Последняя пятница июля — День системного администратора. Компания REG.RU поздравляет специалистов и рассказывает о тематических IT-доменах, а также зонах для хобби, которые заинтересуют, представителей этой профессии.
Системный администратор — одна из важнейших IT-профессий, которая за последние 25 лет стала неотъемлемой частью интернет-фольклора. Но, вопреки всем стереотипам, сисадмин — это необязательно интроверт, который всё свободное время проводит за компьютером. Сегодня системные администраторы — это активные люди, со своими проектами, профессиональными интересами, бизнесом, хобби.
В качестве домена для специализированного проекта лучшим выбором станут адреса в зонах .TECH, .CLOUD, .COMPUTER, .DIGITAL, .ENGINEER, .DEV. Они подойдут для личного блога, форума, pet-проекта и многого другого. Например, на сайте с адресом RHCE.ENGINEER системный администратор сможет разместить своё резюме и показать потенциальному работодателю, что он сертифицированный специалист для работы с Red Hat Linux. Кроме New gTLDs сисадмины также могут обратить внимание на различные национальные домены, которые популярны не только в «родных» странах, но и у пользователей со всего мира, благодаря альтернативным значениям. Среди них .IT (национальный домен Италии — “information technology”), .PW (национальный домена Палау — “personal web”), .IO (национальный домен Британской Территории в Индийком океане — “input-output”). Также не стоит забывать о домене .ORG, который станет идеальным решением для opensource-проекта.
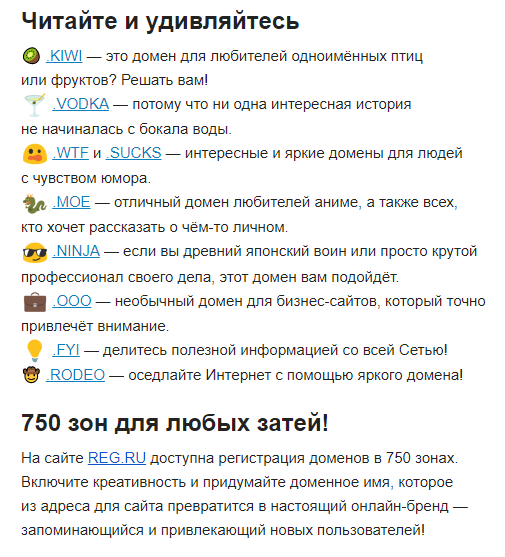
Работа работой, но системным администраторам также нужно отдыхать! Для хобби-проектов, не связанных напрямую с IT, подойдут домены .GAMES, .MOE, .BAND или .ART и ещё сотни доменов, в зависимости от интересов — игры, аниме и японская культура, музыка, арт-проекты или что-либо другое. Чтобы зарегистрировать домен в одной из перечисленных зон, пользователю достаточно выбрать домен на сайте REG.RU и оплатить первый год регистрации. Подробности можно получить по адресу:
www.reg.ru/domain/new
Благодаря сисадминам поддерживается работа IT-инфраструктуры множества частных проектов, коммерческих и проектов государственных организаций. Без системных администраторов невозможно представить современный Интернет! Невероятно интересно видеть, как трансформируется эта профессия вместе с технологическим развитием отрасли
комментирует генеральный директор REG.RU Алексей Королюк.
REG.RU — хостинг-провайдер и аккредитованный регистратор доменных имён №1 в России (по данным StatOnline.ru, занимает первое место по количеству зарегистрированных доменов и размещённых сайтов в национальных зонах .RU и.РФ). Компания обслуживает более 3 000 000 доменов и предлагает регистрацию в 750 международных доменных зонах, а также предоставляет услуги хостинга, SSL, почты, VPS, аренды физических серверов и облачных вычислений на GPU. Занимает первое место в рейтинге хостинг-провайдеров России. В 2012 году REG.RU стал аккредитованным ICANN регистратором. Офисы REG.RU в 30 городах России и СНГ.