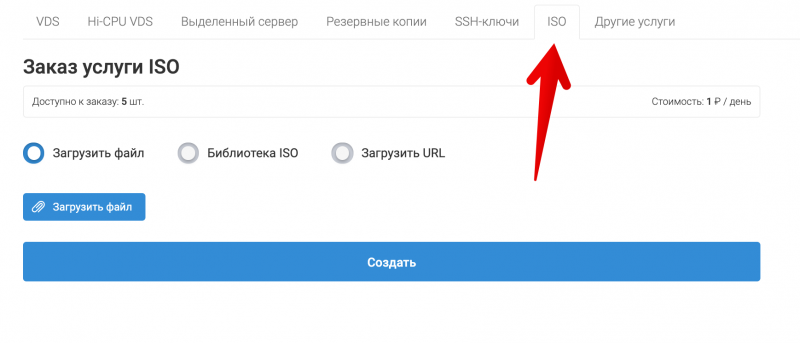
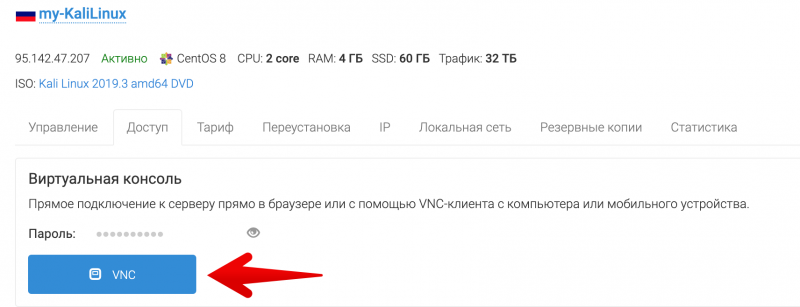
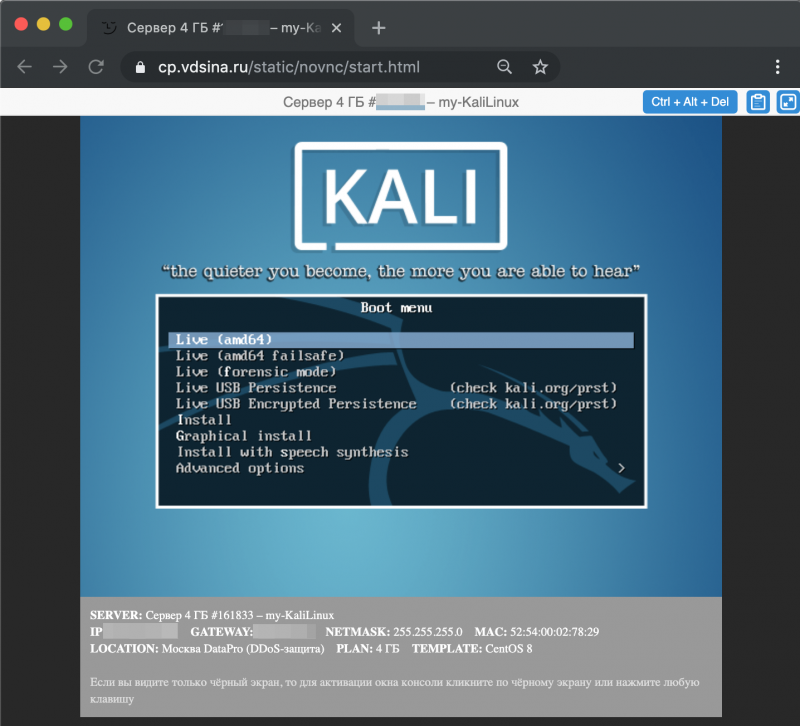
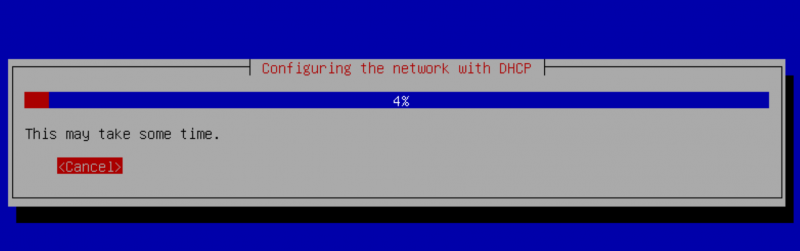
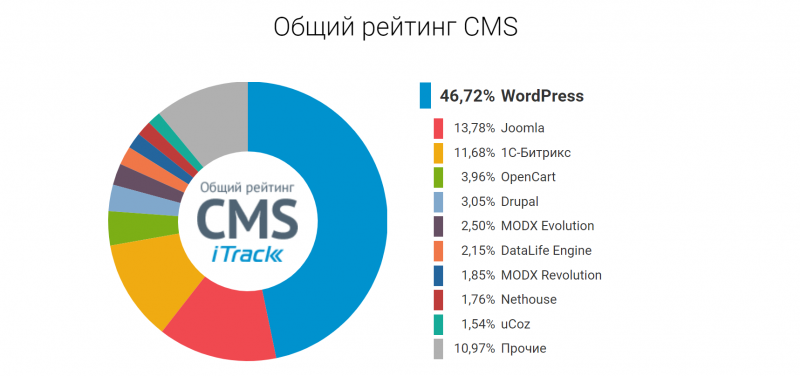
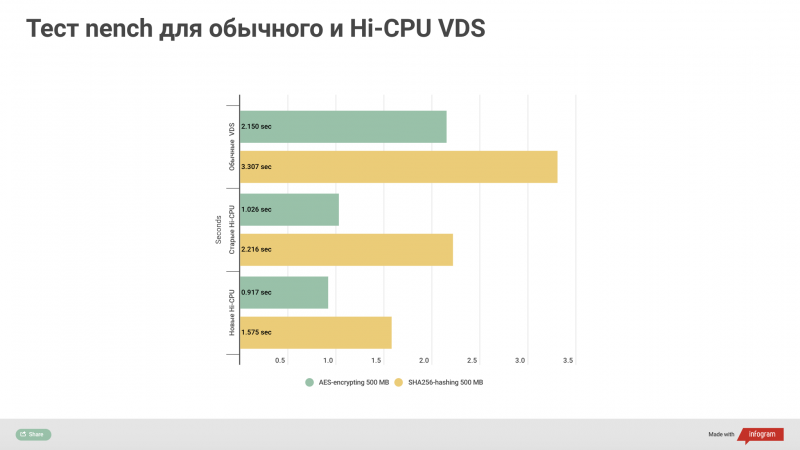
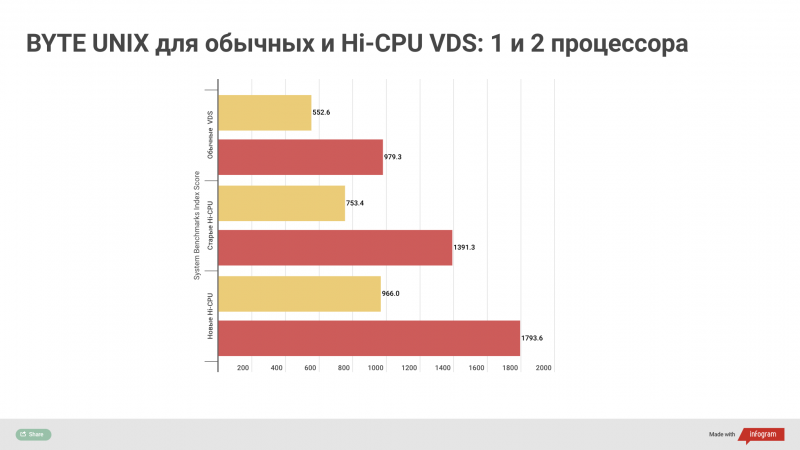
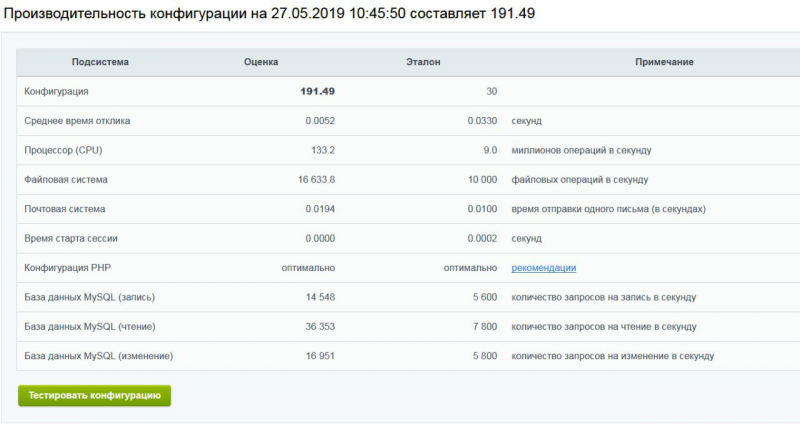
На связи Александр Чистяков, я евангелист vdsina.ru и расскажу про 9 лучших технологических событий 2019 года.
В оценке я больше полагался на свой вкус, чем на мнение экспертов. Поэтому в этот список, например, не вошли беспилотные автомобили, потому что ничего принципиально нового и удивительного в этой технологии нет.
Я не сортировал события в списке по значимости или вау-эффекту, потому что их значимость будет понятна лет через десять, а вау-эффект слишком краткосрочен, просто постарался сделать эту историю связной.
1. Переносимые серверные приложения на языке программирования Rust под WebAssembly
Я начну обзор с двух докладов:
1. Доклад Брайана Кантрилла “Время переписать ОС на Rust?”, прочитанный им ещё в 2018-м.
На момент прочтения доклада, Брайан Кантрилл работал в компании Joyent на позиции CTO и еще не догадывался, чем закончится для него и Joyent 2019-й.
2. Доклад Стива Клабника, члена core team языка Rust и автора книги “The Rust Programming Language”, работающего в Cloudflare, где он рассказывает об особенностях языка Rust и технологии WebAssembly, позволяющей использовать веб-браузеры как платформы для запуска приложений.
В 2019-ом WebAssembly со своим интерфейсом WASI, предоставляющим доступ к объектам операционной системы, такими, как файлы и сокеты, шагнула за рамки браузеров и нацеливается на рынок серверного программного обеспечения.
Суть прорыва очевидна — у человечества появляется еще один рантайм, способный запускать переносимые приложения для Web (кто-нибудь помнит принцип WORA, придуманный еще авторами языка Java?).
Кроме того, у нас появился относительно безопасный способ создавать эти приложения благодаря языку Rust, смысл существования которого в том, чтобы уничтожать целые классы ошибок еще на этапе компиляции.
WebAssembly настолько переворачивает игру, что Соломон Хайкс, один из создателей Docker, писал о том, что, если бы WebAssembly и WASI существовали в 2008-м, Docker бы просто не родился.

Неудивительно, что именно Rust оказался в рядах освоителей новой переносимой технологии — его экосистема динамично развивается и Rust уже несколько лет остается самым любимым языком программирования согласно результатам опроса, проводимого StackOverflow.
Это слайд из доклада Стива, который наглядно показывает соотношение числа ошибок безопасности, которых целиком можно избежать при использовании Rust к общему числу ошибок в MS Windows, найденных за последние полтора десятилетия.
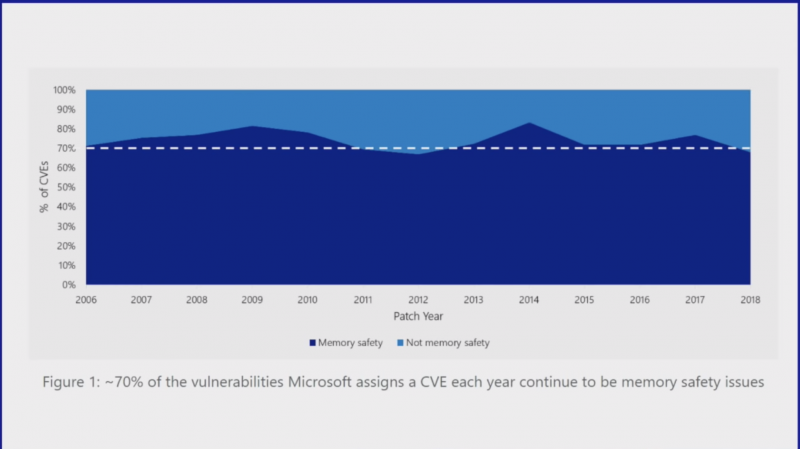
Компания Microsoft должна была как-то ответить на такой вызов, и она ответила.
2. Project Verona от Microsoft, который спасет Windows и откроет новую страницу истории для любой ОС
Количество ошибок в ядре Microsoft Windows и большинстве пользовательских программ почти линейно увеличивалось в течение последних 12 лет.
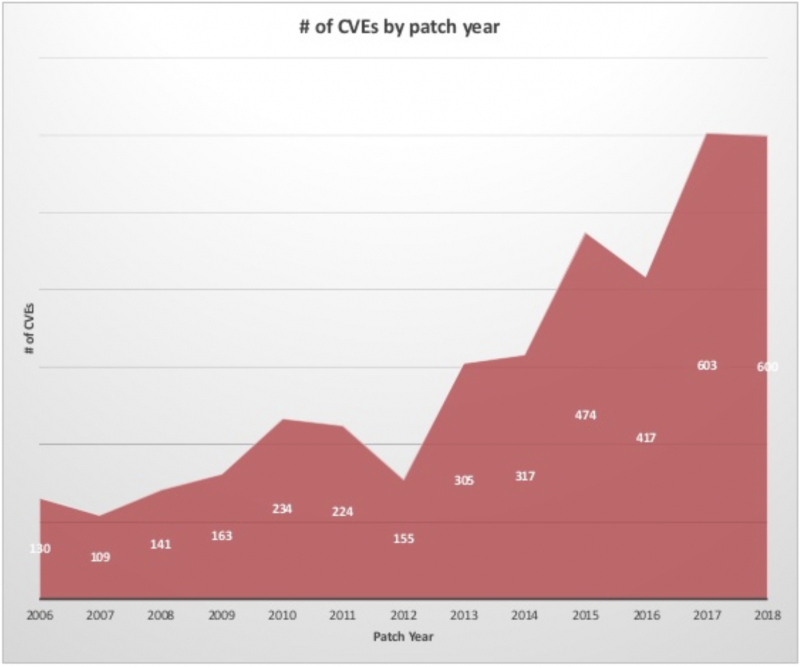
В 2019 Мэтью Паркинсон из Microsoft представил публике Project Verona, который может положить этому конец.
Это инициатива Microsoft по созданию безопасного языка программирования, основанного на идеях языка Rust: коллеги из Microsoft Research выяснили, что большинство проблем с безопасностью связано с тяжелым наследием языка C, на котором написана большая часть Windows. Rust-подобный язык Verona управляет памятью и конкурентным доступом к ресурсам, используя принцип абстракций с нулевой стоимостью. Если вы хотите подробно разобраться, как он работает, просмотрите доклад самого Паркинсона.
Интересно, что компанию Microsoft традиционно воспринимают как империю зла и противника всего нового, несмотря на то, что Саймон Пейтон-Джонс, основной разработчик Glasgow Haskell Compiler, работает именно в Microsoft.
Вопрос Брайана Кантрилла из первого пункта: “не пора ли переписать ядро операционной системы на Rust?” получил неожиданный ответ — очевидно, что ядро операционной системы переписать пока невозможно, но программы, работающие в userspace, уже переписываются. Начался неостановимый процесс, и это откроет новую страницу будущего для всех операционных систем.
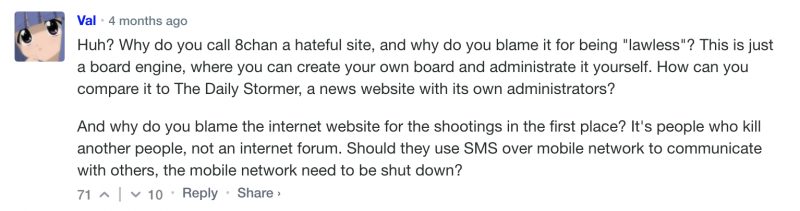
3. Взлет популярности языка программирования Dart благодаря фреймворку Flutter
Я уверен, что следующая новость является большим сюрпризом не только для нас и широкой публики, но и для большинства непосредственных участников процесса её формирования. Язык программирования Dart, появившийся в Google восемь лет назад, в этом году показал стремительный рост популярности.
Я использую свой метод оценки популярности языков программирования при помощи анализа репозиториев на Github, раз в месяц обновляя данные в таблице. Если в начале года популярных репозиториев на Dart было всего 100, то сегодня их уже 313.
Dart обогнал по популярности Erlang, PowerShell, R, Perl, Elixir, Haskell, Lua и CoffeeScript. Быстрее, кажется, в этом году не рос ни один другой язык программирования. Почему так произошло?
Один из знаковых докладов этого года по версии аудитории HackerNews был прочитан Ричардом Фельдманом и назывался “Почему функциональное программирование не является нормой?” Значительная часть доклада посвящена анализу того, каким образом языки программирования становятся популярными. Одна из основных причин, по версии Ричарда — наличие популярного приложения или фреймворка, иначе говоря the killer app.
Для языка Dart причиной популярности стал фреймворк разработки мобильных приложений Flutter, взлет популярности которого, согласно Google Trends, как раз пришелся на начало этого года.
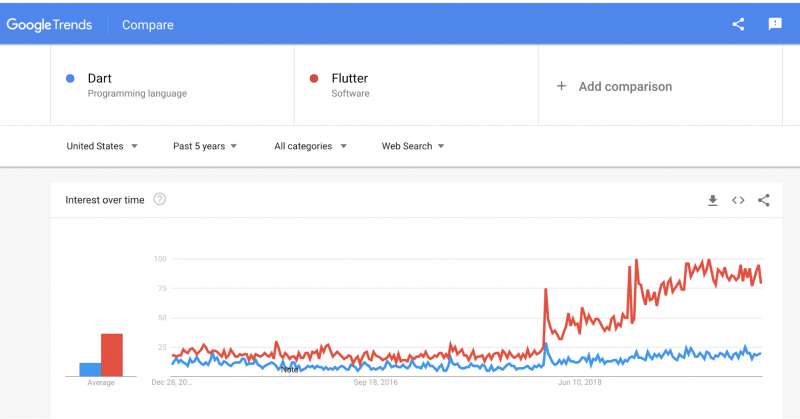
Мы ничего не знаем про Dart, так как не занимаемся мобильной разработкой, но горячо приветствуем еще один язык программирования со статической типизацией.
4. Шанс на выживание ядра Linux и его коммьюнити благодаря вирутальной машине eBPF
Мы в VDSina любим конференции: в этом году я ездил на конференции DevOops в Санкт-Петербурге и участвовал в круглом столе, посвященном трендам и горячим штучкам в индустрии. В 2019-м в таких разговорах лидировали мнения:
- Docker мертв, потому что слишком скучен
- Kubernetes жив и протянет где-то год — о нём ещё будут говорить на конференциях в 2020 году
- тем временем, в ядро Linux никто из живых людей не заглядывает уже давно
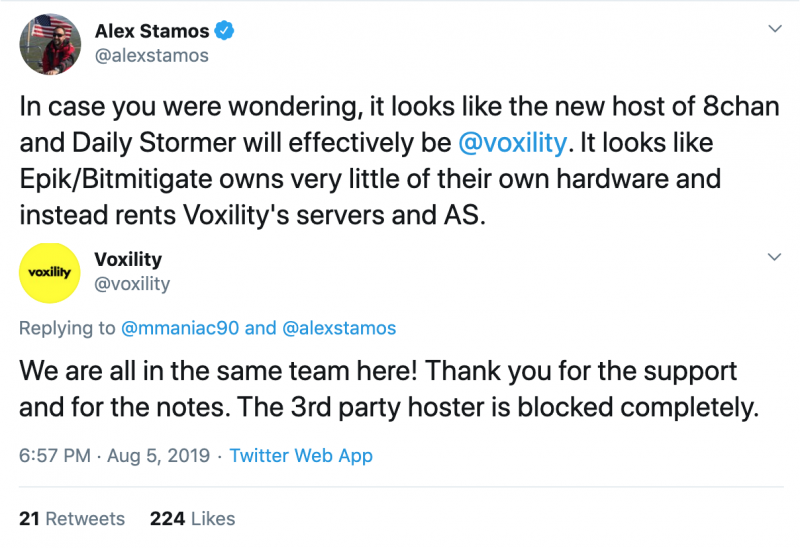
Я не разделяю последнего пункта, с моей точки зрения, в разработке ядра Linux сейчас происходят не просто интересные, а революционные вещи. Самая заметная — виртуальная машина eBPF, изначально созданная для решения скучнейшей задачи фильтрации сетевых пакетов, а потом переросла в виртуальную машину уровня ядра общего назначения.
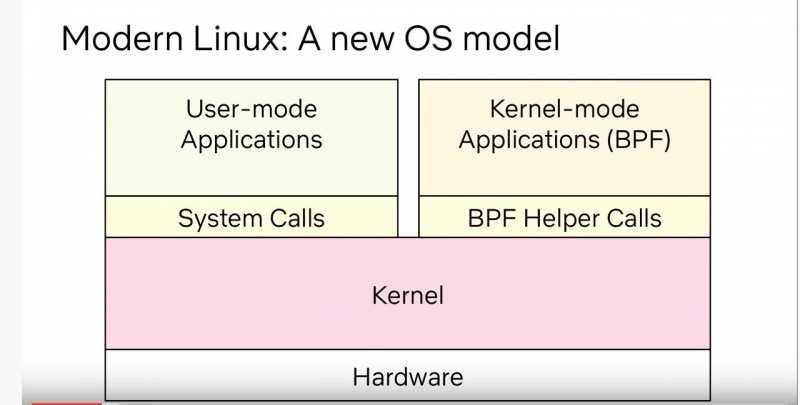
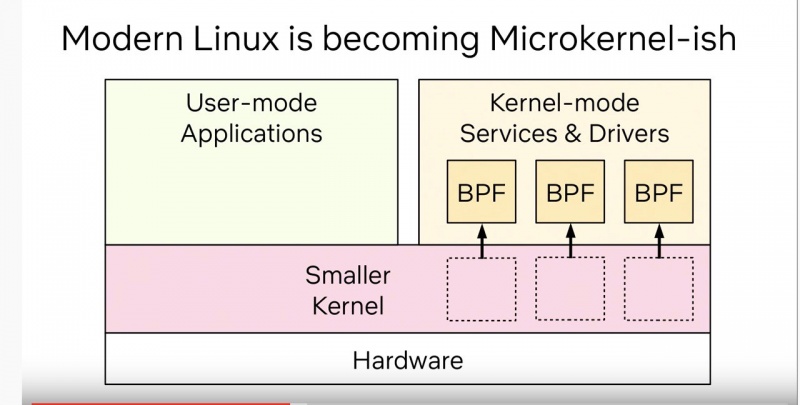
Благодаря eBPF, ядро теперь сообщает о наступлении событий, которые можно частично обрабатывать вне ядра — интерфейс дает возможность безопасно и эффективно взаимодействовать с ядром из userspace и расширять и дополнять функциональность ядра Linux, минуя всевидящее око Линуса Торвальдса.
До eBPF разработка программ, деятельность которых тесно связана с взаимодействием с ядром Linux была непростой историей — для создания вещей вроде драйверов не очень быстрых устройств и интерфейсов для файловых систем в userspace требовалось проходить формальную процедуру review опытными разработчиками ядра Linux.
Появление интерфейса eBPF сильно упростило процесс написания таких программ — входной порог понизился, разработчиков станет больше и коммьюнити снова оживёт.
Я не одинок в своем энтузиазме: разработчик ядра с многолетним стажем Дэвид Миллер декларирует важность eBPF для выживания (!) экосистемы разработки ядра. Другой, не менее известный разработчик Брендан Грегг (я его большой фанат) называет eBPF прорывом, равного которому не было 50 лет.
Тем временем Линус Торвальдс за подобное обычно публично не хвалит и я могу его понять — кому хочется публично выставлять себя идиотом? :)
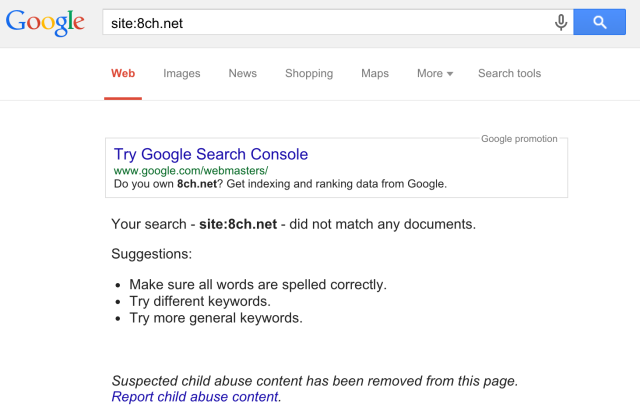
 5. Linux забил почти последний гвоздь в гроб FreeBSD благодаря асинхронному интерфейсу io_uring в ядре Linux
5. Linux забил почти последний гвоздь в гроб FreeBSD благодаря асинхронному интерфейсу io_uring в ядре Linux
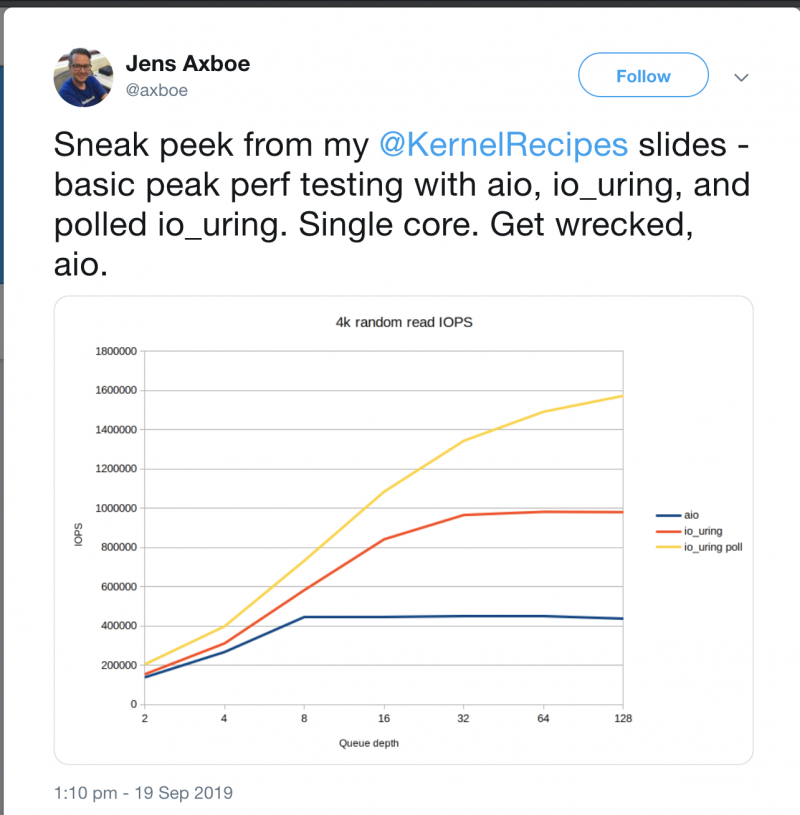
Раз уж речь зашла о ядре Linux, необходимо отметить и другое значительное улучшение, происшедшее в этом году: включение в ядро нового высокопроизводительного асинхронного API ввода/вывода io_uring за авторством Дженса Эксбоу из Facebook.
Много лет системные администраторы и разработчики под FreeBSD обосновывали свой выбор фактом, что во FreeBSD асинхронный ввод-вывод был сделан лучше, чем в Linux. Например, этот аргумент использовал в своем докладе в 2014-ом году Глеб Смирнов из Nginx.
Теперь игра перевернулась. На использование io_uring уже перешла распределённая файловая система Ceph и результаты тестов производительности впечатляют — рост количества операций ввода/вывода в секунду составляет от 14% до 102% в зависимости от размера блока. Существует прототип, использующий асинхронный ввод-вывод в PostgreSQL (по крайней мере, для background writer), запланированы дальнейшие работы по переводу PostgreSQL на асинхронный ввод-вывод. Но учитывая консервативность сообщества разработчиков, в 2020-м эти изменения мы еще не увидим.
 6. Триумфальное возвращение компании AMD с линейкой процессоров Ryzen
6. Триумфальное возвращение компании AMD с линейкой процессоров Ryzen
Ничего необычного, просто компания AMD, долгое время бывшая в индустрии на вторых ролях, бьёт рекорд за рекордом.
Новая линейка процессоров Ryzen показала невероятное соотношение цена/производительность: они доминируют в списке самых продаваемых процессоров на Amazon, а в некоторых регионах продажи процессоров AMD превысили продажи Intel. В конкурентной борьбе Intel вынуждена идти на крайне непопулярные меры: заставляет программы, созданные при помощи их собственного компилятора, работать менее эффективно на процессорах конкурента. Несмотря на грязные способы борьбы Intel, рыночная оценка AMD вплотную приблизилась к рекордным значениям 2000-го года.
7. Вслед за AMD, Apple целится откусить кусок пирога Intel с помощью iPadOS и старых уловок Гейтса
В битвах гигантов обычно пытаются участвовать все, кто может держать в руках оружие, и на кормовую базу Intel претендует не только компания AMD. Компания Apple повела себя как старый бык из анекдота.
Выпустив новый iPadOS, Apple использовала против Intel тактику, которая называется “disruptive innovation” — подрывные инновации.
Определение Википедии
«Подрывные инновации» (англ. Disruptive innovation) — инновации, которые изменяют соотношение ценностей на рынке. При этом старые продукты становятся неконкурентоспособными просто потому, что параметры, на основе которых раньше проходила конкуренция, теряют свое значение.
Примерами «подрывных инноваций» являются телефон (заменил телеграф), пароходы (заменили парусные суда), полупроводники (заменили электровакуумные приборы), цифровые камеры (заменили пленочные), электронная почта («подорвала» традиционную почту).
Apple использует свои собственные процессоры на базе ARM с низким энергопотреблением и это оказалось для пользователей более важным, чем немного отстающая от Intel x86 производительность.
Apple успевает урвать часть рынка, превращая iPad из терминала для развлечений в полноценный рабочий инструмент — сначала для тех, кто создает контент, а теперь и для разработчиков. Конечно, в ближайшее время мы не увидим MacBook на базе ARM, но маленькие неприятности с дизайном клавиатур MacBook Pro способствуют поиску альтернативных решений и одним из них обещает стать iPad Pro с iPadOS.
Причем тут Гейтс и Microsoft?
В свое время Гейтс провернул точно такой же трюк с IBM.
В 1970-х IBM доминировал на рынке серверов, с уверенностью гиганта не обращая внимания на персональные компьютеры для обывателей. В 1980-х Гейтс создает на деньги IBM и лицензирует для него MS-DOS, оставляя права на операционную систему на себя. Получив деньги, Microsoft создает под MS-DOS графический интерфейс, и рождается Windows — сначала просто графическая надстройка над DOS, а потом и первая операционная система под PC, удобная для использования широкими массами. IBM, будучи большой неповоротливой компанией проигрывает рынок персональных компьютеров молодой и быстрой Microsoft. Я очень кратко пересказал эту замечательную историю, поэтому если вам интересно, как в 2020-ом Apple будет играть против Intel с помощью iPadOS, очень рекомендую прочитать её целиком.
8. Укрепление позиций ZFSonLinux — старый конь борозды не портит
Компания Canonical представила возможность установки Ubuntu с использованием файловой системы ZFS в качестве root file system прямо из инсталлятора. Иногда мне кажется, что инженеры, работавшие в Sun Microsystems, представляют собой отдельный биологический вид человека разумного (уже упоминавшиеся выше Брайан Кантрилл и Брендан Грегг работали в Sun). Посудите сами, несмотря на многолетние попытки всего человечества сделать что-то, хотя бы, отдаленно похожее на файловую систему ZFS, несмотря на неразрешимые лицензионные ограничения, препятствующие включению исходного кода ZFS в основную ветку разработки ядра Linux, мы все еще используем ZFS, и в ближайшее время ситуация не изменится.
9. Oxide Computer Company — мы будем пристально следить за командой, которая явно способна на многое — как минимум, создать крутое шоу
Я завершаю свой список новым упоминанием Брайана Кантрилла, с которого я и начал.
Брайан Кантрилл с другими инженерами (некоторые из которых тоже раньше работали в Sun) основал предприятие под названием Oxide Computer Company, основная цель которого — создание серверной платформы, пригодной для использования в больших масштабах. Известно, что очень большие корпорации, такие как Google, Facebook и Amazon, не используют в своей деятельности обычное серверное железо. Компания Брайана призвана устранить это неравенство, разработав программно-аппаратную платформу, пригодную для использования любым облачным сервисом (не обойдется и без языка программирования Rust).
Их задумка — обещание новой революции, и я буду, как минимум, с удовольствием наблюдать за движением их мысли и их разработкой в грядущем 2020 году.
Что мы успели сделать в 2019 в VDSina
Технологических прорывов в 2019 с VDSina мы не делали, но нам все равно есть, чем гордиться.
В феврале мы добавили возможность использовать локальную сеть между серверами и запустили услугу регистрации доменов. Цену сделали одной из самых низких на рынке — 179 руб за ru/рф, в том числе и за продление.
В марте выступили на IT Global Meetup #14.
В апреле увеличили ширину канала для каждого сервера с 100 до 200 Мегабит, значительно увеличили лимит трафика для всех тарифов (кроме самого дешёвого) — до 32 ТБ в месяц.
В июле у клиентов появилась возможность автоматически устанавливать Windows Server 2019. В пределах московской локации начали предоставлять бесплатную защиту от DDoS.
Также в июле наша компания появилась на Хабре, дебютировав статьей, как мы написали собственную панель управления хостингом и как это помогло нам сделать качественный скачок в поддержке клиентов.
В августе добавили возможность создавать снимки — резервные копии серверов.
Выкатили публичный API.
Увеличили ширину канала для каждого сервера с 200 до 500 Мегабит.
Участвовали в конференции Chaos Constructions 2019, раздав в качестве мерча плётки с логотипом компании (слоган кампании был “Когда разработчик сверху”) и взорвали телеграм-чаты.
В сентябре мы запустили самый милый и дружелюбный инстаграм IT-компании — о новостях и буднях VDSina начал рассказывать пёсик-разработчик.
www.instagram.com/developer.dog/

В ноябре мы съездили на Highload++, поучаствовали в круглом столе “базы данных в Kubernetes” и одели участников в шапки-акулы.
В декабре выступили на DevOps-митапе в офисе ГазПромНефти с докладом про базы данных в Kubernetes и на конференции DevOpsDays в Москве с докладом про выгорание, который, определенно, стал моим лучшим выступлением за год.
www.youtube.com/watch?v=JqShWWtCL04
Заключение
Как говорил Нассим Талеб, гораздо проще предсказать то, чего мы точно не увидим. Хочу отметить, что всё то новое, что мы увидим в 2020-м берет начало еще в 2019-м, 2018-м и раньше. Я не берусь предсказывать будущее точно, но 2020-й точно не станет годом Linux на десктопе (когда вы в последний раз видели десктоп?) а год Linux на мобильных устройствах мы наблюдаем уже лет десять.
В любом случае надеюсь, что через год мы снова соберемся и обсудим, как все сложилось на самом деле.