Мы хотим поделиться с вами подробностями развития платформы Yandex.Cloud в 2020 году и рассказать о наших финансовых показателях, а также об особенностях спроса и потребления облачных сервисов нашей платформы.

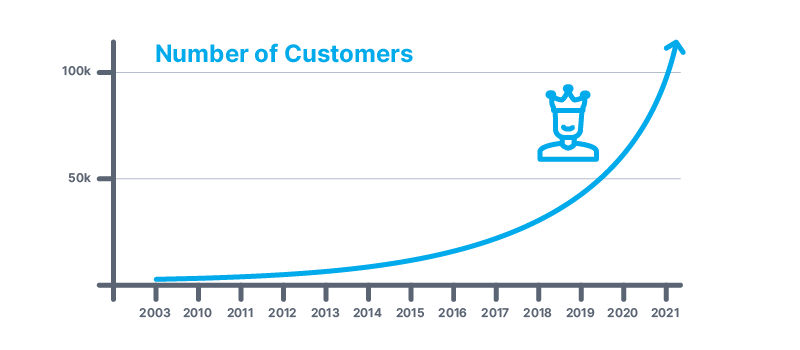
В 2020 году выручка платформы Yandex.Cloud увеличилась в 4,5 раза и достигла 1 миллиарда рублей. Количество коммерческих клиентов Yandex.Cloud увеличилось в 2020 году по сравнению с 2019 годом в 1,4 раза и составило 9 700, а средний чек одного клиента увеличился за этот период в 3 раза.
Мы выделяем несколько главных причин такого роста. Во-первых, российские и международные компании стали более активно создавать и развивать собственные цифровые продукты. Во-вторых, многие отрасли, например ритейл и e-commerce, столкнулись с резким ростом нагрузки на онлайн-сервисы из-за пандемии, и компании искали в облаках возможность быстрого расширения ИТ-инфраструктуры, повышения производительности и отказоустойчивости.
Yandex.Cloud 2020: крупные клиенты увеличили объемы потребления
Крупными потребителями облачных сервисов Yandex.Cloud стали 270 клиентов. К ним относятся компании, занимающие лидирующие позиции в своих отраслях по капитализации, доле рынка и темпам роста. Это такие компании, как Леруа Мерлен, Ozon, М.Видео, ВТБ, SkyEng, Национальный исследовательский университет «Высшая школа экономики» и другие. Такие клиенты обрабатывают большие объемы данных, активно развивают корпоративные и отраслевые цифровые платформы для управления внутренними процессами бизнеса, запуска и поддержки новых приложений и сервисов.
В 2020 году количество крупных клиентов платформы Yandex.Cloud увеличилось более чем в 2 раза, а объем потребления ими сервисов Yandex.Cloud вырос почти в 5 раз. Доля крупных клиентов в общей выручке Yandex.Cloud составила 48%. Этот показатель вырос по сравнению с 2019 годом на 4 процентных пункта.
Стоит отметить, что доля компаний группы Яндекса в структуре выручки платформы Yandex.Cloud в 2020 году составила 4%. При расчете показателя учитывается только потребление Yandex.Cloud сервисами ГК Яндекс по общим рыночным условиям. Объем потребления ресурсов внутренней облачной платформы, локализованной под задачи компаний и отдельных сервисов ГК Яндекс, в структуре выручки Yandex.Cloud не учитывается.
Облака — не отдельные технологии, а платформа для роста бизнеса
Мы считаем, что в ближайшие несколько лет бизнес массово будет использовать облака как целостные платформы, на которых по запросу можно получить все необходимые сервисы для решения задач по развитию бизнеса.
На опыте Yandex.Cloud мы выделили 4 основных сценария потребления облачных сервисов компаниями:
- перенос из собственной инфраструктуры на облачную корпоративных приложений и сервисов;
- развитие единой среды разработки, тестирования и запуска новых бизнес-приложений (цифровых продуктов);
- создание корпоративной платформы данных для хранения, обработки и анализа данных;
- применение сервисов на базе искусственного интеллекта и инструментов машинного обучения.
В свою очередь, сервисы платформы, которые наиболее активно участвуют в достижении этих сценариев, мы разделили на 4 основные группы и оценили, каким спросом они пользовались в 2020 году.
Группа № 1: «Базовая инфраструктура и сеть». Вклад в выручку Yandex.Cloud в 2020 году — 60%. В группу входят виртуальные машины, сетевые диски, инструменты управления виртуальными сетями. Это наиболее востребованная группа сервисов, на нее в 2020 году пришлось 60% выручки платформы Yandex.Cloud. Активные потребители сервисов этой группы — интернет-магазин Ozon.ru, DIY-ритейлер Leroy Merlin, разработчик мобильных игр Axlebolt.
Группа № 2: «Машинное обучение». Вклад в выручку Yandex.Cloud в 2020 году — 14%. В группу входят сервисы на базе уникальных технологий Яндекса в области машинного обучения и искусственного интеллекта. Сервисы машинного обучения активно используют такие компании, как Signal AI, Badoo, разработчик и интегратор голосовых сервисов АТС (разрабатывает сервисы для Альфа-Банка, Мегафона, ДИТ Москвы, Министерства здравоохранения МО). Наибольший рост — в 9 раз — показал сервис синтеза и распознавания речи Yandex SpeechKit. Это также подтверждает интерес партнеров, за 2020 год количество компаний, специализирующихся на разработке и внедрении голосовых сервисов выросло до 30. Сервис машинного перевода Yandex Translate принес 32% выручки направления, в том числе за счет спроса со стороны зарубежных клиентов, которых привлекает соотношение цены и качества перевода многих языковых пар, превосходящее такое соотношение в аналогичных сервисах.
Группа № 3 «Платформа данных». Вклад в выручку Yandex.Cloud — 12%. Экосистема облачных сервисов для полного цикла работы с данными. Самыми востребованными стали системы управления базами данных, предоставляемые на платформе как сервис. На первом месте по популярности — PostgreSQL, также в тройку входят ClickHouse и MySQL. Количество компаний-пользователей MDB в 2020 году достигло 1 350. Рост группы «Платформа данных» в 2020 году — в 8 раз. У нас хранят свои данные ВТБ, М.Видео и Декатлон.
Группа № 4 «Автоматизированное управление контейнерами». Вклад группы в выручку Yandex.Cloud — 7%. Основной сервис Managed Service for Kubernetes — для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями. Коммерческими пользователями сервиса Managed Kubernetes в 2020 году стали 260 клиентов Yandex.Cloud. Общий рост группы в 2020 году — в 18 раз. Активные потребители сервисов группы: компания ПИК, «Альфа-Страхование», Инвестиционная группа «Севергрупп».
Еще 7% выручки Yandex.Cloud в 2020 году относятся к маркетплейсу и платной поддержке.
Что дальше: больше возможностей клиентам Yandex.Cloud в 2021 году
В 2021 году спрос компаний на облачные технологии будет увеличиваться. Мы планируем, что выручка от потребления сервисов нашей платформы вырастет в 2,6 раза. Мы прогнозируем увеличение спроса на облачные мощности, которыми крупные промышленные компании и государственные организации будут дополнять собственную инфраструктуру. Также в 2021 году мы планируем сделать акцент на развитии экосистемных сервисов: DataSphere, DataLens, бессерверных вычислениях.
Приоритетными остаются развитие безопасность и надежность платформы Yandex.Cloud, в том числе увеличение количества дополнительных сервисов от ведущих разработчиков в нашем маркетплейсе.