Introducing Cloud HSM beta for hardware crypto key security
Защита данных — это главное соображение при запуске корпоративных рабочих нагрузок в облаке. В Google Cloud Platform (GCP) мы предлагаем множество вариантов шифрования ваших данных, включая наше шифрование по умолчанию для данных (мы гордимся тем, что являемся единственным облачным провайдером, который шифрует все данные клиента в состоянии покоя), а также наше облако Служба управления ключами (KMS), которая позволяет явно шифровать блоки данных с помощью ключа под вашим контролем. Но мы слышали от многих из вас, что вы хотели бы еще больше вариантов, которые помогут вам защитить ваши наиболее чувствительные информационные ресурсы и выполнить требования соответствия.
Вот почему мы рады объявить о доступности бета-версии Cloud HSM, управляемой облачной службы безопасности (HSM). Cloud HSM позволяет вам размещать ключи шифрования и выполнять криптографические операции в сертифицированных FIPS 140-2 HSM (см. Ниже). Благодаря этому полностью управляемому сервису вы можете защитить свои наиболее чувствительные рабочие нагрузки, не беспокоясь об операционных издержках управления кластером HSM.

Cloud HSM предоставляет бесплатную аппаратную криптографию и управление ключами для развертывания GCP
Из-за эксплуатационных издержек мы подразумеваем такие задачи, как управление кластерами, масштабирование и обновление. Вы контролируете использование службы Cloud HSM с помощью обычных API облачных KMS, а служба Cloud HSM автоматически позаботится об исправлении, масштабировании и кластеризации без простоя. Вы можете увидеть интерфейс здесь:
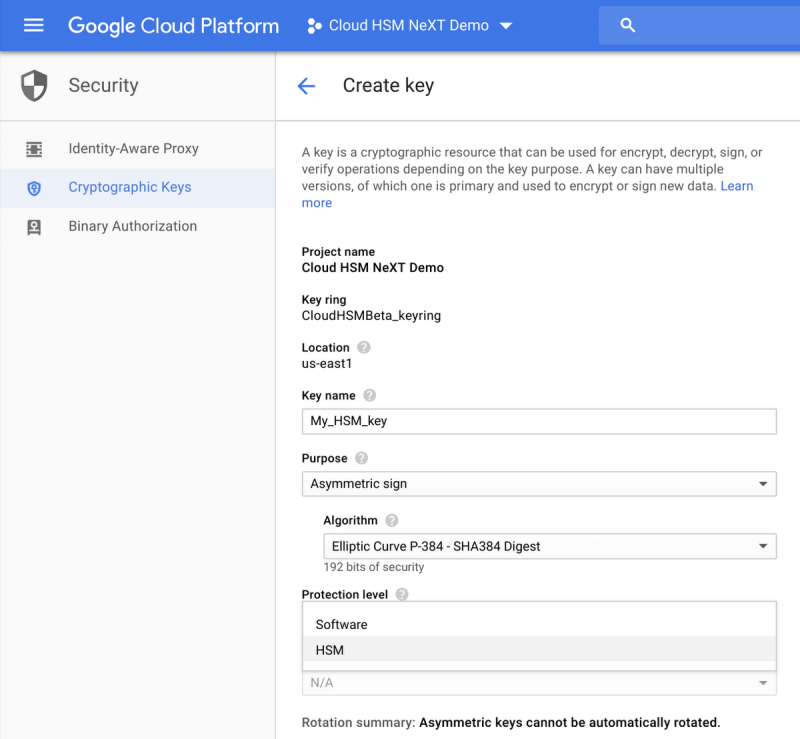
И поскольку служба Cloud HSM тесно интегрирована с Cloud KMS, теперь вы можете защитить свои данные в службах с поддержкой шифрования с поддержкой клиентов, таких как BigQuery, Google Compute Engine, Google Cloud Storage и DataProc, с защищенным аппаратным ключом.
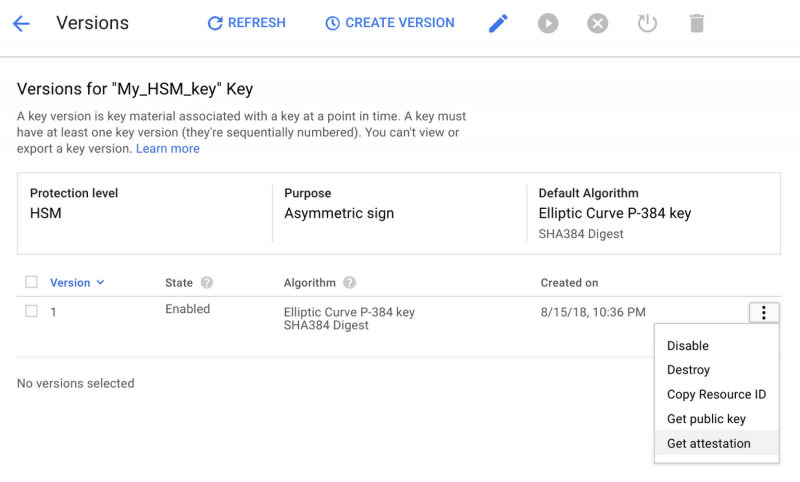
Для тех из вас, кто соблюдает требования соответствия, Cloud HSM может помочь вам выполнить регулирующие мандаты, требующие выполнения ключей и криптографических операций в рамках аппаратной среды. В дополнение к использованию сертифицированных FIPS 140-2 устройств Cloud HSM позволит вам достоверно подтвердить, что ваши криптографические ключи были созданы на границе аппаратного обеспечения, как показано ниже:
С помощью Cloud HSM можно легко начать работу с консоли Google Cloud Platform. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Внедрение асимметричной поддержки ключей
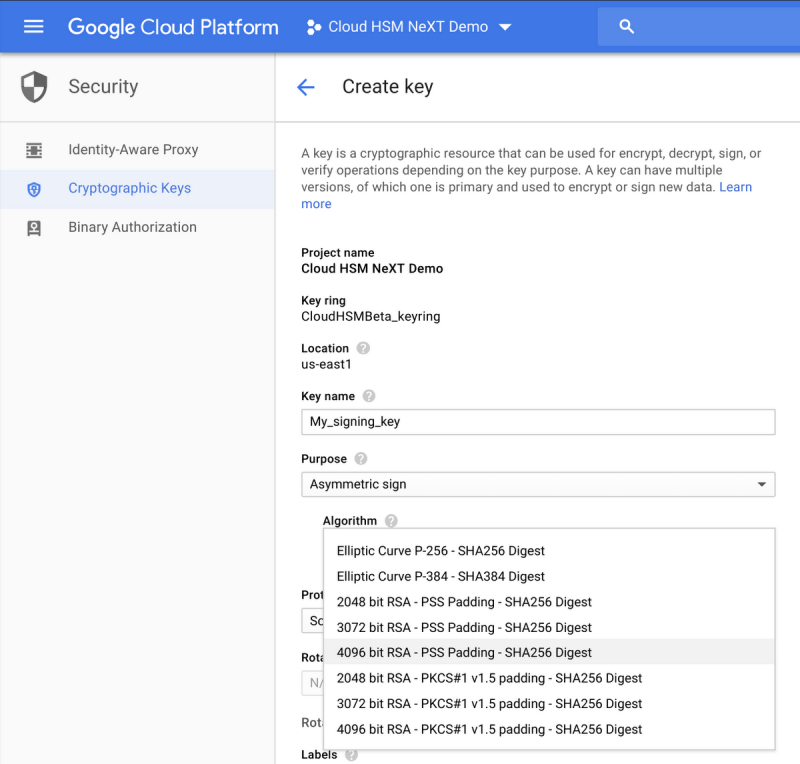
В дополнение к Cloud HSM мы рады объявить о выпуске бета-версии поддержки асимметричного ключа для Cloud KMS и Cloud HSM. В дополнение к симметричному шифрованию ключей с использованием ключей AES-256 теперь вы можете создавать различные типы асимметричных ключей для операций дешифрования или подписания, а это означает, что теперь вы можете хранить свои ключи, используемые для PKI или подписи кода в управляемом хранилище ключей Google Cloud. В частности, для операций подписи будут доступны ключи RSA 2048, RSA 3072, RSA 4096, EC P256 и EC P384, в то время как ключи RSA 2048, RSA 3072 и RSA 4096 также смогут расшифровывать блоки данных. Ознакомьтесь с документацией для получения дополнительной информации и ознакомьтесь с интерфейсом здесь:
Дальнейшая интеграция Hashicorp Vault с Cloud KMS
Наконец, мы рады поделиться замечательными новостями о поддержке Hashicorp Vault Cloud KMS. Теперь вы можете использовать Google Cloud KMS или Cloud HSM для шифрования токенов HashiCorp Vault в покое с помощью GK Cloud KMS Vault Token Helper. Помощник маркера хранилища по умолчанию хранит токены в виде открытого текста на диске. С помощью этой новой функции помощник токена GCP шифрует эти маркеры с помощью клавиш Cloud KMS или Cloud HSM и сохраняет зашифрованные значения на диске. Помощник токена Vault автоматически выполняет все необходимые вызовы API для шифрования / дешифрования данных, поэтому пользовательский интерфейс не изменяется.
Сегодня вы можете начать с Cloud HSM. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Вот почему мы рады объявить о доступности бета-версии Cloud HSM, управляемой облачной службы безопасности (HSM). Cloud HSM позволяет вам размещать ключи шифрования и выполнять криптографические операции в сертифицированных FIPS 140-2 HSM (см. Ниже). Благодаря этому полностью управляемому сервису вы можете защитить свои наиболее чувствительные рабочие нагрузки, не беспокоясь об операционных издержках управления кластером HSM.
Cloud HSM предоставляет бесплатную аппаратную криптографию и управление ключами для развертывания GCP
Из-за эксплуатационных издержек мы подразумеваем такие задачи, как управление кластерами, масштабирование и обновление. Вы контролируете использование службы Cloud HSM с помощью обычных API облачных KMS, а служба Cloud HSM автоматически позаботится об исправлении, масштабировании и кластеризации без простоя. Вы можете увидеть интерфейс здесь:
И поскольку служба Cloud HSM тесно интегрирована с Cloud KMS, теперь вы можете защитить свои данные в службах с поддержкой шифрования с поддержкой клиентов, таких как BigQuery, Google Compute Engine, Google Cloud Storage и DataProc, с защищенным аппаратным ключом.
Для тех из вас, кто соблюдает требования соответствия, Cloud HSM может помочь вам выполнить регулирующие мандаты, требующие выполнения ключей и криптографических операций в рамках аппаратной среды. В дополнение к использованию сертифицированных FIPS 140-2 устройств Cloud HSM позволит вам достоверно подтвердить, что ваши криптографические ключи были созданы на границе аппаратного обеспечения, как показано ниже:
С помощью Cloud HSM можно легко начать работу с консоли Google Cloud Platform. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.
Внедрение асимметричной поддержки ключей
В дополнение к Cloud HSM мы рады объявить о выпуске бета-версии поддержки асимметричного ключа для Cloud KMS и Cloud HSM. В дополнение к симметричному шифрованию ключей с использованием ключей AES-256 теперь вы можете создавать различные типы асимметричных ключей для операций дешифрования или подписания, а это означает, что теперь вы можете хранить свои ключи, используемые для PKI или подписи кода в управляемом хранилище ключей Google Cloud. В частности, для операций подписи будут доступны ключи RSA 2048, RSA 3072, RSA 4096, EC P256 и EC P384, в то время как ключи RSA 2048, RSA 3072 и RSA 4096 также смогут расшифровывать блоки данных. Ознакомьтесь с документацией для получения дополнительной информации и ознакомьтесь с интерфейсом здесь:
Дальнейшая интеграция Hashicorp Vault с Cloud KMS
Наконец, мы рады поделиться замечательными новостями о поддержке Hashicorp Vault Cloud KMS. Теперь вы можете использовать Google Cloud KMS или Cloud HSM для шифрования токенов HashiCorp Vault в покое с помощью GK Cloud KMS Vault Token Helper. Помощник маркера хранилища по умолчанию хранит токены в виде открытого текста на диске. С помощью этой новой функции помощник токена GCP шифрует эти маркеры с помощью клавиш Cloud KMS или Cloud HSM и сохраняет зашифрованные значения на диске. Помощник токена Vault автоматически выполняет все необходимые вызовы API для шифрования / дешифрования данных, поэтому пользовательский интерфейс не изменяется.
Сегодня вы можете начать с Cloud HSM. Чтобы узнать больше, посетите домашнюю страницу Cloud HSM или ознакомьтесь с документацией.