Serverless по стоечкам

Serverless ― это не про физическое отсутствие серверов. Это не «убийца» контейнеров и не мимолетный тренд. Это новый подход к построению систем в облаке. В сегодняшней статье коснемся архитектуры Serverless-приложений, посмотрим, какую роль играет провайдер Serverless-услуги и open-source проекты. В конце поговорим о вопросах применения Serverless.
Я хочу написать серверную часть приложения (да хоть интернет-магазина). Это может быть и чат, и сервис для публикации контента, и балансировщик нагрузки. В любом случае головной боли будет немало: придется подготовить инфраструктуру, определить зависимости приложения, задуматься насчет операционной системы хоста. Потом понадобится обновить небольшие компоненты, которые не затрагивают работу остального монолита. Ну и про масштабирование под нагрузкой не будем забывать.
А что если взять эфемерные контейнеры, в которых требуемые зависимости уже предустановлены, а сами контейнеры изолированы друг от друга и от ОС хоста? Монолит разобьем на микросервисы, каждый из которых можно обновлять и масштабировать независимо от других. Поместив код в такой контейнер, я смогу запускать его на любой инфраструктуре. Уже лучше.
А если не хочется настраивать контейнеры? Не хочется думать про масштабирование приложения. Не хочется платить за простой запущенных контейнеров, когда нагрузка на сервис минимальна. Хочется писать код. Сосредоточиться на бизнес-логике и выпускать продукты на рынок со скоростью света.
Такие мысли привели меня к бессерверным вычислениям. Serverless в данном случае означает не физическое отсутствие серверов, а отсутствие головной боли по управлению инфраструктурой.
Идея в том, что логика приложения разбивается на независимые функции. Они имеют событийную структуру. Каждая из функций выполняет одну «микрозадачу». Все, что требуется от разработчика ― загрузить функции в предоставленную облачным провайдером консоль и соотнести их с источниками событий. Код будет исполняться по запросу в автоматически подготовленном контейнере, а я заплачу только за время исполнения.
Давайте разберемся, как теперь будет выглядеть процесс разработки приложения.
Со стороны разработчика
Ранее мы начали говорить про приложение для интернет-магазина. В традиционном подходе основную логику системы выполняет монолитное приложение. И сервер с приложением запущен постоянно, даже если нагрузки нет.
Чтобы перейти к Serverless, разбиваем приложение на микрозадачи. Под каждую из них пишем свою функцию. Функции независимы друг от друга и не хранят информацию о состоянии (stateless). Они даже могут быть написаны на разных языках. Если одна из них «упадет», приложение целиком не остановится. Архитектура приложения будет выглядеть вот так:
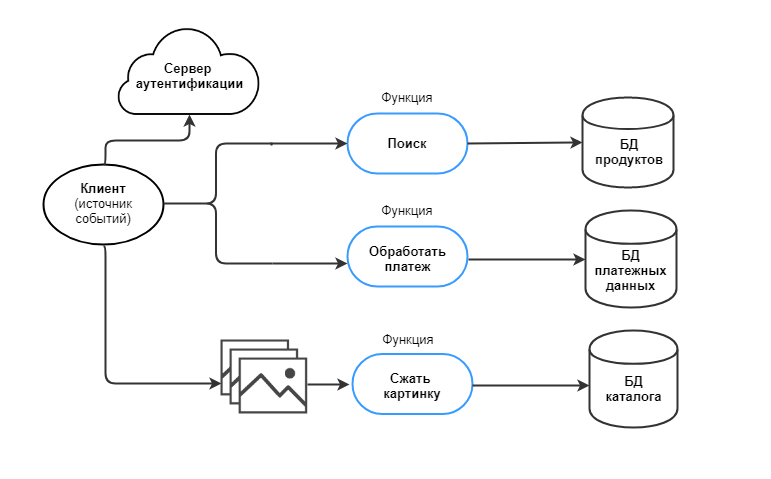
Деление на функции в Serverless похоже на работу с микросервисами. Но микросервис может выполнять несколько задач, а функция в идеале должна выполнять одну. Представим, что стоит задача собирать статистику и выводить по запросу пользователя. В микросервисном подходе задачу выполняет один сервис с двумя точками входа: на запись и на чтение. В бессерверных вычислениях это будут две разные функции, несвязанные между собой. Разработчик экономит вычислительные ресурсы, если, например, статистика обновляется чаще, чем выгружается.
Serverless-функции должны выполняться за короткий промежуток времени (timeout), который определяет провайдер услуги. Например, для AWS timeout составляет 15 минут. Значит, долгоживущие функции (long-lived) придется изменить под требования ― этим Serverless отличается от других популярных сегодня технологий (контейнеров и Platform as a Service).
Каждой функции назначаем событие. Событие ― это триггер для действия:

Событиями могут выступать HTTP-запросы, потоковые данные, очереди сообщений и так далее. Источники событий ― это изменение или появление данных. Кроме того, функции можно запускать по таймеру.
Архитектуру проработали, и приложение почти стало Serverless. Дальше идем к провайдеру услуги.
Со стороны провайдера
Обычно бессерверные вычисления предлагают провайдеры облачных услуг. Называют по-разному: Azure Functions, AWS Lambda, Google Cloud Functions, IBM Cloud Functions.
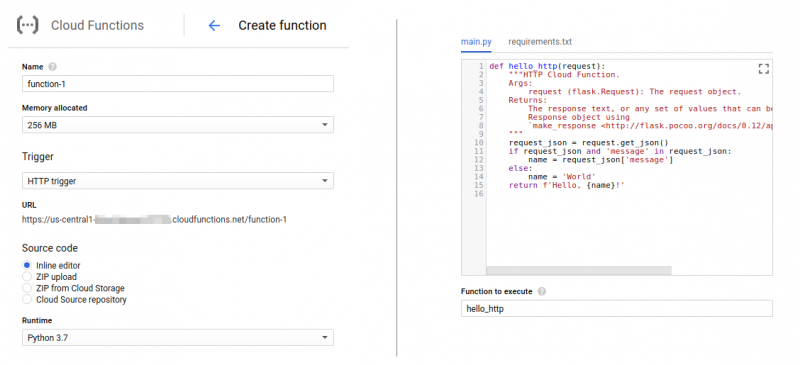
Пользоваться услугой будем через консоль или личный кабинет провайдера. Код функций можно загрузить одним из способов:
- написать код во встроенных редакторах через веб-консоль,
- загрузить архив с кодом,
- работать с публичными или приватными git-репозиториями.
Провайдер на своей инфраструктуре построил и автоматизировал систему Function as a Service (FaaS):
- Код функций попадает в хранилище на стороне провайдера.
- Когда появляется событие, на сервере автоматически разворачиваются контейнеры с подготовленным окружением. Каждому экземпляру функции ― свой изолированный контейнер.
- Из хранилища функция отправляется в контейнер, вычисляется, отдает результат.
- Число параллельных событий растет ― растет количество контейнеров. Система автоматически масштабируется. Если пользователи не обращаются к функции, она будет неактивна.
- Провайдер задает время простоя контейнеров ― если в течение этого времени функции не появляются в контейнере, он уничтожается.
Чтобы познакомить разработчиков с услугой, провайдеры предлагают до 12 месяцев бесплатного тестирования, но ограничивают общее время вычислений, количество запросов в месяц, денежные средства или потребляемые мощности.
Основное преимущество работы с провайдером ― возможность не беспокоиться об инфраструктуре (серверах, виртуальных машинах, контейнерах). Со своей стороны провайдер может реализовать FaaS как на собственных разработках, так и с помощью open-source инструментов. О них и поговорим дальше.
Со стороны open source
Последние пару лет сообщество open-source активно работает над инструментами Serverless. В том числе вклад в развитие бессерверных платформ вносят крупнейшие игроки рынка:
- Google предлагает разработчикам свой open-source инструмент ― Knative. В его разработке участвовали IBM, RedHat, Pivotal и SAP;
- IBM работали над Serverless-платформой OpenWhisk, которая затем стала проектом Apache Foundation;
- Microsoft частично открыли код платформы Azure Functions.
Фреймворки оставляют простор для конфигурации инструмента под свои нужды. Так, в Kubeless разработчик может настроить timeout выполнения функции (дефолтное значение ― 180 секунд). Fission в попытке решить проблему холодного старта предлагает часть контейнеров держать все время запущенными (хоть это и влечет затраты на простой ресурсов). А OpenFaaS предлагает набор триггеров на любой вкус и цвет: HTTP, Kafka, Redis, MQTT, Cron, AWS SQS, NATs и другие.
Инструкции к началу работы можно найти в официальной документации фреймворков. Работа с ними подразумевает наличие чуть большего количества навыков, чем при работе с провайдером ― это как минимум умение запустить Kubernetes-кластер через CLI. Максимум, включить в работу другие open-source инструменты (допустим, менеджер очередей Kafka).
Вне зависимости от того, каким способом мы будем работать с Serverless ― через провайдера или с помощью open-source, мы получим ряд преимуществ и недостатков Serverless-подхода.
Последние пару лет сообщество open-source активно работает над инструментами Serverless. В том числе вклад в развитие бессерверных платформ вносят крупнейшие игроки рынка:
Google предлагает разработчикам свой open-source инструмент ― Knative. В его разработке участвовали IBM, RedHat, Pivotal и SAP;
IBM работали над Serverless-платформой OpenWhisk, которая затем стала проектом Apache Foundation;
Microsoft частично открыли код платформы Azure Functions.
Разработки ведутся и в направлении serverless-фреймворков. Kubeless и Fission разворачиваются внутри заранее подготовленных Kubernetes-кластеров, OpenFaaS работает как с Kubernetes, так и с Docker Swarm. Фреймворк выступает в роли своеобразного контроллера ― по запросу готовит внутри кластера среду выполнения, потом запускает там функцию.
Фреймворки оставляют простор для конфигурации инструмента под свои нужды. Так, в Kubeless разработчик может настроить timeout выполнения функции (дефолтное значение ― 180 секунд). Fission в попытке решить проблему холодного старта предлагает часть контейнеров держать все время запущенными (хоть это и влечет затраты на простой ресурсов). А OpenFaaS предлагает набор триггеров на любой вкус и цвет: HTTP, Kafka, Redis, MQTT, Cron, AWS SQS, NATs и другие.
Инструкции к началу работы можно найти в официальной документации фреймворков. Работа с ними подразумевает наличие чуть большего количества навыков, чем при работе с провайдером ― это как минимум умение запустить Kubernetes-кластер через CLI. Максимум, включить в работу другие open-source инструменты (допустим, менеджер очередей Kafka).
Вне зависимости от того, каким способом мы будем работать с Serverless ― через провайдера или с помощью open-source, мы получим ряд преимуществ и недостатков Serverless-подхода.
С позиции преимуществ и недостатков
Serverless развивает идеи контейнерной инфраструктуры и микросервисного подхода, при которых команды могут работать в мультиязычном режиме, не привязываясь к одной платформе. Построение системы упрощается, а исправлять ошибки становится легче. Микросервисная архитектура позволяет добавлять в систему новый функционал значительно быстрее, чем в случае с монолитным приложением.
- Serverless сокращает время разработки еще больше, позволяя разработчику сосредоточиться исключительно на бизнес-логике приложения и написании кода. Как следствие, время выхода разработок на рынок сокращается.
- Бонусом мы получаем автоматическое масштабирование под нагрузку, а платим только за используемые ресурсы и только в то время, когда они используются.
Как и любая технология, Serverless имеет недостатки.
- Например, таким недостатком может быть время холодного старта (в среднем до 1 секунды для таких языков как JavaScript, Python, Go, Java, Ruby).
Холодный старт может превратиться в теплый, когда функция переиспользует запущенный предыдущим ивентом контейнер. Такая ситуация возникнет в трех случаях:
- если клиенты часто используют сервис и растет количество обращений к функции;
- если провайдер, платформа или фреймворк позволяют держать часть контейнеров запущенными все время;
- если разработчик запускает функции по таймеру (скажем, каждые 3 минуты).
- Следующим недостатком Serverless называют короткое время жизни функции (timeout, за который функция должна выполниться).
- Не все системы смогут работать по Serverless-схеме.
В этом ключе мне бы хотелось плавно перейти к вопросу применения Serverless-подхода.
Со стороны применения
За 2018 год процент использования Serverless вырос в полтора раза. Среди компаний, которые уже внедрили технологию в свои сервисы, такие гиганты рынка как Twitter, PayPal, Netflix, T-Mobile, Coca-Cola. При этом нужно понимать, что Serverless ― не панацея, а инструмент для решения определенного круга задач:
- Сократить простой ресурсов. Не надо постоянно держать виртуальную машину под сервисы, к которым мало обращений.
- «На лету» обработать данные. Сжимать картинки, вырезать фон, менять кодировку видео, работать с датчиками IoT, выполнять математические операции.
- «Склеить» между собой другие сервисы. Git-репозиторий с внутренними программами, чат-бот в Slack с Jira и с календарем.
- Балансировать нагрузку. Здесь остановимся подробнее.
Можно включить в систему балансировщик, который будет распределять нагрузку, скажем, на три виртуальные машины. На данном этапе мы не можем точно спрогнозировать нагрузку, поэтому какое-то количество ресурсов держим запущенными «про запас». И переплачиваем за простой.
В такой ситуации мы можем оптимизировать систему через гибридный подход: за балансировщиком нагрузки оставляем одну виртуальную машину и ставим ссылку на Serverless Endpoint с функциями. Если нагрузка превышает порог ― балансировщик запускает экземпляры функций, которые берут на себя часть обработки запросов.
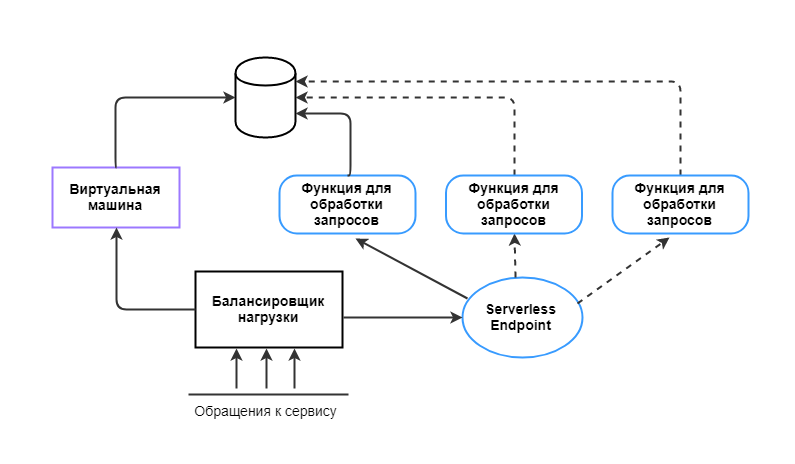
Таким образом, Serverless можно использовать там, где приходится не слишком часто, но интенсивно обрабатывать большое количество запросов. В этом случае запускать несколько функций на 15 минут выгоднее, чем все время держать виртуальную машину или сервер.
При всех преимуществах бессерверных вычислений, перед внедрением в первую очередь стоит оценить логику приложения и понять, какие задачи сможет решить Serverless в конкретном случае.
Serverless и Selectel
В Selectel мы уже упростили работу с Kubernetes через нашу панель управления. Теперь мы строим собственную FaaS-платформу. Мы хотим, чтобы разработчики могли решать свои задачи с помощью Serverless через удобный, гибкий интерфейс.
Если у вас есть идеи, какой должна быть идеальная FaaS-платформа и как вы хотите использовать Serverless в своих проектах, поделитесь ими в комментариях. Мы учтем ваши пожелания при разработке платформы.
0 комментариев
Вставка изображения
Оставить комментарий