Анализ логов Object Storage при помощи DataLens

Как настроить экспорт логов из Yandex Object Storage и наглядно их анализировать при помощи интерактивных графиков в Yandex DataLens.
Логи
Для начала нам нужно включить экспорт логов Object Storage. Для этого нужно сделать запрос в API сервиса, потому что в UI пока этой опции нет. Запрос можно сделать любым способом, но удобнее всего для этого использовать утилиту aws-cli.
Если у вас не настроена эта утилита, то инструкцию по настройке можно найти в документации.
Чтобы включить логирование запросов для бакета, нужно выполнить следующую команду:
aws s3api put-bucket-logging \
--endpoint-url=https://storage.yandexcloud.net\
--bucket $BUCKET \
--bucket-logging-status file://log-config.jsonгде вместо $BUCKET вам нужно подставить имя вашего бакета, а файл log-config.json должен содержать следующее:
{
"LoggingEnabled": {
"TargetBucket": "$LOGS_BUCKET",
"TargetPrefix": "s3-logs/"
}
}Соответственно, $LOGS_BUCKET нужно заменить на имя бакета, куда будут складываться логи.
ClickHouse
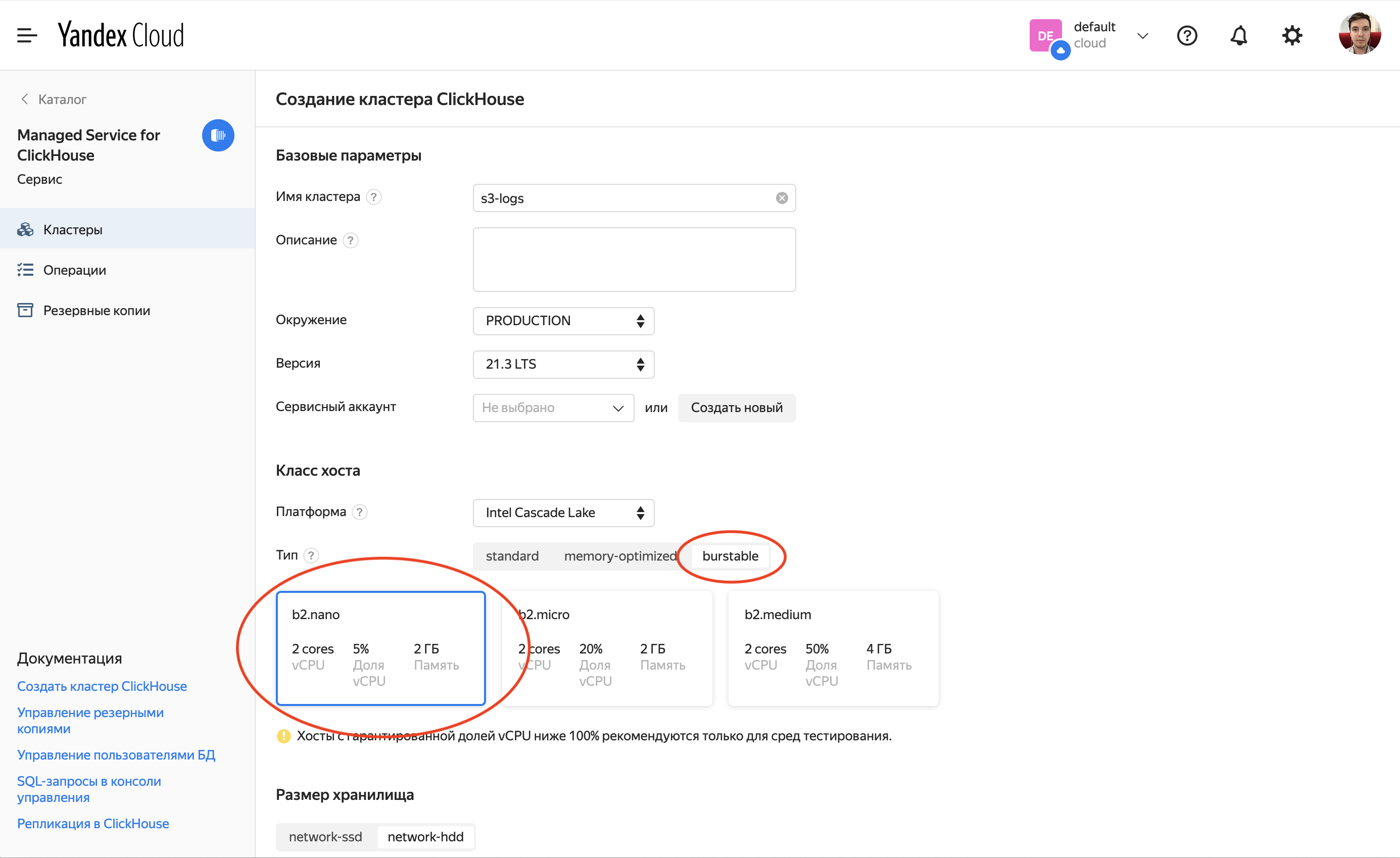
Вторым этапом будет создание кластера Managed Service for ClickHouse. Он будет выступать источником данных для DataLens.
Для наших целей нам подойдет самый маленький кластер burstable-типа. Создание кластера может занять значительное время.
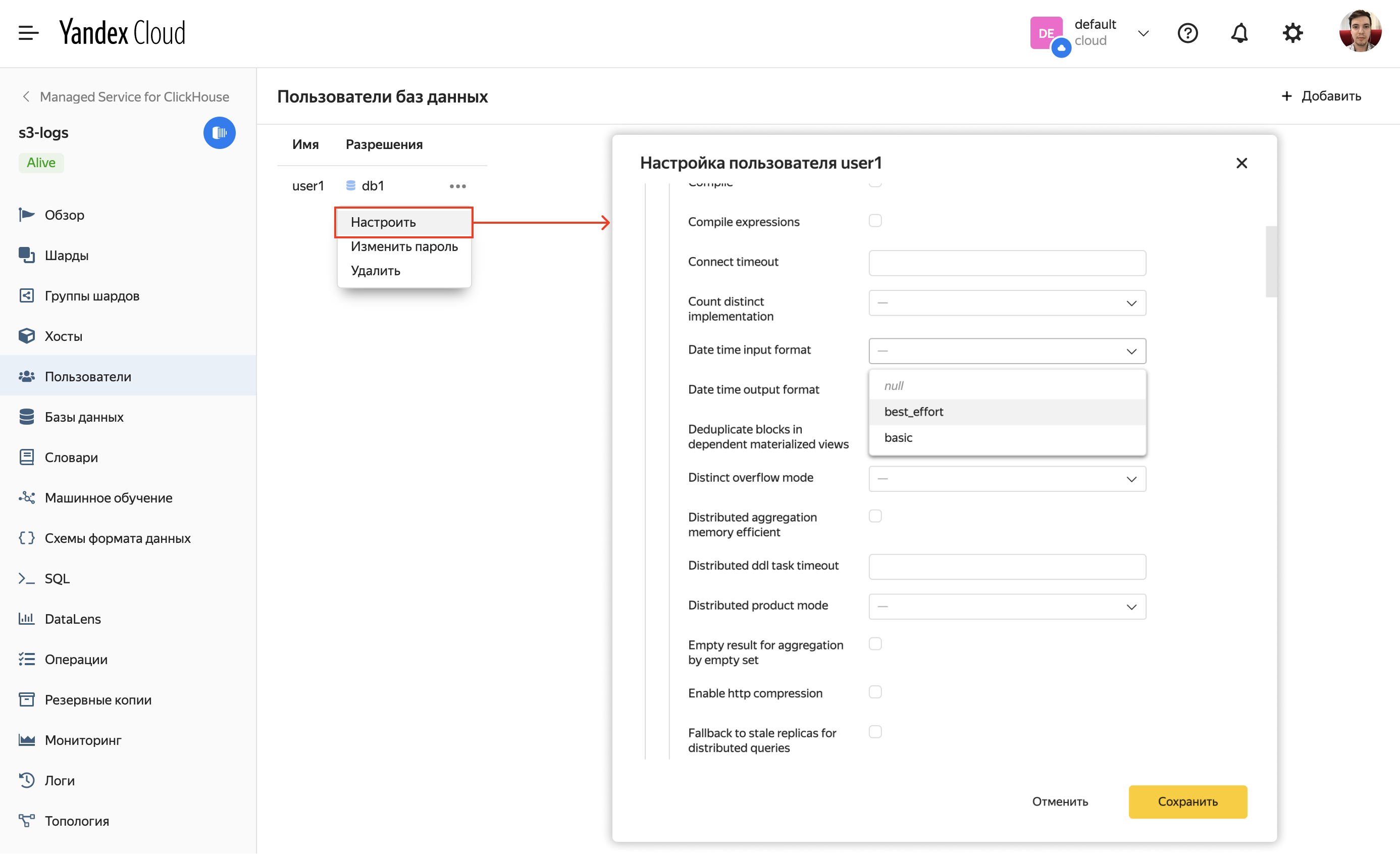
Когда кластер будет создан, необходимо поправить настройки пользователя. Выставить для поля Date time input format значение best_effort.
В ClickHouse реализованы разные движки таблиц. В нашем случае нам пригодится S3.
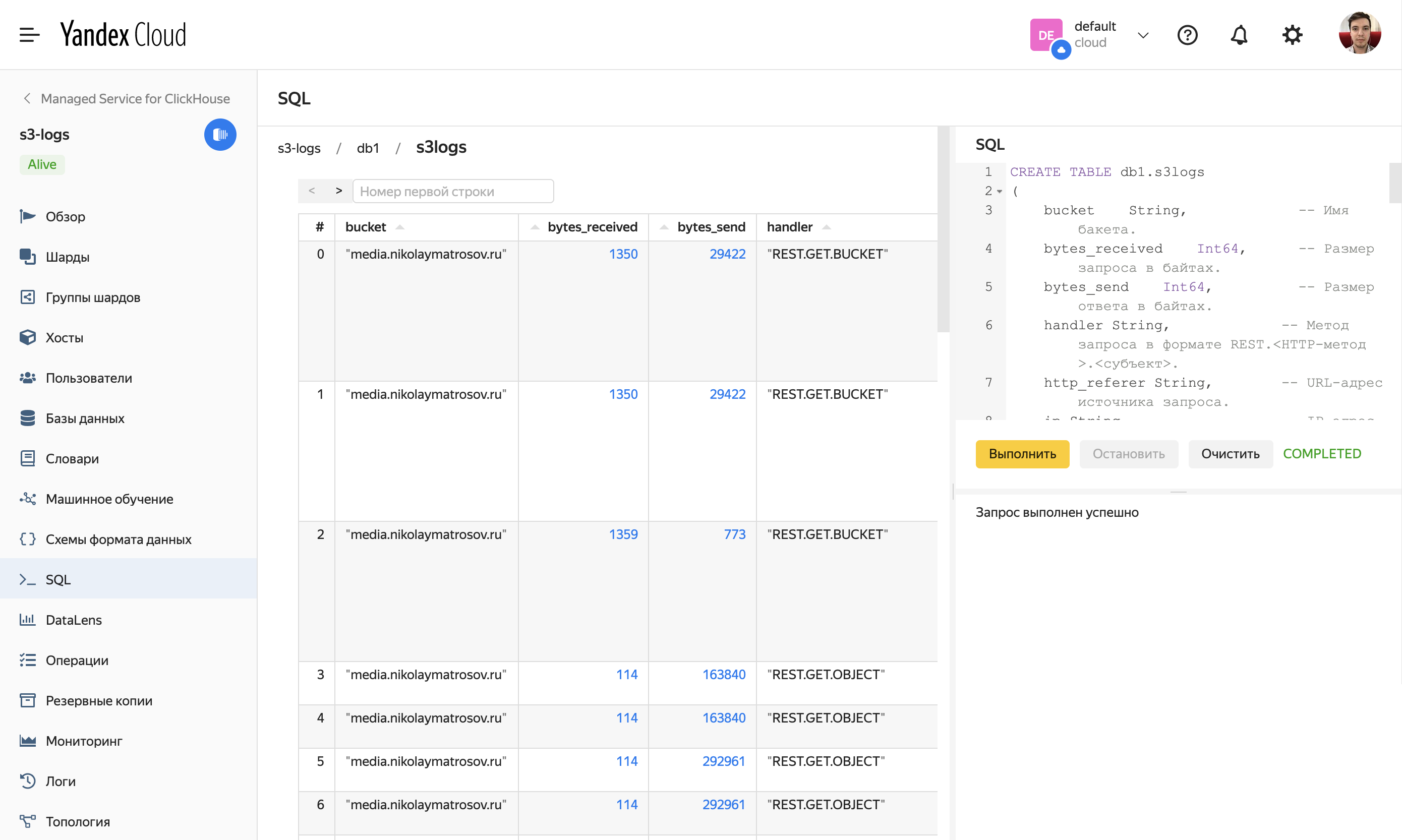
CREATE TABLE db1.s3logs
(
bucket String, -- Имя бакета.
bytes_received Int64, -- Размер запроса в байтах.
bytes_send Int64, -- Размер ответа в байтах.
handler String, -- Метод запроса в формате REST.<HTTP-метод>.<субъект>.
http_referer String, -- URL-адрес источника запроса.
ip String, -- IP-адрес пользователя.
method String, -- Метод HTTP-запроса.
object_key String, -- Ключ объекта, закодированный методом URL-кодировки.
protocol String, -- Версия протокола передачи данных.
range String, -- HTTP-заголовок, который определяет диапазон байт для загрузки из объекта.
requester String, -- Идентификатор пользователя.
request_args String, -- Аргументы URL-запроса.
request_id String, -- Идентификатор запроса.
request_path String, -- Полный путь запроса.
request_time Int64, -- Время обработки запроса, в миллисекундах.
scheme String, -- Тип протокола передачи данных.
-- Возможные значения:
-- * http — протокол прикладного уровня передачи данных.
-- * https — протокол прикладного уровня передачи данных с поддержкой шифрования.
ssl_protocol String, -- Протокол обеспечения безопасности.
status Int64, -- HTTP-код ответа.
storage_class String, -- Класс хранилища объекта.
timestamp DateTime, -- Дата и время операции с бакетом, в формате ГГГГ-ММ-ДДTЧЧ:ММ:ССZ.
user_agent String, -- Клиентское приложение (User Agent), которое выполнило запрос.
version_id String, -- Версия объекта.
vhost String -- Виртуальный хост запроса.
-- Возможные значения:
-- * storage.yandexcloud.net.
-- * <имя бакета>.storage.yandexcloud.net.
-- * website.yandexcloud.net.
-- * <имя бакета>.website.yandexcloud.net.
)
ENGINE = S3(
'https://storage.yandexcloud.net/<BUCKET_NAME>/<PREFIX>/*',
'<ACCESS_KEY>',
'<SECRET_KEY>',
'JSONEachRow'
);<ACCESS_KEY> и <SECRET_KEY> следует заменить на значения статического ключа доступа в Object Storage. Инструкция по созданию ключа доступа в документации.
<BUCKET_NAME> и нужно заменить на значения, которые указывали в log-config.json, ведь именно туда будут складываться ваши логи и именно оттуда их и будем вычитывать в ClickHouse.
Теперь можно убедиться, что все работает, перейдя в базу db1 и открыв просмотр таблицы s3logs.
DataLens
Подключение
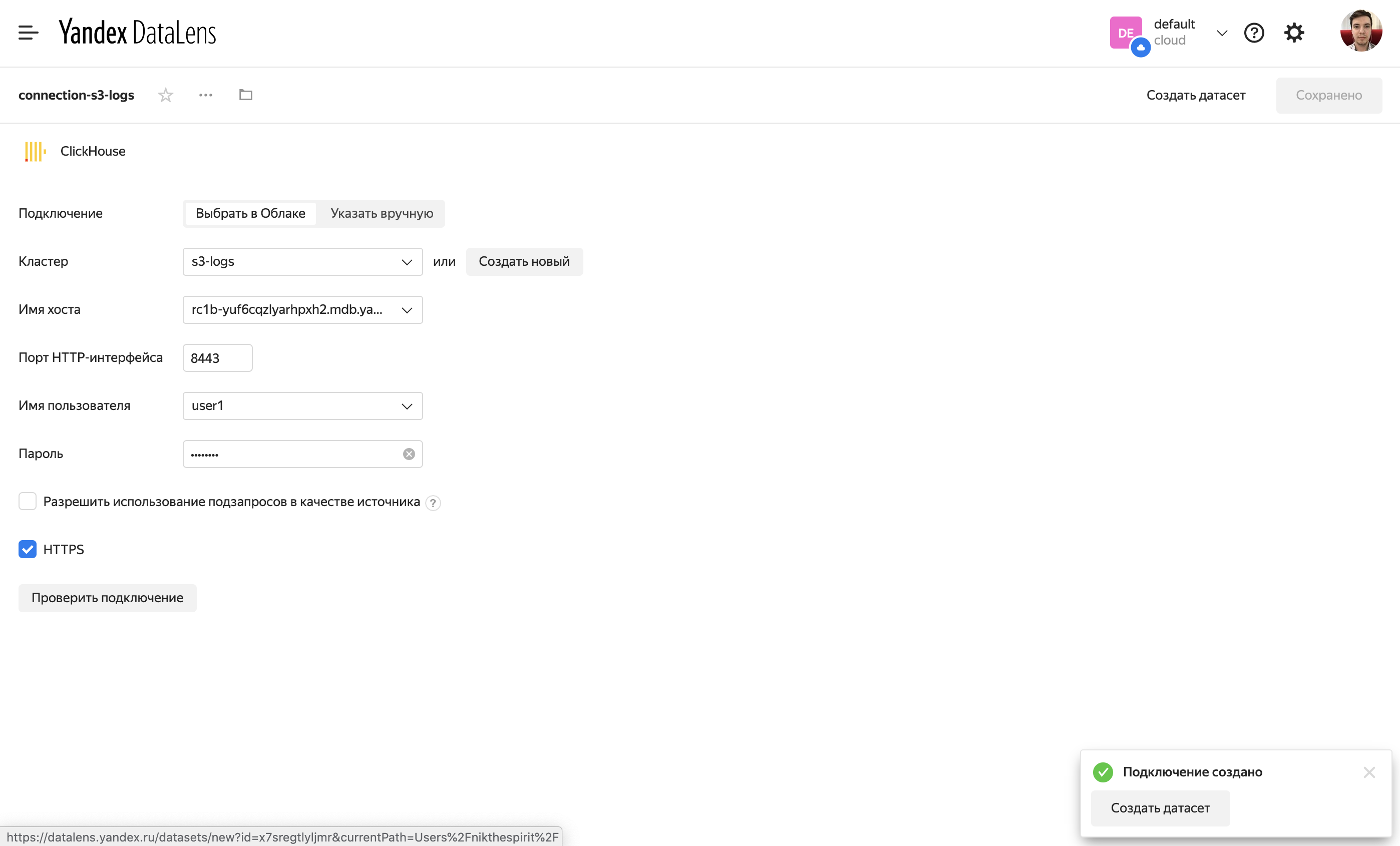
После того как кластер ClickHouse будет создан, можно перейти на вкладку DataLens и сразу создать подключение.
Датасет
Во всплывающем окне после сохранения подключения есть кнопка, позволяющая сразу перейти к созданию датасета на основе этого подключения. Нажмем её.
Перетащим из списка доступных таблиц в основную рабочую область только что созданную таблицу. Если все ок, то внизу в области предпросмотра увидим, что DataLens смог получить данные.
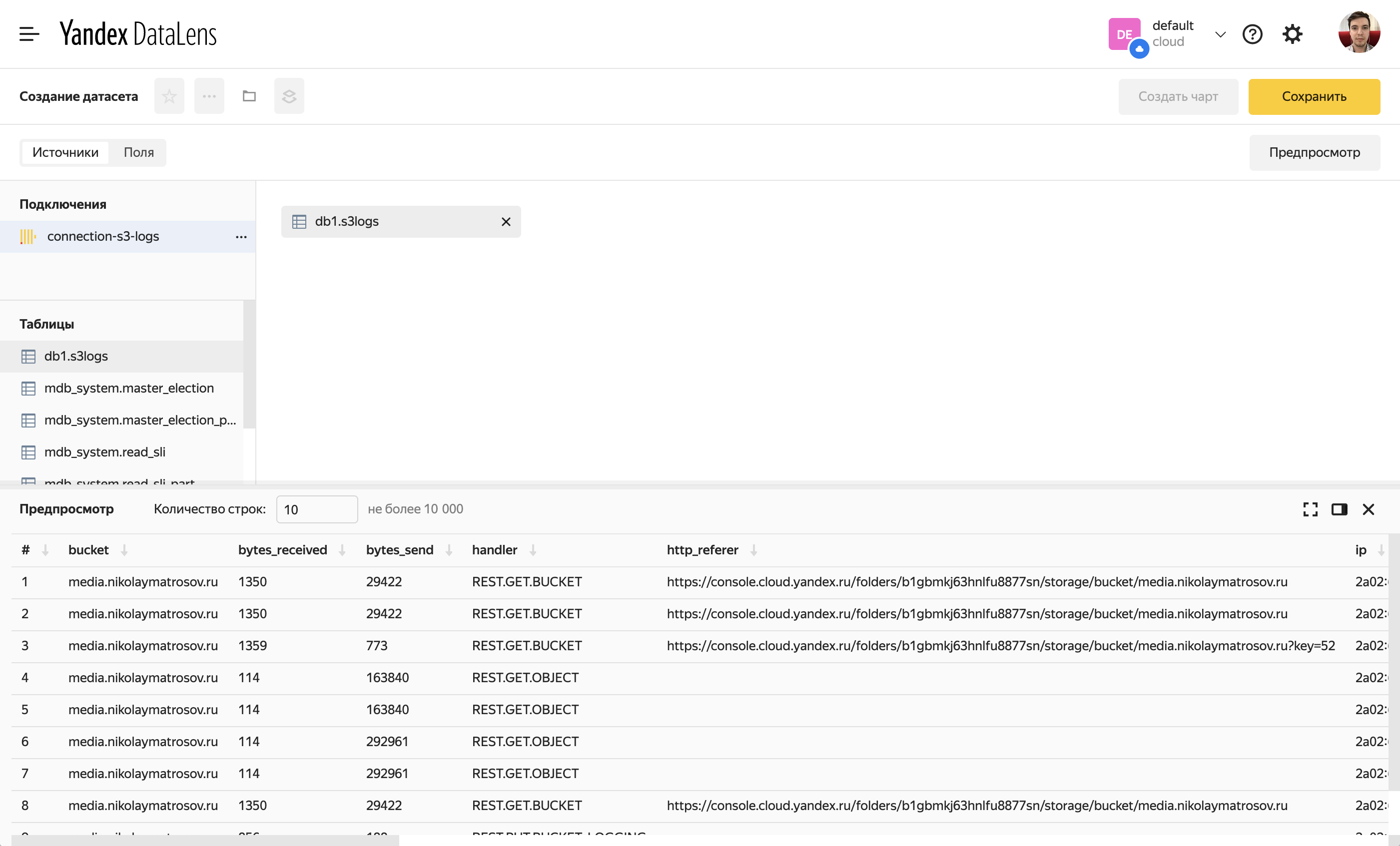
Теперь можно сохранить датасет. И приступить к созданию чартов на основе этого датасета.
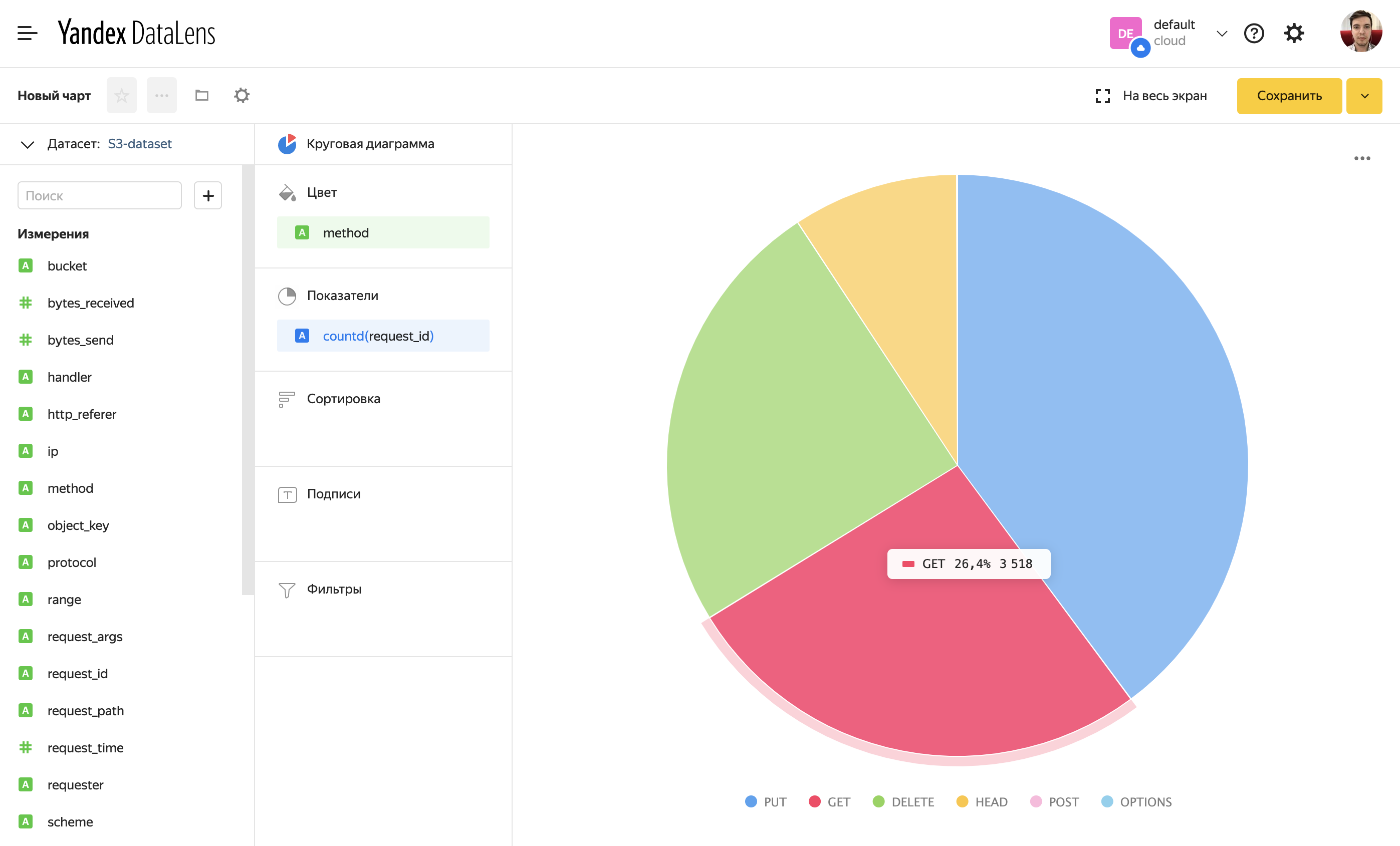
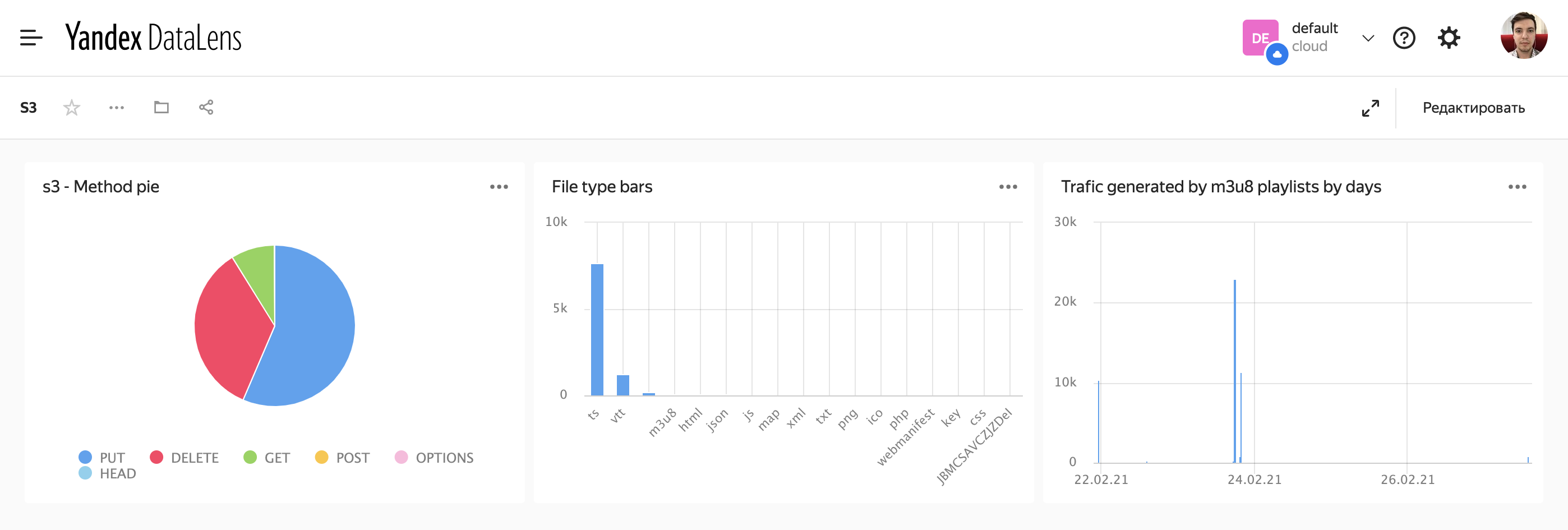
Пример диаграммы количества запросов по методу. Так как это тестовый бакет, GET-запросов оказалось даже меньше, чем PUT.
В датасет можно добавить вычисляемые поля. Например, добавим file_type. Рассчитывать это значение будем по формуле SPLIT([object_key], ‘.’, -1).
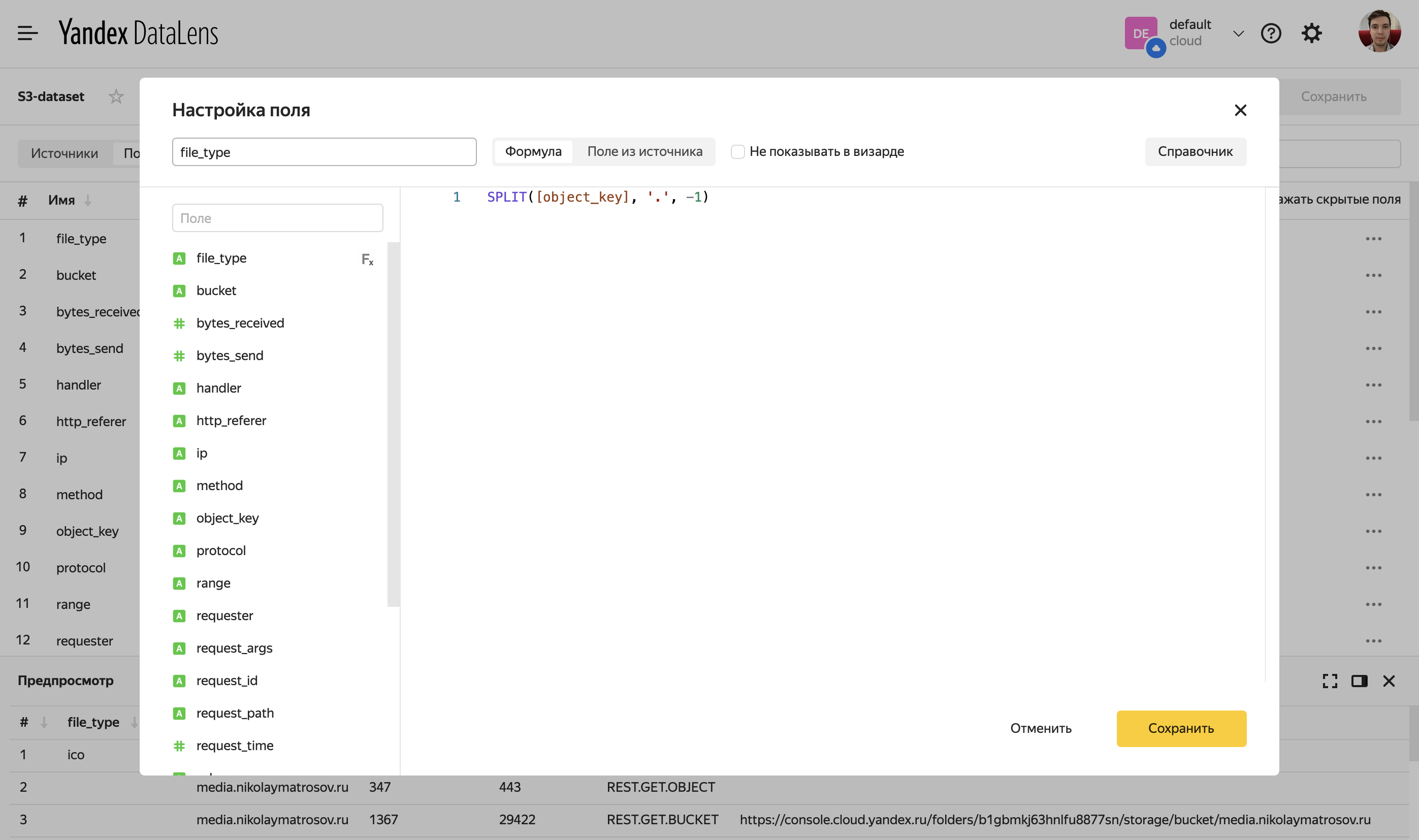
Далее мы можем использовать это значение наравне с другими в построении чартов.
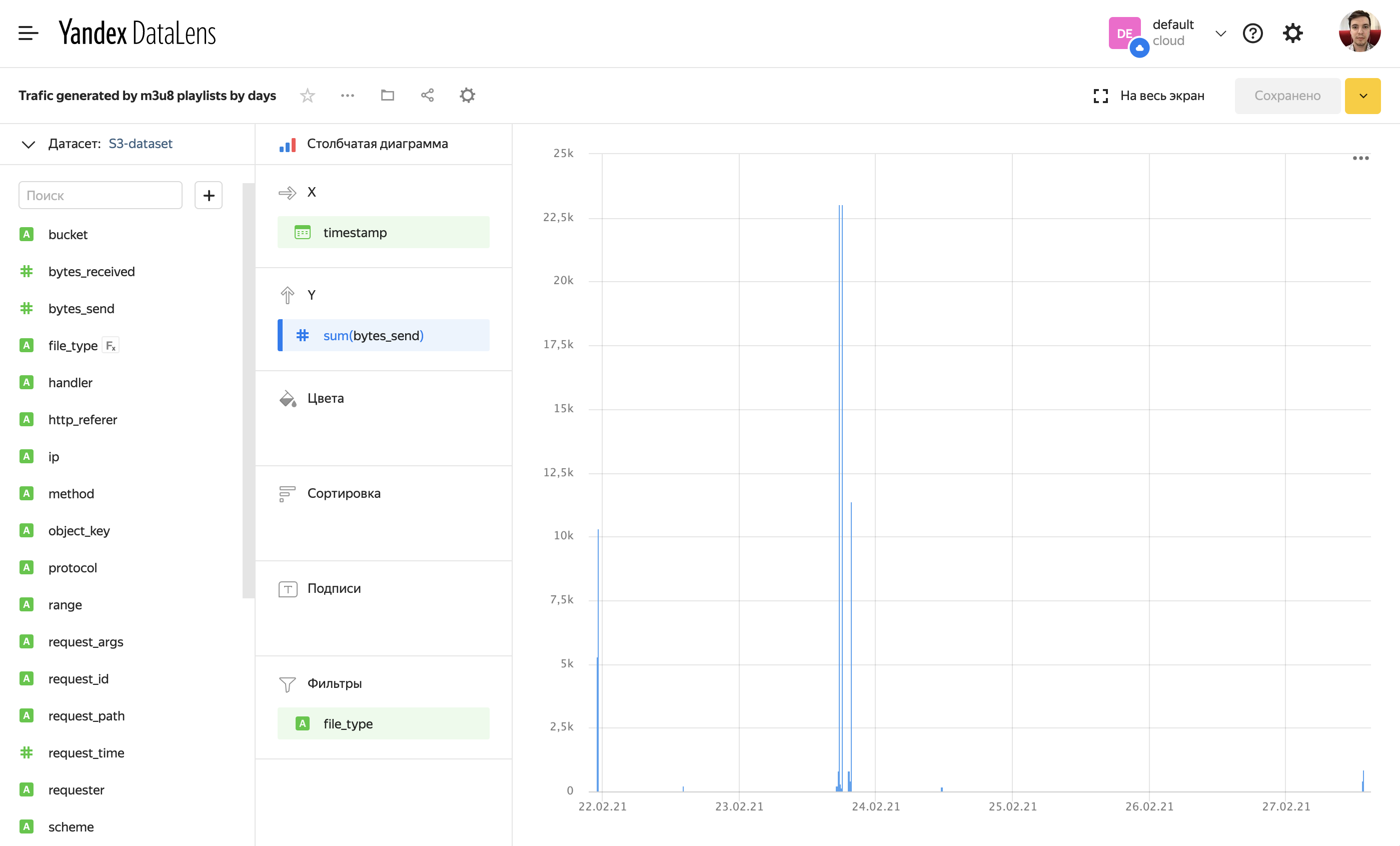
Дашборд
Все получившиеся чарты вы можете сгруппировать на дашборд.
Например, такой демо-дашборд для тестового бакета.