BILLmanager — это универсальная платформа автоматизации бизнеса по предоставлению и продаже ИТ-услуг. В современном бизнесе важно гибко управлять ресурсами: использовать фиксированные тарифы, учитывать фактическое потребление или комбинировать эти подходы.
В этой статье разберем, как в BILLmanager настраивать тарифы по потреблению ресурсов, какие возможности дает статистика и как платформа помогает провайдерам контролировать сервисы.
Варианты тарифов
В BILLmanager провайдеры могут гибко настраивать тарифы в зависимости от модели предоставления ресурсов:
- Тарифы за выделенные ресурсы. Пользователь получает столько ресурсов, за сколько он заплатил. Расширение возможно, если это предусмотрено тарифом, но требует дополнительных действий со стороны клиента.
- Тарифы за потребленные ресурсы. В эпоху облаков мы привыкли, что ресурсы учитываются по фактическому потреблению, поэтому BILLmanager позволяет настроить тарифы полностью по потреблению или с дополнениями.
- Комбинированные тарифы. Сочетают фиксированную стоимость и оплату за фактическое потребление. BILLmanager ежедневно собирает статистику из интегрированных продуктов, на основе которой формируется конечная стоимость услуги — с учетом использования платных опций.
В BILLmanager провайдер может использовать любую оптимальную для него схему тарификации. Далее рассмотрим настройку тарифных планов с дополнительными опциями (аддонами) по статистике и по модели Pay-as-you-go (по мере потребления).
Тарифы с дополнениями по потреблению
Такие тарифы позволяют ограничить дополнения по количеству или объему ресурсов. Например, какое количество IP-адресов будет входить в тариф, а за какие платить дополнительно. Для настройки дополнения нужно:
- Выделить необходимый тариф → выбрать «Конфиг».
- Создать дополнение «Тип учета: На основе статистики».
- В разделе «Ограничения тарифа» в пункте «Включено в тариф» указать тот объем, который будет входить в тариф.
- В разделе «Цена за превышение» указать стоимость дополнений при превышении. Готово!
Pay-as-you-go (PAYG)
Тариф Pay-as-you-go (PAYG) предполагает оплату по мере потребления. Для ее настройки все дополнения должны учитываться по статистике. Как настроить:
- Выделить необходимый тариф → выбрать «Конфиг».
- Создать дополнение «Тип учета: На основе статистики».
- В разделе «Ограничения тарифа» в пункте «Включено в тариф» указать значение «0».
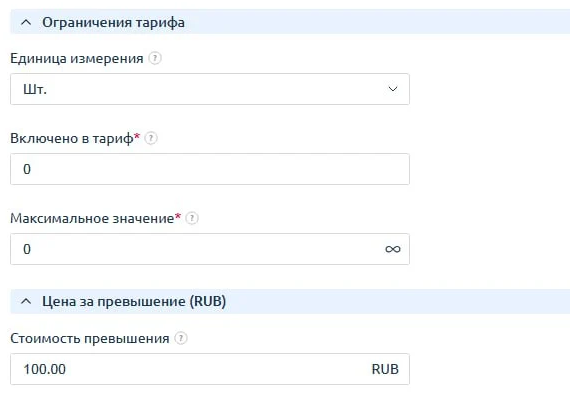
В разделе «Цена за превышение» указать стоимость дополнений при превышении.
Гибкие опции учета в BILLmanager
Тип учета по статистике предоставляет гибкие настройки для управления потреблением ресурсов:
Считать превышение. Выберите период, за который система считает превышение.
- за календарный месяц — списания происходят при превышении месячного лимита. Статистика обнуляется первого числа каждого месяца;
- за день — списание случится, если суммарное использование ресурса за день превысит включенное в тариф значение.
Если параметров несколько. Выберите метод учета ресурса, когда он определяется несколькими параметрами:
- суммировать — учитывается использование ресурса по каждому из параметров (сумма параметров);
- наибольшее значение — учитывается использование ресурса по параметру, который чаще использовался.
Цена указана. Выберите, за какую единицу ресурса указана стоимость в поле «Стоимость превышения»:
- за каждую единицу превышения;
- за каждую единицу превышения в месяц.
- Учитывать на остановленной услуге — позволяет списывать средства за выделенный ресурс, когда предоставление услуги остановлена.
- Оплата по факту использования — опция позволяет списывать средства за перерасход ресурса, даже если на балансе клиента недостаточно средств. Работает независимо от продукта, если выбрать тип учета «На основе статистики».
- Суммировать акты выполненных работ — позволяет суммировать значения ресурса за весь период.
- Ограничение скорости при перерасходе — доступна для дополнения «Трафик».
Работа с перерасходами
В глобальных настройках провайдер может определить политику работы с перерасходами и установить, что будет происходить с услугами при превышениях. Доступны уведомления о перерасходе: при каждом списании по статистике или при списании в долг.
Что делать, если на лицевом счете не хватает денежных средств:
- не выполнять действия — клиент получит уведомление о приближении к допустимому лимиту, а сервис продолжает работать;
- производить списание — средства спишутся в долг. Если клиент не погасит его первого числа следующего месяца, он получит счет;
- останавливать услугу — предоставление услуги с превышенным лимитом остановится.
BILLmanager обеспечивает полную прозрачность для клиента, чтобы он всегда понимал, за какие услуги заплатил и как формируется перерасчет.
Отображение статистики
Для работы с данными о тарифах и дополнениях в BILLmanager реализованы инструменты отображения статистики. Работа с данными статистики ведется в двух режимах:
- потребление по дням;
- перерасход по месяцам — новый режим для ретроспективного просмотра данных за выбранный отчетный период по каждому компоненту услуги.
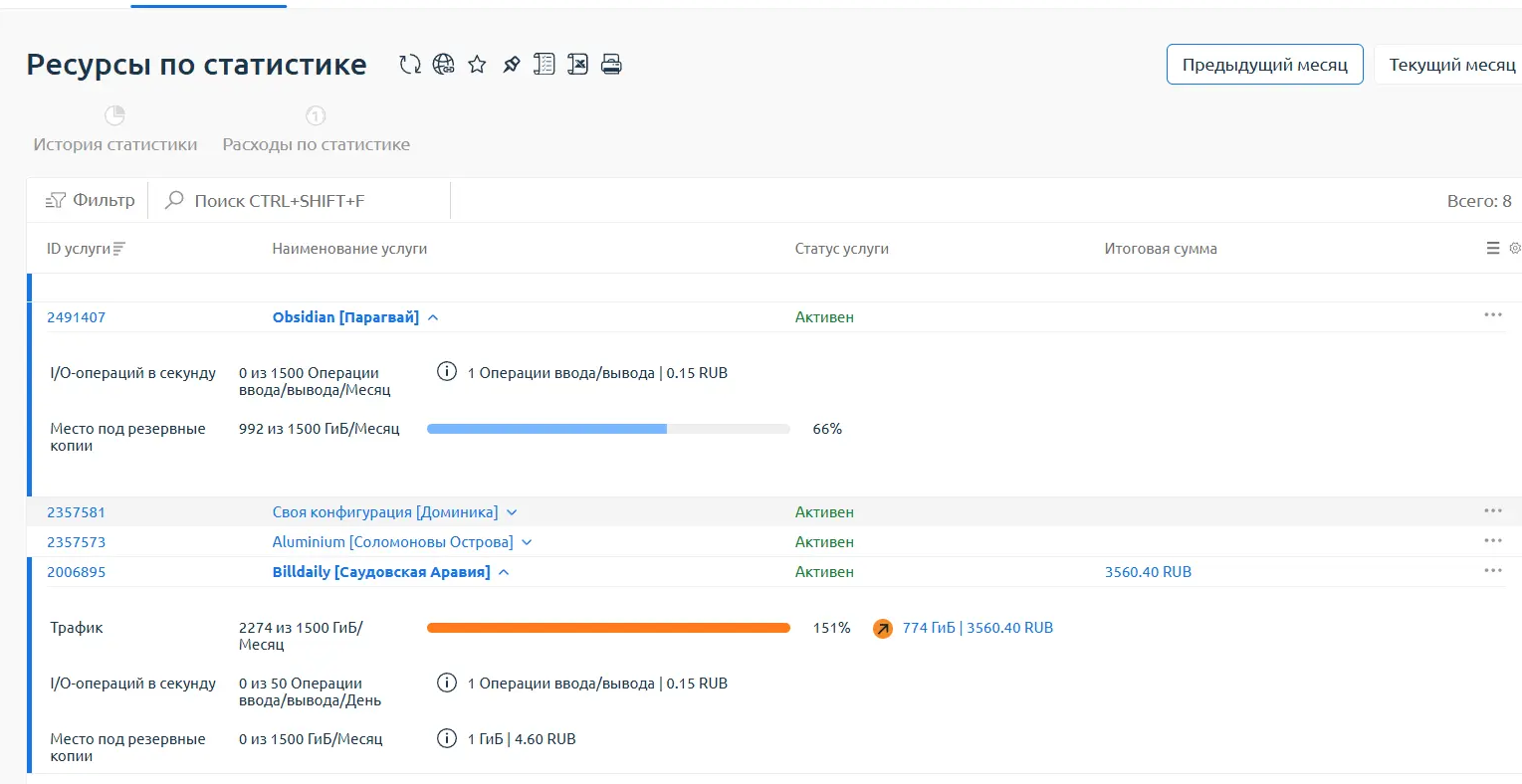
Вся информация отображается в виде графиков, где указано пороговое значение. Также пользователям доступны блоки, где можно контролировать данные об общем количестве использованных ресурсов, установленный лимит и перерасход по услуге. В блоке справа представлена информация о стоимости перерасхода в периоде.
Кроме этого, в личном кабинете в разделе «Ресурсы по статистике» клиенты могут отследить услуги, к которым подключена опция статистики, а также проанализировать использование подключенных сервисов. Услуги попадают в этот раздел при приближении к лимиту или после его превышения. В конце месяца список очищается.
 Интеграция с VMmanager
Интеграция с VMmanager
Интеграция BILLmanager и VMmanager позволяет провайдерам предоставлять виртуальные машины в гибкой и настраиваемой тарификации. В конце 2025 года мы расширили список собираемых данных из VMmanager, добавив метрики CPU, RAM, СХД и операции ввода-вывода. Также в рамках интеграции доступен сбор данных по трафику и возможность ограничить его скорость при превышении лимита.
Это позволяет предоставлять тарифы с дополнениями по статистике и виртуальные машины по модели Pay-as-you-go — с оплатой за фактическое потребление ресурсов
Итоги
Продукт дает провайдеру возможность реализовать практически любой задуманный вариант предоставления услуг — за счет гибкой настройки моделей тарификации и доступных интеграций.
Команда BILLmanager продолжит развивать возможности платформы и интеграции с VMmanager, чтобы предоставить провайдерам еще больше возможностей для оптимальной работы. Следите за обновлениями!
www.ispsystem.ru