vCenter, поэтому они не смогут войти в систему.
Чтобы связать пользователя, вам нужно будет отправить запрос POST в URI /edicCloud / {имя_службы} / federation / activeDirectory / {activeDirectory} / grantActiveDirectoryUser, указав полное имя пользователя:
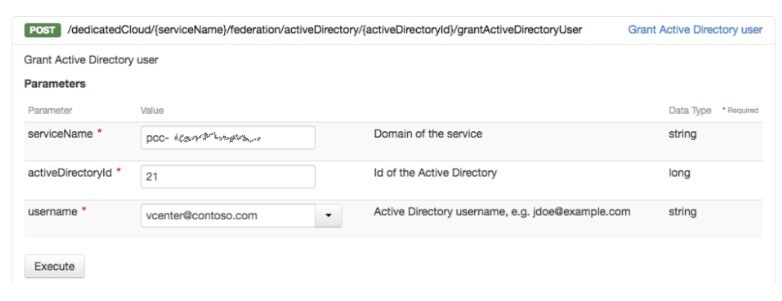
Убедитесь, что пользователь присутствует в поисковом подразделении, которое вы указали при сопоставлении вашей AD с vCenter. Еще раз, вы можете проверить, что задача импорта выполняется через API или через панель управления:

Назначение прав доступа
Последним шагом будет предоставление пользователям прав доступа к различным объектам в виртуальной инфраструктуре. Этот шаг не отличается от обычного способа управления правами пользователей Private Cloud. Это можно сделать через API или панель управления OVH.

Теперь вы сможете войти в vCenter с пользователями вашей AD и начать управлять своим частным облаком!