Если бы ваше лето было фильмом, то каким? Мы решили, что на эту роль вполне подошла бы фантастика «Всё, везде и сразу». И не только из-за того, что часто хочется оказаться в нескольких местах одновременно — хотя явно не помешало бы. А потому, что происходит столько событий, что просто не успеваешь уследить за всеми.
 Статьи и инструкции
Статьи и инструкции
Протокол POP3 и IMAP — в чем разница и какой лучше выбрать
Если настраиваете почтовый клиент и думаете, какой протокол выбрать, знание разницы между POP3 и IMAP поможет сэкономить кучу времени и нервов. В статье разобрали два популярных протокола работы с почтой и объяснили, когда и какой лучше использовать.
firstvds.ru/blog/protokoly-pop3-imap-v-chem-raznica
Модель TCP/IP: что это и как работает
Миллионы людей пользуются интернетом, но лишь немногие понимают, как он работает. А всё благодаря модели TCP/IP. В статье разберём, как устроена эта система и расскажем, почему интернет работает даже при сбоях.
firstvds.ru/technology/model-tcp-ip-chto-eto-i-kak-rabotaet
Хакнуть мир: фильмы и сериалы об айтишниках
Подготовили подборку фильмов и сериалов о тех, кто меняет правила игры: бунтарях, цифровых революционерах и гениях, бросивших вызов системе. Мощное кино для ценителей концептуального послевкусия.
firstvds.ru/blog/khaknut-mir-filmy-i-serialy-o-programmistakh-brosivshikh-vyzov-sisteme
Habr: самое интересное за июль
Зачем разрываться между «важно» и «интересно», когда можно не выбирать, а получить сразу и всё. В подборке Хабра и перспективы подводных энергохранилищ, и квантовые основы ИИ, и даже практические тонкости Go-разработки.
Ищем авторов для блога на Хабр
Подготовьте статью на одну из специальных тем или отправьте материал на тему месяца. И если ваша статья подойдёт для блога, вы получите повышенный гонорар. Тема августа: Карьера в IT-индустрии.
firstvds.ru/blog/vremya-pisat-stati-ischem-avtorov-dlya-blogov-i-bz
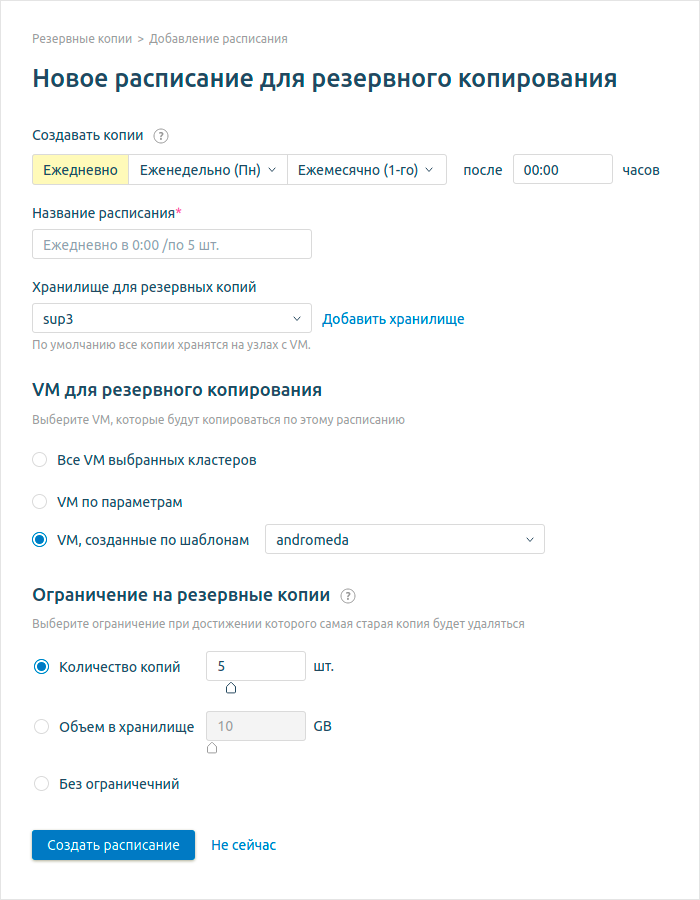
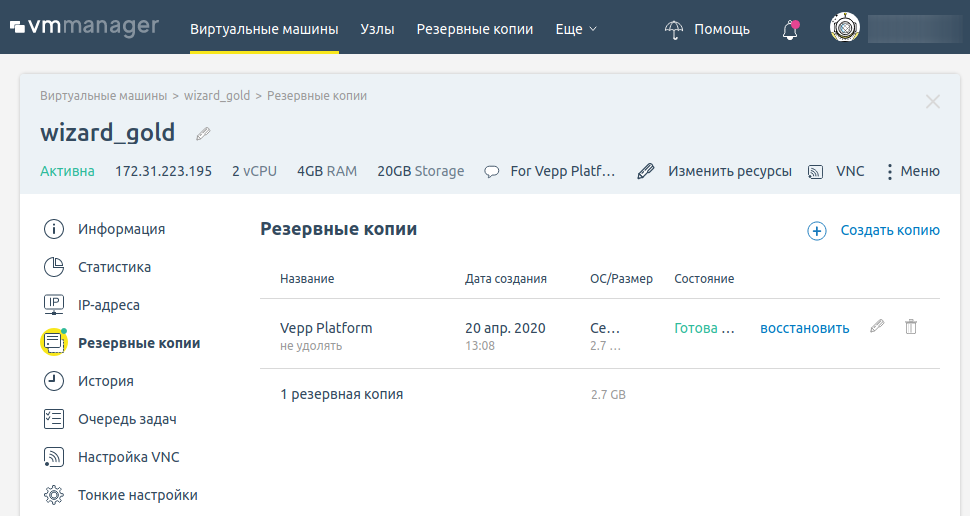
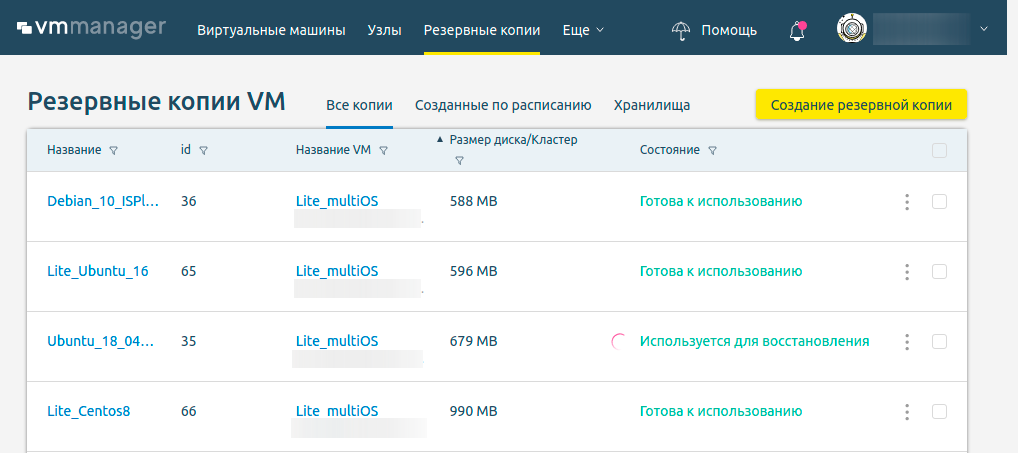
Новости июля
Новые возможности в S3-manager

Наша команда постоянно работает над улучшением услуги. Вот что было сделано в июле:
- Обновлен функционал копирования/перемещения объектов. Перемещать и копировать объекты внутри бакета стало удобнее и интуитивно понятно.
- Усовершенствована работа со списком объектов. Теперь вы можете выбрать несколько видов сортировки.
- Оптимизирована загрузка и скачивание файлов, они стали гораздо быстрее.
- Улучшена отзывчивость интерфейса. Работать с S3 Manager, теперь приятнее, так как он значительно прибавил в скорости работы.
- S3 Manager может отображать содержимое бакетов независимо от количества объектов в них. Теперь в S3 Manager отображать содержимое бакетов с большим количеством объектов, сохраняя при этом внутреннюю иерархию/структуру бакета.
firstvds.ru/services/s3
День сисадмина 2025

В последнюю пятницу июля, по древней и почтённой традиции, мы празднуем День системного администратора — В честь праздника запустили акцию с 25 июля по 7 августа и дарим подарки.
firstvds.ru/actions/sysadmin_day_25-spirit_of_uptime
Топ новостей из мира безопасности
Пришла пора развенчать миф о беззаботном лете и обратиться к жанру психологического триллера. Пока Голливуд отдыхает в сторонке, рассказываем о самых опасных угрозах этого месяца и, конечно, спасительных обновлениях.
Опасная уязвимость в WordPress-теме Motors позволяет взламывать сайты
В популярной теме Motors для WordPress была обнаружена критическая уязвимость (CVE-2025-4322), которая позволяет злоумышленникам сбрасывать пароли администраторов. Проблема затрагивает версии до 5.6.67 и связана с некорректной проверкой данных в виджете Login Register.
Эксплуатация уязвимости началась еще в мае — злоумышленники отправляют специальные POST-запросы, подменяя параметры сброса пароля. Более масштабные атаки начались после 7 июня. По данным Wordfence, уже зафиксировано свыше 23 тысяч попыток взлома.
Эксперты советуют, не откладывая, обновить тему Motors до актуальной версии — разработчики StylemixThemes выпустили защитное обновление 5.6.68 ещё в мае, однако на многих сайтах до сих пор используются уязвимые версии темы. Также рекомендуется проверить список пользователей на подозрительные административные аккаунты и убедиться, что все пароли администраторов изменены.
xakep.ru/2025/06/24/motors-under-attacks/
WinRAR закрыл опасную уязвимость
Компания WinRAR выпустила обновление 7.12, устраняющее критическую уязвимость (CVE-2025-6218), которая позволяла злоумышленникам запускать вредоносный код через поддельные архивы. Проблема затрагивала только версии для Windows и могла привести к заражению системы при распаковке файла.
Уязвимость оценивается в 7,8 балла по шкале CVSS и позволяет записывать вредоносные файлы в системные папки, например, в автозагрузку. Компания уже выпустила исправление, однако пользователям необходимо вручную обновить WinRAR, так как автоматических обновлений нет.
3dnews.ru/1124971/winrar-ekstrenno-ustranila-opasniy-bag-pozvolyavshiy-cherez-arhiv-zapuskat-vredonosnoe-po/#685cb2a9742eec09be8b4572
Уязвимость в WordPress-плагине Forminator угрожает тысячам сайтов
В популярном плагине Forminator для WordPress обнаружена опасная уязвимость (CVE-2025-6463, 8.8 баллов по CVSS), позволяющая злоумышленникам удалять системные файлы и захватывать сайты. Проблема затрагивает версии до 1.44.2.
Уязвимость связана с недостаточной проверкой загружаемых файлов. Злоумышленник мог отправить вредоносный запрос, имитирующий загрузку файла, и при удалении записи администратором плагин стирал критически важные файлы, например, wp-config.php, что приводило к сбросу сайта.
Разработчики выпустили исправление в версии 1.44.3, добавив проверку путей файлов. Владельцам сайтов рекомендуется срочно обновить плагин или временно отключить его.
xakep.ru/2025/07/03/forminator-flaw/
Уязвимость в sudo позволяет получить root-доступ
В утилите sudo обнаружена опасная уязвимость (CVE-2025-32463). Она позволяет не имеющему прав пользователю выполнить произвольный код с root-доступом, даже если он не указан в файле sudoers. Проблема затрагивает версии 1.9.14–1.9.17 и, возможно, более ранние.
Причиной уязвимости стало то, что при использовании опции -R ("--chroot") sudo некорректно загружал файл /etc/nsswitch.conf из указанного каталога, а не из системного. Это позволяло злоумышленнику подменить конфигурацию и загрузить вредоносную библиотеку, выполняющую код с максимальными привилегиями.
Проблема устранена в sudo 1.9.17p1. Владельцам серверов на Ubuntu, Fedora, Debian и других дистрибутивах рекомендуется немедленно обновить пакет. В этой версии также исправлена вторая уязвимость (CVE-2025-32462), связанная с обходом ограничений в правилах sudoers через опцию -h ("--host").
www.opennet.ru/opennews/art.shtml?num=63505
Уязвимости в Redis и Valkey: риски RCE и DoS
Выпущены срочные обновления для СУБД Redis (версии 6.2.19 – 8.0.3) и Valkey (8.0.4 – 8.1.3), которые устраняют две опасные уязвимости:
CVE-2025-32023 — уязвимость в реализации алгоритма HyperLogLog. Позволяет удалённо выполнять код (RCE) через переполнение буфера. Атака требует доступа к отправке команд в СУБД.
CVE-2025-48367 — проблема аутентификации, которая происходит из-за неправильной обработки ошибок во время соединений и приводит к отказу в обслуживании (DoS). Как следствие, снижается производительность СУБД.
Рекомендуется как можно скорее обновить Redis/Valkey до актуальных версий и ограничить доступ к командам HLL через ACL (как временное решение). Уязвимости особенно опасны для публично доступных экземпляров СУБД.
www.opennet.ru/opennews/art.shtml?num=63537
Уязвимость в Linux позволяет взломать систему через Initramfs
Исследователи кибербезопасности из ERNW выявили критическую уязвимость в Linux, которая позволяет злоумышленникам с физическим доступом к устройству получить полный контроль над системой, даже если диск полностью зашифрован.
Проблема затрагивает Ubuntu 25.04 и Fedora 42. При нескольких неудачных попытках ввода пароля для расшифровки диска (в Ubuntu — после нажатия Esc и ввода специальной комбинации) система предоставляет отладочную оболочку (debug shell). Через неё злоумышленник может подключить USB-накопитель с инструментами для модификации initramfs — временной файловой системы, используемой при загрузке.
Поскольку initramfs не имеет цифровой подписи, изменения не обнаруживаются механизмами защиты. При следующей загрузке, когда владелец введёт правильный пароль, вредоносный код будет выполняться с повышенными привилегиями. Это может привести к утечке данных, удалённому доступу или внедрению кейлоггера.
Атака требует физического доступа и специальных навыков, поэтому наиболее актуальна для корпоративных систем и критической инфраструктуры. В качестве меры защиты рекомендуется настроить автоматическую перезагрузку после нескольких неудачных попыток ввода пароля.
www.linux.org.ru/news/security/18021212
Обновление Windows Server затрагивает работу Samba
Microsoft 8 июля выпустила обновления для Windows Server, усилившие проверки в протоколе Netlogon, используемом для аутентификации в Active Directory. Эти изменения привели к проблемам совместимости с серверами Samba, особенно при использовании бэкенда 'ad'.
После обновления Windows Server сервис winbind в Samba начинает некорректно обрабатывать запросы обнаружения контроллера домена (Netlogon DC Discovery). В результате пользователи не могут подключиться к SMB-ресурсам на серверах Samba, работающих в режиме члена домена.
Разработчики Samba оперативно выпустили патчи (4.22.3 и 4.21.7), устраняющие проблему. Администраторам рекомендуется как можно скорее обновить Samba, чтобы избежать сбоев в работе доменной инфраструктуры.
www.opennet.ru/opennews/art.shtml?num=63540
Атака TSA: уязвимости в процессорах AMD крадут данные из ядра и виртуальных машин
Исследователи из Microsoft и Швейцарской высшей технической школы Цюриха обнаружили новый класс атак на процессоры AMD — TSA (Transient Scheduler Attack). Уязвимости CVE-2024-36350 (TSA-SQ) и CVE-2024-36357 (TSA-L1) позволяют злоумышленнику обходить изоляцию между процессами, ядром и виртуальными машинами, извлекая конфиденциальные данные.
Атака основана на анализе времени выполнения инструкций после «ложного завершения» операций чтения из памяти. Процессор может спекулятивно выполнять инструкции, опираясь на некорректные данные, что создаёт уязвимости для утечки информации через микроархитектурные структуры (Store Queue и кэш L1D).
Проблема затрагивает процессоры AMD на архитектурах Zen 3 и Zen 4, включая линейки Ryzen 5000/6000/7000/8000, EPYC Milan/Genoa и Threadripper PRO и др.
Исправления уже включены в декабрьские обновления микрокода и PI-прошивок. Для полной защиты также требуется обновление ядра Linux (с возможностью отключения через параметр tsa=off) или гипервизора Xen.
www.opennet.ru/opennews/art.shtml?num=63557
Выпущены патчи для критических уязвимостей в Git
Разработчики Git выпустили экстренные обновления (2.43.7 – 2.50.1), закрывающие несколько опасных уязвимостей, которые позволяют выполнить произвольный код при работе с вредоносными репозиториями.
Основные проблемы:
- CVE-2025-48384 – уязвимость в обработке субмодулей: из-за некорректной очистки символа возврата каретки (CR) атакующий может подменить путь и внедрить вредоносный Git hook, который выполнится после операции checkout.
- CVE-2025-48385 – уязвимость в загрузке bundle-файлов, позволяющая записать данные в произвольное место файловой системы.
- CVE-2025-48386 – переполнение буфера в Wincred (учётные данные Windows).
Кроме того, устранены уязвимости в графических интерфейсах Gitk и Git GUI:
- CVE-2025-27613 – перезапись файлов через специальный репозиторий в Gitk.
- CVE-2025-27614 – выполнение произвольного скрипт при запуске команды 'gitk filename' для специально подготовленного репозитория.
- CVE-2025-46334 – запуск вредоносных .exe-файлов в Git GUI (Windows).
- CVE-2025-46335 – создание или перезапись произвольных файлов при работе с репозиторием в Git GUI.
Рекомендуется немедленно обновить Git, особенно разработчикам, работающим с внешними репозиториями.
www.opennet.ru/opennews/art.shtml?num=63552
Взлом плагина Gravity Forms: зараженные версии содержали бэкдор
Популярный WordPress-плагин Gravity Forms, используемый для создания онлайн-форм, оказался заражен бэкдором после атаки на цепочку поставок. Вредоносный код попал в ручные установщики с официального сайта.
По данным PatchStack, плагин отправлял POST-запросы на подозрительный домен gravityapi[.]org, собирая метаданные сайтов, включая данные о темах, плагинах и версиях WordPress/PHP. Полученный в ответ вредоносный скрипт сохранялся на сервере и позволял выполнять произвольный код без аутентификации.
Разработчик RocketGenius подтвердил, что затронуты только версии 2.9.11.1 и 2.9.12, загруженные 10–11 июля 2025 года. Вредоносный код блокировал обновления, создавал скрытую учётную запись администратора и связывался с сервером злоумышленников.
Рекомендации:
- Переустановите плагин, если загружали его в указанные даты.
- Проверьте сайт на признаки взлома.
Служба Gravity API, отвечающая за автоматические обновления, не была скомпрометирована.
xakep.ru/2025/07/14/gravity-forms-backdoor/
Хакеры научились скрывать вредоносное ПО в DNS-записях
Эксперты DomainTools обнаружили новый метод заражения, при котором вредоносный код маскируется в DNS-записях типа TXT. Этот способ позволяет обходить системы защиты, так как DNS-трафик обычно считается безопасным.
Злоумышленники разбивают вредоносное ПО на фрагменты и распределяют их по поддоменам. При загрузке эти части автоматически собираются в полноценную вредоносную программу. Уже найдены примеры такого кода, включая Joke Screenmate (имитирует сбои системы) и PowerShell Stager (загружает дополнительные угрозы).
Пока реальных атак не зафиксировано, но специалисты предупреждают, что метод крайне опасен из-за своей скрытности. Для защиты рекомендуется:
- мониторить DNS-трафик на аномальные запросы,
- анализировать TXT-записи, выходящие за рамки стандартных функций,
- использовать системы анализа угроз для выявления подозрительных доменов.
Эксперты считают, что массовые атаки с использованием этой техники — лишь вопрос времени.
3dnews.ru/1126189/nayden-sposob-zaragat-dnszapisi-vredonosnim-po/#687a4715742eecbde78b4568
Крупнейшая кибератака 2025 года: хакеры взломали 400 организаций через уязвимость в SharePoint
Все началось с предупреждения Microsoft о критической уязвимости в SharePoint, которую хакеры начали активно эксплуатировать. Если неделю назад речь шла о 100 скомпрометированных организациях, то теперь их число превысило 400. Среди пострадавших — правительственные учреждения США, включая Национальное управление ядерной безопасности, а также организации в Европе, Азии и Африке.
Нидерландская компания Eye Security, первой обнаружившая атаки, отмечает, что злоумышленники действуют методично: сначала проводят разведку, затем массово атакуют уязвимые системы. Особую тревогу вызывает возможная причастность китайских хакерских группировок, хотя официальный Пекин эти обвинения отвергает.
Microsoft оперативно выпустила патч, но многие серверы уже были скомпрометированы до его выхода. Эксперты предупреждают: реальный масштаб ущерба может быть значительно больше, так как хакеры используют методы, не оставляющие явных следов.
При этом хакеры могли получить доступ к данным о ядерных технологиях, хотя наиболее секретные системы США изолированы. Атаки продолжаются — другие группировки начали использовать ту же уязвимость. Национальная казначейская служба ЮАР уже подтвердила наличие вредоносного ПО в своих сетях, другие организации продолжают проверки.
ФБР и британские киберслужбы расследуют инцидент. По данным Shodan, под угрозой находятся более 8000 серверов, подключенных к интернету. Эта атака может войти в историю как одна из самых масштабных в 2025 году, подчеркивая необходимость срочного обновления SharePoint и усиленного мониторинга сетей.
3dnews.ru/1126465/ataka-na-serveri-microsoft-sharepoint-moget-stat-krupneyshey-kiberatakoy-2025-goda-chislo-postradavshih-previsilo-chetire-sotni/#6881cd16742eecb45c8b4569
Решила, что её лето похоже на мульт «Трое из Простоквашино» и оставила дописывать дайджест коллеге — Алёна М.