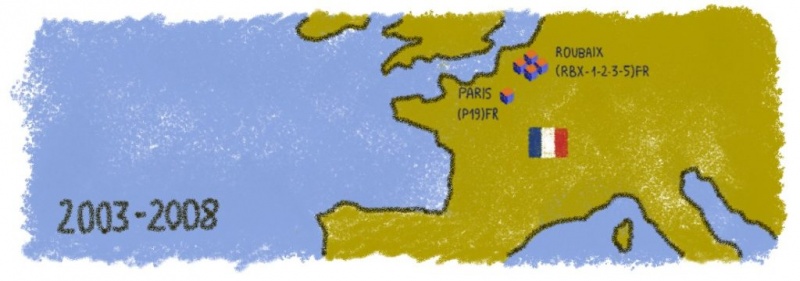
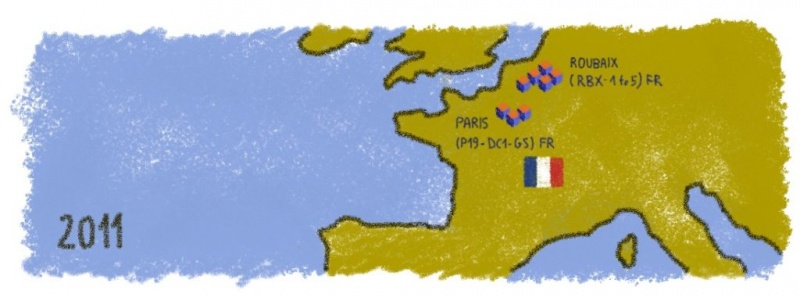
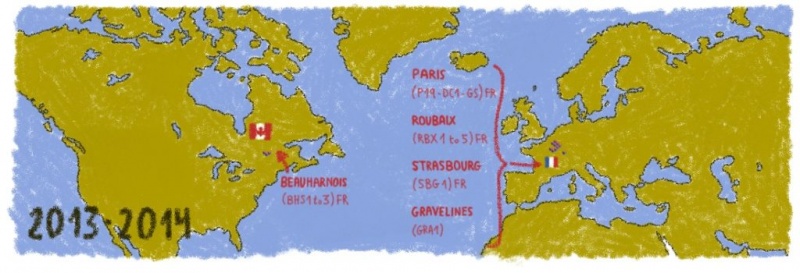
В наших предыдущих статьях мы объясняли, почему нам пришлось переместить 800 000 баз данных из одного центра обработки данных в 300 километров. Итак, мы… Моя команда и я сделали это! Это была настоящая горелка мозгов, так что я надеюсь, что наша история поможет вам рассмотреть больше огромных технических проектов, с которыми мы любим играть.
Правила
- Чтобы уменьшить задержку, база данных должна быть перенесена одновременно с использованием веб-сайта.
- Поскольку базы данных распределены по всем доступным серверам MySQL, гранулярность миграции должна быть базой данных, а не экземпляром MySQL. Другими словами, мы не можем перенести весь сервер MySQL. Мы должны переместить только часть этого.
- Поскольку на ссылку между веб-сайтом и его базой данных нет необходимости ссылаться, веб-сайт в Gravelines должен иметь возможность связаться с базой данных в Париже (например), и наоборот.
- Чтобы связаться со своей базой данных, веб-сайт использует имя хоста, имя пользователя и пароль. Мы хотим, чтобы миграция была прозрачной, поэтому никому не нужно менять какие-либо из этих элементов для связи с их новой базой данных.
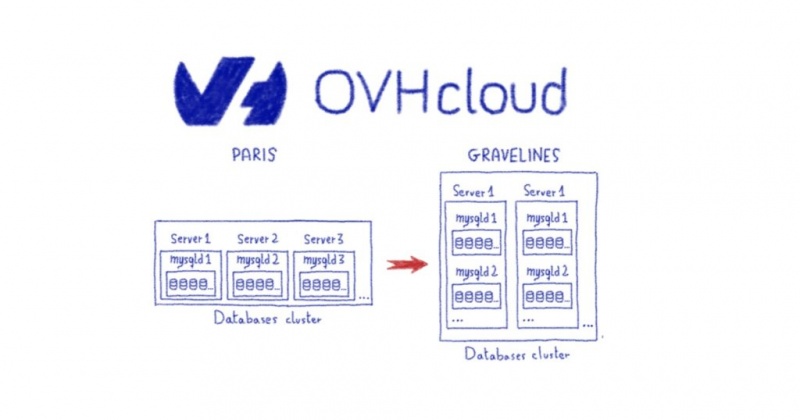
- Платформы баз данных меняются между Парижем и Гравелином, как показано ниже.
Подводя итог, вот что мы имеем до миграции веб-кластера:
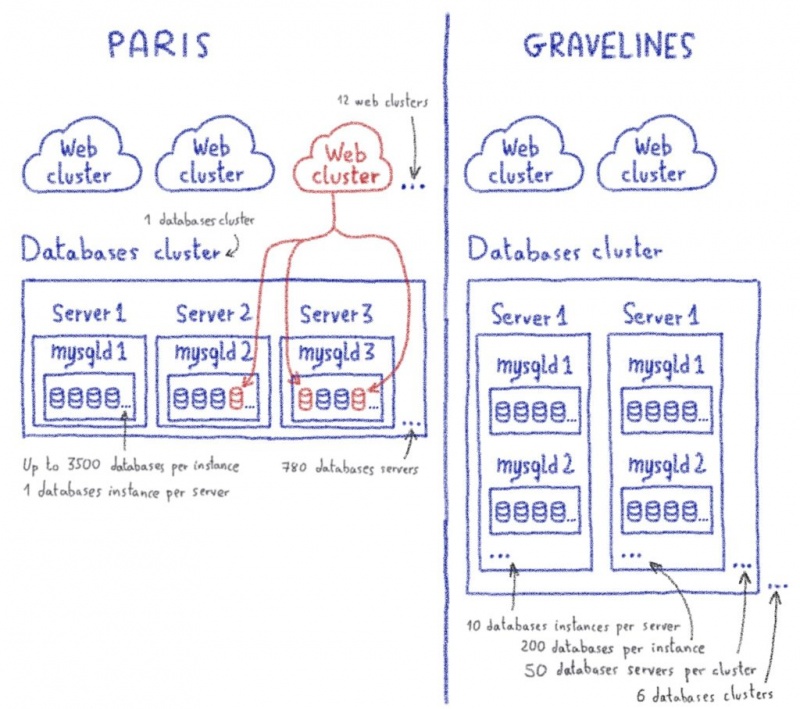
И это то, что мы хотим после миграции:
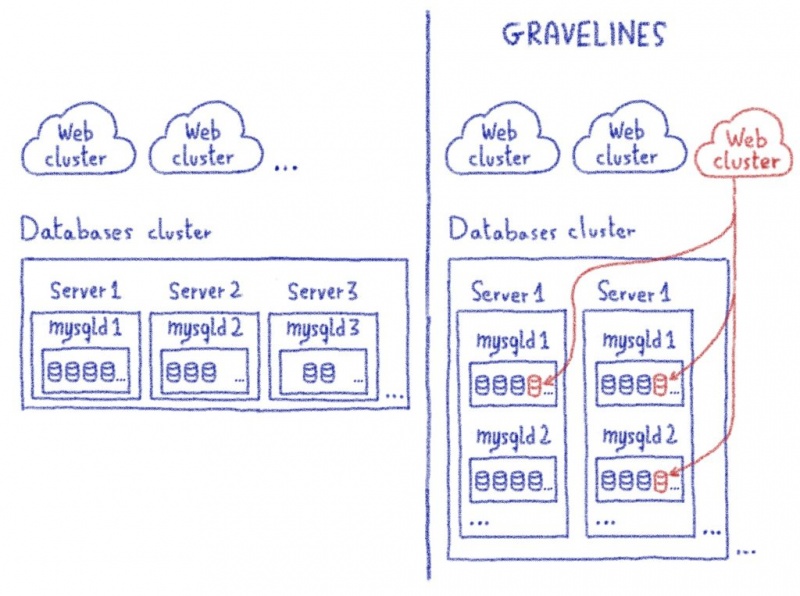
Еще несколько вещей…
- Очевидно, что мы имели в виду одну из самых важных вещей при работе с базами данных: согласованность. Для каждой базы данных мы должны были определить точку согласованности. До этого момента на временной шкале чтение / запись производились в Париже. После этого чтение / запись были сделаны в Gravelines.
- Мы верим в прозрачность и обратимость. Это обе ключевые части нашего облака SMART. Вот почему мы хотели предоставить вам доступ к этой точке согласованности в виде дампа на вашей панели управления OVHcloud. Для каждой перенесенной базы данных мы решили предоставить вам доступ к дампу на один месяц.
- Миграция 800K баз данных примерно за 60 ночей означала, что мы должны быть очень быстрыми и масштабируемыми. Наш рекорд был 1 июля 2019 года, когда мы успешно мигрировали 13502 базы данных за 1 час 13 минут и 31 секунду.
- Если вы привыкли быть на дежурстве, вы знаете, что ваше внимание и эффективность снижаются ночью. Повторение процесса миграции примерно 60 раз в год усилит это, поэтому мы хотели, чтобы все было максимально автоматизировано и максимально просто. Как мы увидим позже, чтобы запустить миграцию базы данных, нам просто нужно было выполнить одну команду на одном хосте:
migrate-p19
Теперь вы знаете правила, пора начинать игру!
1-й уровень
Первый уровень всегда легкий, где вы узнаете, как игра работает, с помощью своего рода учебника! Итак, начнем с небольшой миграции базы данных. Вот как мы это делаем:
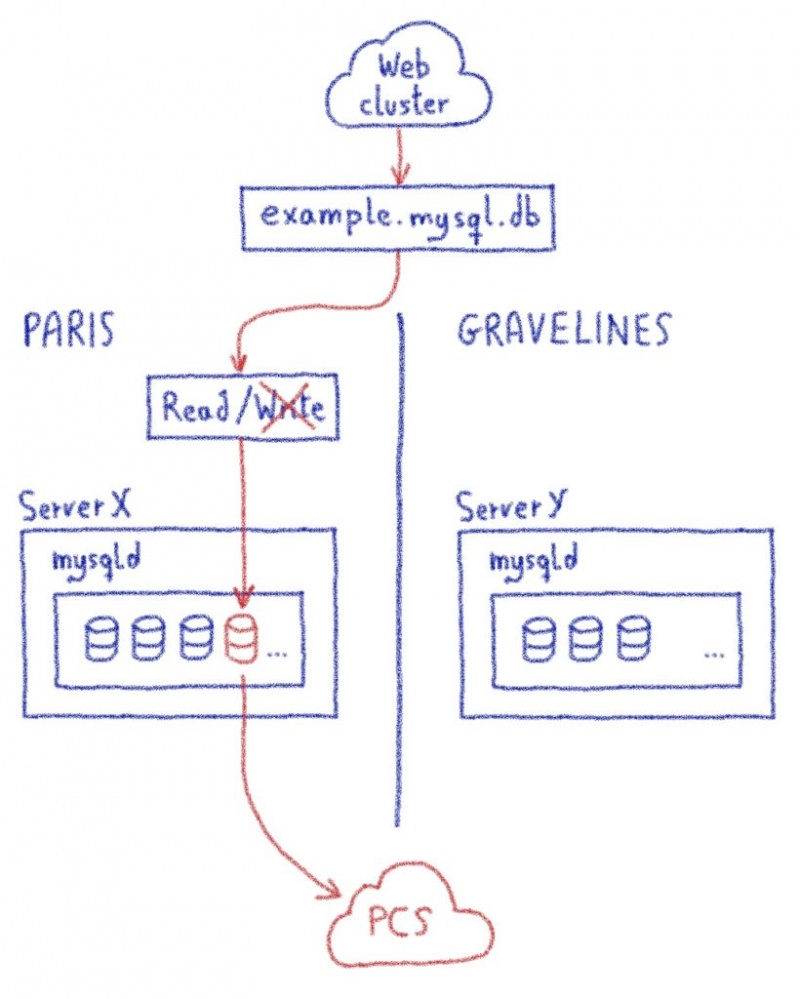
1. У источника (Париж)
- Установите режим только для чтения. Нам абсолютно необходимо избегать записи во время миграции, чтобы избежать знаменитого раскола мозга. Самый простой способ сделать это — перевести базу данных в режим только для чтения. В большинстве случаев веб-сайтам нужно только читать базы данных, но в некоторых случаях им нужно чтение и запись, и поэтому они будут повреждены. Это не проблема, потому что сайт в настоящее время перенесен и закрыт. Мы заблокируем доступ на запись в случае, если база данных используется другим хостом, на который не влияет ночная миграция.
- Дамп базы данных и положить куда-нибудь дамп. Мы решили хранить дампы в общедоступном облачном хранилище (PCS) OVHcloud, поскольку мы уже используем это решение для хранения 36 миллионов дампов в месяц. Добавление 800 000 дампов в год — не проблема для этой потрясающей платформы!
- 3 минуты и 31 секунда.
Если вы привыкли быть на дежурстве, вы знаете, что ваше внимание и эффективность снижаются ночью. Повторение процесса миграции примерно 60 раз в год усилит это, поэтому мы хотели, чтобы все было максимально автоматизировано и максимально просто. Как мы увидим позже, чтобы запустить миграцию базы данных, нам просто нужно было выполнить одну команду на одном хосте:
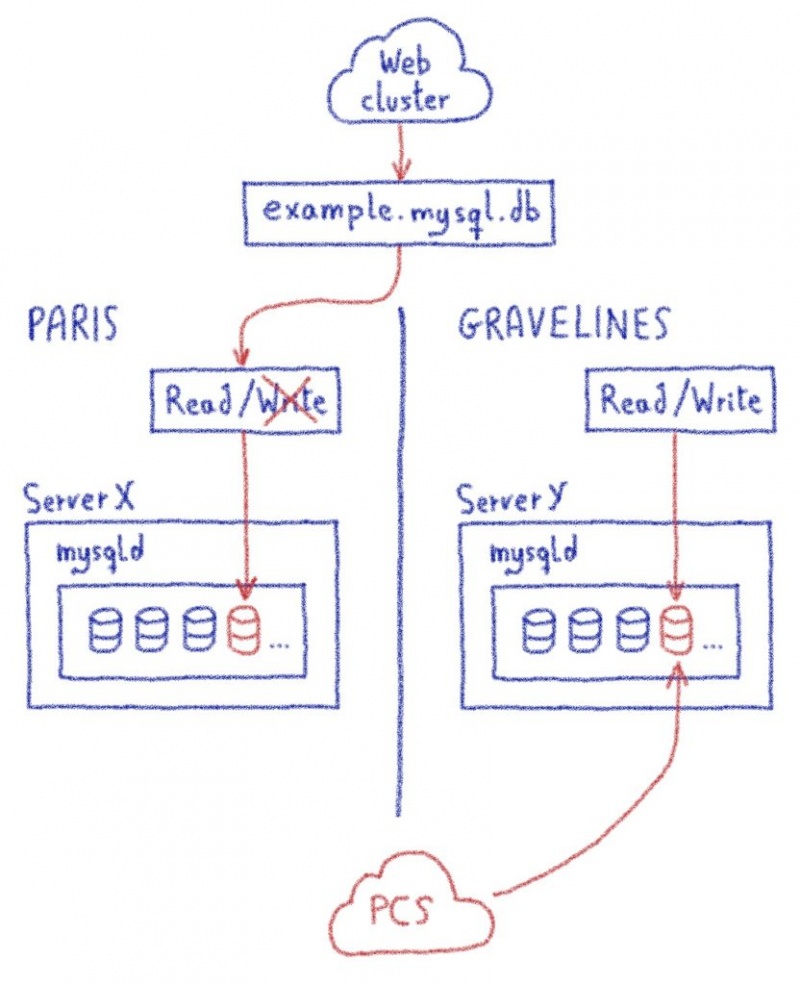
 2. В пункте назначения (Гравелин)
2. В пункте назначения (Гравелин)
Получить дамп и импортировать его.
Создайте пользователя и разрешения с правами записи.
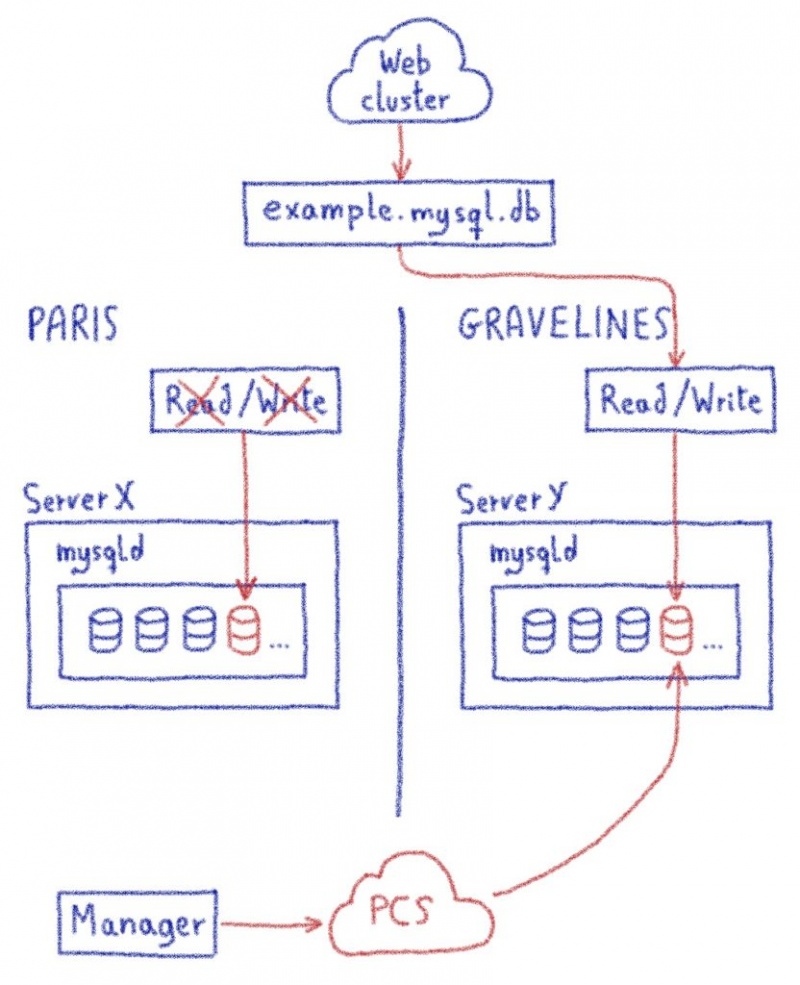
 3. Переключиться на новую базу данных
3. Переключиться на новую базу данных
На данный момент сайт все еще вызывает базу данных в Париже. Таким образом, веб-сайт (независимо от того, находится ли он в Париже или Gravelines) может связываться с новой базой данных, мы будем обновлять DNS, чтобы имя указывало на экземпляр Gravelines MySQL, а не на Париж.
Доступ для чтения к парижской базе данных также удален.
Наконец, мы обновим нашу информационную систему, чтобы вы могли получить дамп с PCS через панель управления. Это обновление также позволяет нам перенаправить все действия, доступные из панели управления (например, изменить пароль, создать дамп), в новую базу данных на Gravelines.
 Уровень 2: «Децентрализованный конечный автомат»
Уровень 2: «Децентрализованный конечный автомат»
Чтобы подтвердить концепцию миграции, сначала мы выполнили все эти шаги вручную и последовательно. Естественный способ автоматизировать это — написать скрипт, который сделает то же самое, но быстрее. Это централизованный метод, но такие методы рано или поздно сталкиваются с узкими местами и предполагают единую точку отказа.
Чтобы предотвратить это и выполнить наши требования к масштабируемости, мы должны быть децентрализованы. Мы должны представить миграцию одной базы данных как конечного автомата. Вот упрощенная версия графа состояний миграции базы данных, как описано выше:
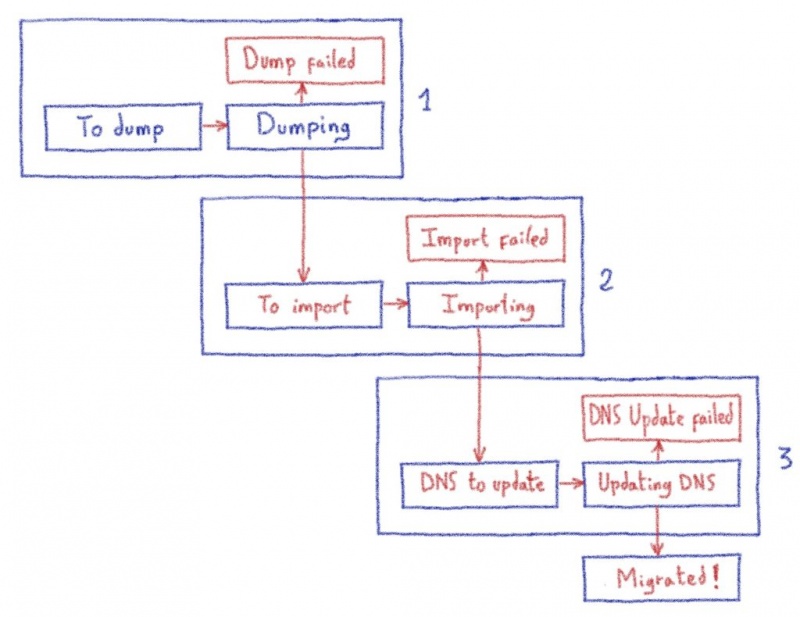
Используя этот конечный автомат, мы можем выполнить эти три больших шага на разных машинах для распараллеливания рабочей нагрузки:
- Источник
- Пункт назначения
- Тот, который обновляет DNS
Эти три хоста могут выполнять свои задачи независимым и децентрализованным способом. Все, что им нужно сделать, это посмотреть граф состояний, чтобы увидеть, есть ли у них что-то, и, если да, обновить его и выполнить задачи.
Мозг миграции: CloudDB
Мы любим концепцию «ешь свою еду»! Это самый лучший контроль качества, и благодаря отзывам, которые вы нам предоставили, наш первый источник запросов по функциям. Поэтому неудивительно, что мы использовали наш собственный продукт CloudDB для хранения графиков состояний миграций баз данных.
Технически граф состояний — это строка в таблице. Упрощенная структура этой таблицы выглядит следующим образом:
- database_name VARCHAR(255) PRIMARY KEY,
- source VARCHAR(255),
- destination VARCHAR(255),
- status VARCHAR(255) NOT NULL DEFAULT 'Waiting',
- dump_url TEXT
За исключением dump_url, все поля заполняются до начала миграции. Другими словами, мы знаем, где находятся базы данных и где они будут.
Мы победили все проблемы этого уровня. Теперь пришло время победить финального монстра!
Уровень 3: Миграция 800K баз данных
Теперь, когда мы знаем, как переносить одну базу данных децентрализованным способом, давайте заполним CloudDB всеми базами данных, которые мы хотим перенести! Вот как выглядит миграция:
В Париже
Примерно раз в минуту * каждый хост из 780 серверов баз данных спрашивает CloudDB, есть ли у них что-то, что нужно выгрузить. Столбцы источника и состояния таблицы используются для получения этой информации:
SELECT … WHERE source = me AND status = 'To dump';
Если это так, они выполняют свои задачи и обновляют CloudDB о том, что они делают. Когда они закончат, они передают эстафету для этой миграции Гравелинам:
UPDATE … SET status = 'To import' WHERE database_name = '…';
В гравелинах
В то же время, в 300 километрах, сотни серверов баз данных также спрашивают CloudDB, есть ли у них что-то для импорта. Как и в Париже, они запрашивают CloudDB примерно раз в минуту *. Столбцы назначения и состояния таблицы используются для получения этой информации:
SELECT … WHERE destination = me AND status = 'To import';
Если это так, они выполняют свои задачи и обновляют CloudDB о том, что они делают. По завершении они передают эстафету третьему роботу, который изменит записи DNS для этой миграции базы данных:
UPDATE … SET status = 'DNS to update' WHERE database_name = '…';
Чтобы избежать переполнения CloudDB, мы используем случайную частоту для запроса базы данных с графиками состояний. Таким образом, соединения глобально распределяются во времени.
Обновление DNS
Робот, отвечающий за обновление DNS, является третьим игроком в процессе миграции и работает так же, как роботы дампа и импорта, описанные выше.
Не так просто ...
Конечно, реальная игра была более сложной. Это была упрощенная версия миграции, в которой некоторые шаги отсутствуют или недостаточно подробны, например:
- Предотвращение записи в исходную базу данных
- Обновление IS (среди прочего), чтобы вы могли видеть дамп в панели управления
- Установка пароля в пункте назначения (так же, как в источнике), не зная его
- И многие другие
Но теперь, когда у вас есть концепция основных шагов, вы можете представить, как мы справились с остальными.
тепловой код: итерация!
Вы знаете закон действительно больших чисел? В нем говорится, что при достаточно большом количестве образцов может наблюдаться любая маловероятная вещь.
Это один из первых уроков, которые вы изучаете, когда размещаете 1,2 миллиона баз данных. Каждый день мы сталкиваемся со многими невероятными вещами, которые могут случиться с базами данных, поэтому мы знали, что, несмотря на проведенные нами тесты, мы столкнемся с трудностями, странными случаями и невероятными узкими местами.
Но для этого босса есть чит-код: итерация!
- Начните миграцию
- Столкнуться с проблемой
- Исправьте это окончательно (не только для конкретного случая, который потерпел неудачу, но также и для всех подобных случаев на всей платформе)
- Тогда попробуйте еще раз, быстрее!
Этот метод возможен благодаря двум вещам:
- Волшебная команда
- Большая красная кнопка
Волшебная команда
Как упоминалось выше, для запуска миграции базы данных нам нужно было выполнить одну команду на одном хосте:
migrate-p19
Эта магическая команда имеет один параметр: количество параллельных миграций, которые вы хотите выполнить. Мы использовали 400 для этого параметра.
migrate-p19 --max-procs 400
Это означает, что 400 баз данных выгружаются или импортируются одновременно — не больше, не меньше.
Команда migrate-p19 является планировщиком. Он обновляет CloudDB каждые 10 секунд, поэтому мы всегда выполняем эти 400 миграций параллельно:
SELECT COUNT(database_name) … WHERE status in ('To dump', 'Dumping', 'Dump failed', 'To import', …);
42
UPDATE … SET status = 'To dump' WHERE status = 'Waiting' LIMIT (400 - 42);
Приостановить игру: большая красная кнопка
На каждой машине обязательно иметь большую красную кнопку, чтобы нажимать, когда что-то не так. Чтобы прервать миграцию по той или иной причине, нам просто нужно убить скриптigration-p19. Когда мы делаем это, текущие миграции прекращаются, после чего новые не запускаются.
Прерывание происходит автоматически. Если что-то действительно плохо, планировщик может увидеть, что в состоянии ошибки слишком много операций, и затем принять решение остановить миграцию.