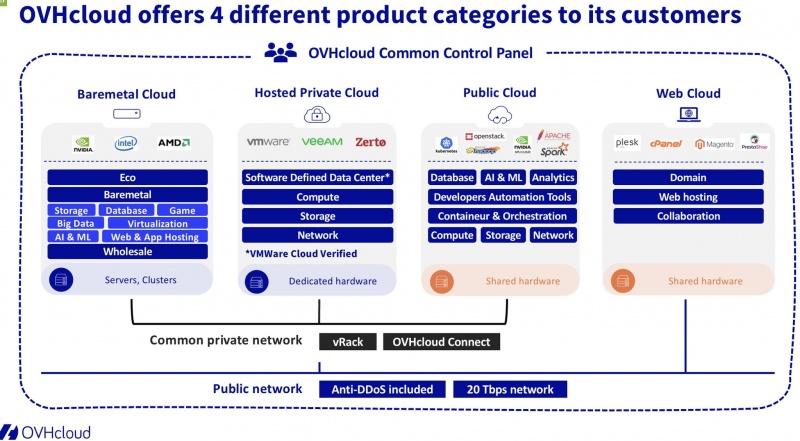
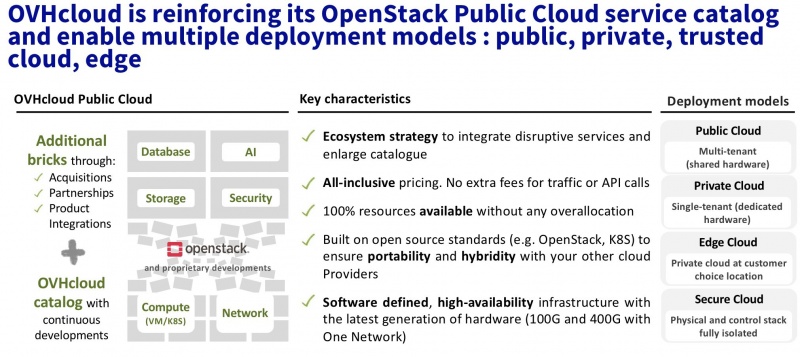
Представляем вам новую услугу обеспечения непрерывной работы бизнеса для владельцев собственной инфраструктуры.
Для кого
Если у вас уже есть сервер, размещенный на вашей площадке или в каком-то ЦОДе, но вы хотите минимизировать риски от его выхода из строя, то эта услуга вам пригодится.
В рамках этой услуги вы можете получить подменный сервер на срок ремонта вашего оборудования при выходе его из строя. Подменный сервер может быть предоставлен как в нашем ЦОДе, так и для размещения в вашей стойке.
Как это работает
Вы заключаете с нами договор на предоставление подменного сервера. Каждый месяц вы оплачиваете «членский» взнос за резервацию. В том случае, когда ваш сервер выходит из строя, мы предоставляем вам подменный сервер на срок ремонта или делаем компенсацию с оплатой штрафных санкций, если не можем предоставить сервер.
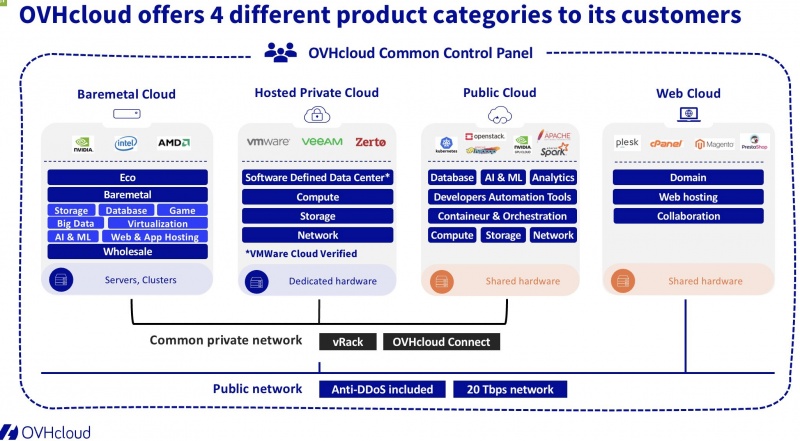
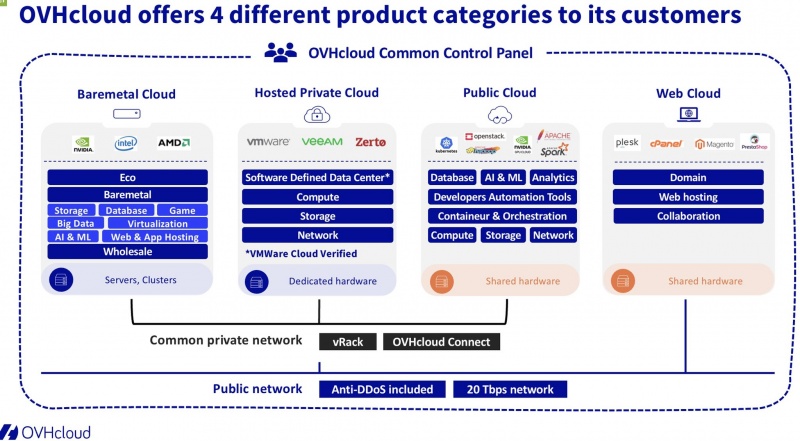
Какие есть серверы
В рамках услуги мы предоставляем 4 конфигурации:
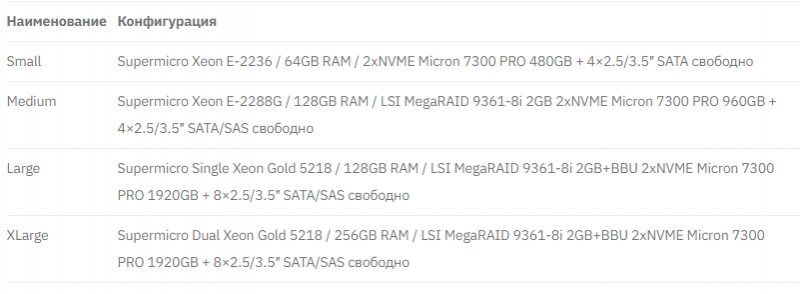
В таблице выше отображены платформы, которые предлагаются для резервирования вашего оборудования на время отказа или ремонта.
В платформы можно доустановить ваши комплектующие перед выделением, если в этом есть потребность. Для этого, вы привозите их нашим инженерам для совместного монтажа в сервер, после чего он выделяется предоставляется.
Общие условия предоставления
Мы можем предоставить больший сервер при отсутствии того, который клиент выбрал в рамках услуги, например, XLarge вместо Large.
После того, как оборудование было предоставлено клиенту, следующее предоставление возможно не ранее, чем через 1 календарный месяц после возврата оборудования.
Запрос на предоставление, полученный до 17:00, обслуживается в тот же день, запрос, полученный после 17:00, обслуживается, начиная с 09:00 следующего дня.
Условия предоставления сервера для монтажа на площадку клиента (только для Томска)
Наличие оборудованного серверного помещения с кондиционированием и источником бесперебойного питания.
Запрещается работа с внутренним аппаратным содержимым сервера без участия сотрудников НетПоинт, сервер опечатывается перед предоставлением.
Монтаж сервера на площадке клиента в присутствии нашего специалиста.
Клиент подписывает акт материальной ответственности за предоставленное оборудование.
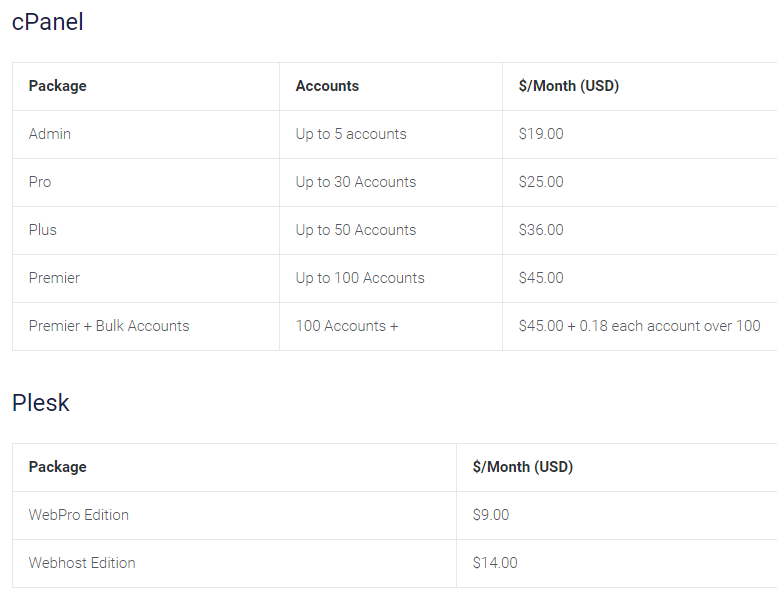
Тарифы
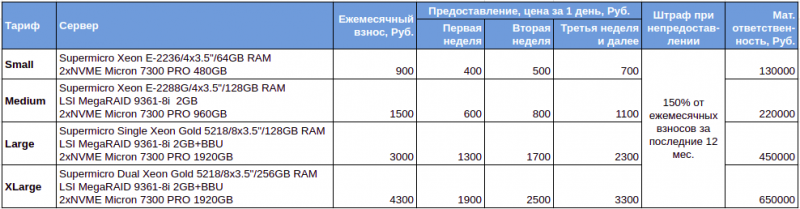
Рассмотрим, как это работает на примере контракта на предоставление резервного сервера Small. После заключения контракта, вы ежемесячно оплачиваете 900 рублей. В момент возникновения аварийной ситуации мы предоставляем вам подменный сервер.
Если мы не смогли предоставить сервер, то выплачиваем вам сумму ваших взносов по данному договору за прошедшие 12 месяцев, умноженную на 1.5, например, если вы платили 12 месяцев по 900 рублей в месяц, то в случае невозможности предоставления мы вам вернем 900 x 12 x 1.5 = 16200 рублей.
Если сервер вам необходим на вашей площадке, то вы привозите дополнительные комплектующие для монтажа, совместно с нашим инженером устанавливаете их в сервер, сервер опечатывается. После этого, вы совместно с нашим инженером едете устанавливать сервер.
После установки сервера подписывается акт приема-передачи и приема материальной ответственности.
Далее, за каждый день использования подменного сервера Small вы оплачиваете стоимость, согласно ценам, указанным в таблице:
- в течение первой недели использования — 400 руб. в день;
- в течение второй недели использования — 500 руб. в день;
- в течение третьей и последующей недели использования — 700 руб. в день;
После восстановления работоспособности вашего оборудования осуществляется обратная процедура — демонтаж, подписание актов приема передачи, возврат оборудования.
В следующий раз вы сможете воспользоваться сервером в рамках данного контракта не ранее, чем через 1 месяц.
Начать пользоваться
Чтобы воспользоваться услугой, пожалуйста обратитесь через биллинговую систему, или отправьте сообщение по электронной почте на support@netpoint-dc.com. Если вы работаете с конкретным сотрудником компании, можно обратиться непосредственно к нему.