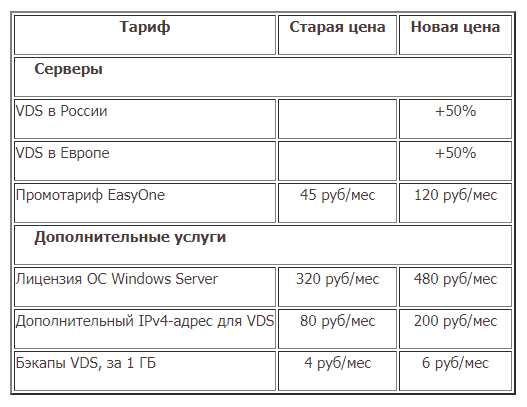
Мы постарались кратко описать путь, который прошла команда Timeweb за 10 лет: от rsync, LVM и DRBD до ZFS. Эта статья будет полезна тем, кто занимается серверной масштабируемой инфраструктурой, планирует делать бэкапы и заботится о бесперебойной работе систем.

Расскажем о:
- rsync (remote synchronization)
- DRBD (Distributed Replicated Block Device)
- инкрементальные бэкапы под DRBD с помощью LVM
- DRBD + ThinLVM
- ZFS (Zettabyte File System)
rsync и бэкапы до н. э.
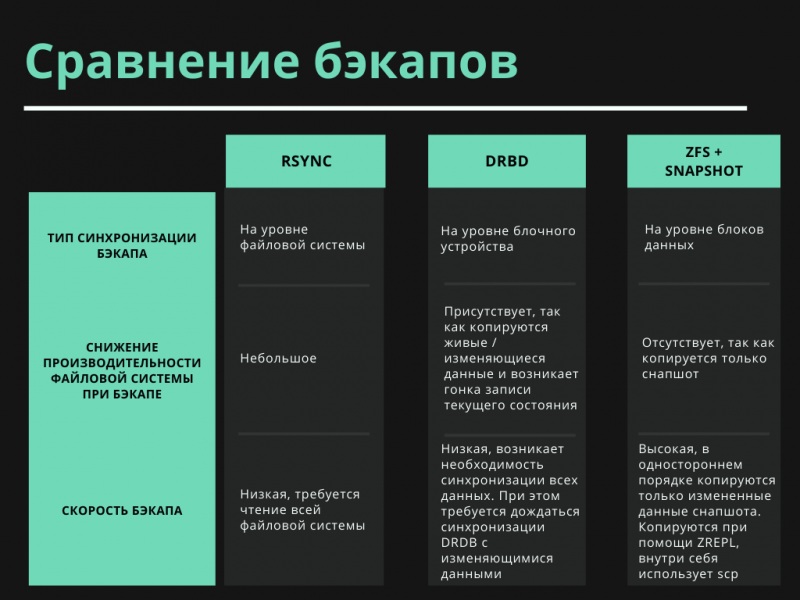
rsync (remote synchronization) — вообще не про бэкапы, строго говоря. Это программа, которая позволяет синхронизировать файлы и каталоги в двух местах с минимизированием трафика. Синхронизация может выполняться и для локальных папок, и для удаленных серверов.
Достаточно часто rsync применяется для резервного копирования. Мы использовали эту утилиту, когда сайты были проще, а клиентов было значительно меньше.
Rsync неплохо справлялась с задачей, но самая большая проблема здесь — скорость. Программа очень медленная, она сильно нагружает систему. А с увеличением данных, начинает работать еще дольше.
Rsync можно применять в качестве технологии бэкапирования, но для совсем небольшого объема данных.
LVM (logical volume manager) — менеджер логических томов
Конечно, нам хотелось делать бэкапы быстрее с наименьшей нагрузкой, поэтому мы решили попробовать LVM. LVM позволяет делать снапшоты, даже используя ext 4. Таким образом, мы могли делать бэкапы при помощи снапшота LVM.
Эта технология использовалась нами недолго. Хоть бэкап и выполнялся быстрее, чем в rsync, но он был всегда полный. А хотелось копировать только изменения, поэтому мы перешли к DRBD.
DRBD
DRBD позволяет синхронизировать данные с одного сервера на другой. При чем синхронизируются только изменения, а не все данные. Это значительно ускоряет процесс!
А на стороне стораджа мы могли использовать LVM и делать снапшоты. Такая система существовала очень долго и существует сейчас на части серверов, которые мы еще не успели перевести на новую систему.
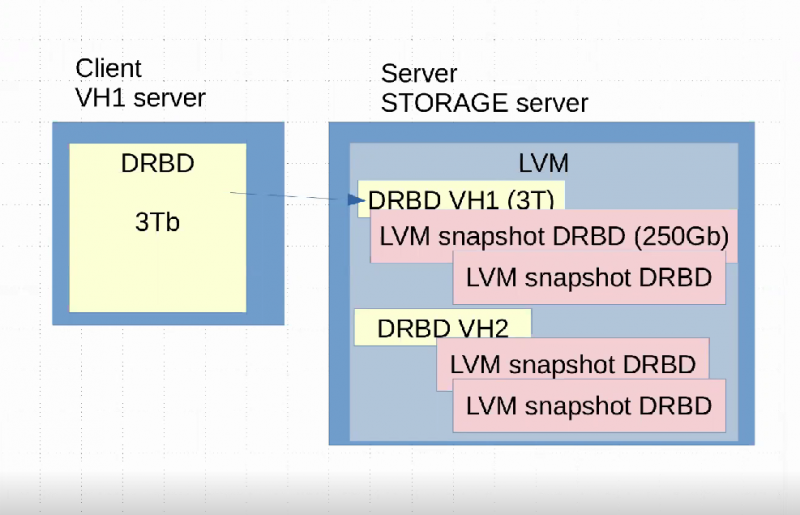
Однако и при таком методе все равно существует недостаток. При синхронизации
DRBD сильно нагружает дисковую подсистему. Это значит, что сервер будет работать медленнее. В результате бэкап мешал работе основных сервисов, то есть сайтов пользователей. Мы даже старались делать бэкапы в ночное время, но они иногда просто не успевали завершиться за ночь. Приходилось маневрировать, чередовать бэкапы. Например, сегодня выполняется одна часть серверов, потом другая. Разносили бэкапы в шахматном порядке.
DRBD, к тому же, сильно зависит от скорости сети и влияет на производительность сервера, с которого и на который ведется бэкап. Необходимо искать новое решение!
Thin LVM
В этот момент бизнес поставил задачу сделать 30-дневные бэкапы, и мы решили переходить на thinLVM. Основную проблему это так и не решило! Мы даже не ожидали, что потребуется настолько высокая производительность файловой системы для поддержания тонких снапшотов. Этот опыт был совсем неудачный, и мы отказались в пользу обычных толстых LVM снапшотов.
ThinLVM, на самом деле, просто не были предназначены для наших задач. Изначально предназначались для небольших ноутбуков и фотоаппаратов, но не для хостинга.
Продолжаем поиски…
Было решено попробовать ZFS.
ZFS
ZFS — неплохая файловая система, которая имеет множество уже встроенных плюшек. Что при ext 4 достигается путем установки на LVM, подключения DRBD-устройства, то при ZFS это есть по умолчанию. Сама файловая система очень надежная. Отдельно стоит отметить функцию Copy-on-write, эта технология позволяет очень бережно обращаться с данными.
ZFS позволяет делать снапшоты, которые можно копировать на сторадж, а также автоматизировать резервное копирование. Не нужно ничего придумывать!
Переход на ZFS был очень осторожным. Сначала мы создали стенд, где просто тестировали несколько месяцев. В частности пытались воспроизвести неполадки с оборудованием, питанием, сетью, переполнением диска. Благодаря тщательному тестированию, смогли найти узкие места.
Больная тема ZFS — переполнение диска. Эту проблему мы смогли решить путем резервирования пустого пространства. Когда диск переполнен, будут предприняты меры по разгрузке сервера и очистке места.
После тестирования мы постепенно начали вводить новые сервера, переводить старые сервера на ZFS. Проблем с бэкапами больше нет! Можно делать 30- или 60-дневные бэкапы, хоть бэкапы каждый час. В любом случае сервер не будет испытывать избыточных нагрузок.
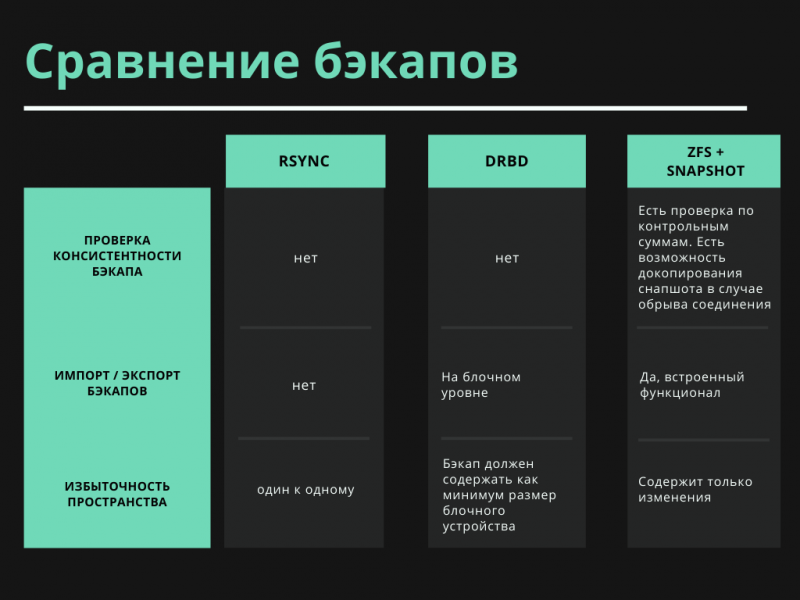
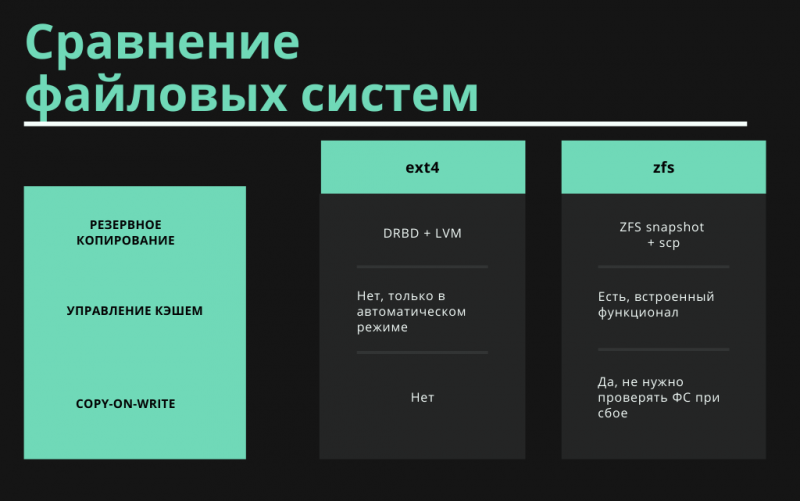
Собрали все данные в таблицах ниже для сравнения бэкапов при использовании различных технологий.

 Что было дальше?
Что было дальше?
В планах обновить ZFS до 2 версии OpenZFS 2.0.0. в 2021 году. Мы готовим переход с использованием всех фишек, которые были анонсированы с выходом релиза в начале декабря.
The Way this is!
Таков путь мы выбрали для себя! Решаете ли вы похожие проблемы? Будем рады, если поделитесь в комментариях опытом! Надеемся, статья оказалась полезна и, если вдруг перед вами так же стоит задача делать бэкапы с помощью встроенных утилит в Linux, наша история поможет подобрать подходящее решение.
timeweb.com/ru/