Ваш бизнес готов к высоким нагрузкам!
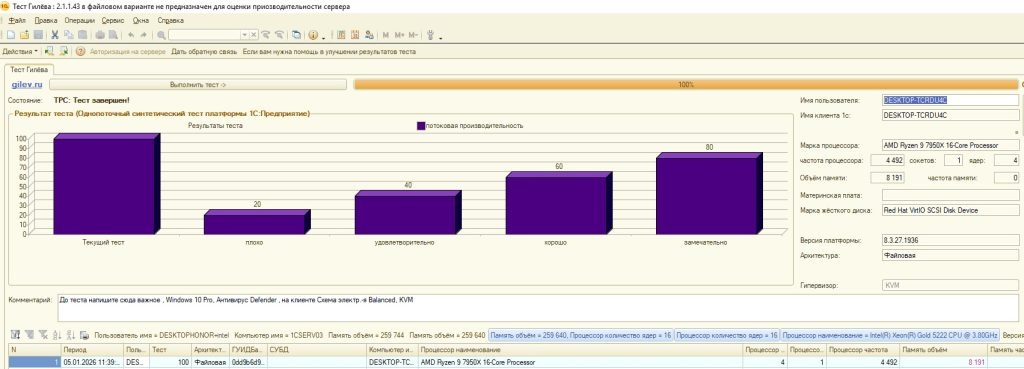
Провели специализированный нагрузочный тест Гилева для системы 1С на наших высокопроизводительных серверах. Результат отличный — 100 единиц производительности, гарантирующих стабильную работу даже при пиковых нагрузках!
Что такое тест Гилева?
- Тест измеряет производительность серверов при обработке больших объемов транзакций в среде 1С. Тест Гилева — инструмент для диагностики узких мест в инфраструктуре 1С, позволяющий понять, где именно система не справляется: с нагрузкой на процессор, диски или сеть.
Получив результат 100 единиц, мы обеспечиваем бесперебойную работу вашего предприятия независимо от объема операций.
Сейчас действует специальное предложение
- Вы можете лично убедиться в надежности нашего тарифа! Возьмите его в тест-драйв и проверьте работоспособность своей системы 1С самостоятельно по ДИКО ВМЕНЯЕМОЙ ЦЕНЕ с отличной скидкой 50% до 12 января 2026 года!
- Надежность и стабильность вашей информационной инфраструктуры гарантированы нашим оборудованием и технологиями.
Узнайте больше деталей и попробуйте нашу услугу уже сегодня!
P.S. Тестирование проводилось на рабочем хостинге с функционирующими другими виртуальными серверами. Использовался тариф Hi-CPU 3+ с операционной системой Windows 10, версия 1С — 8.3.27.1936, тест Гилева версии 2.1.1.43. Во время тестирования была отключена защита от вирусов и угроз.
 billing.elenahost.ru
elenahost.ru
billing.elenahost.ru
elenahost.ru

Наши годовые контракты стали доступнее по цене.
В течение ограниченного времени мы предлагаем скидку 25% на годовые планы VPS и VDS, а также скидку 15% на годовые контракты на выделенные серверы. Подпишитесь на двенадцать месяцев и заплатите меньше за все.
Почему годовая цена подходит именно вам
Скидка 25% на 12-месячный контракт VPS или VDS означает, что вы фактически платите за девять месяцев и получаете три бесплатно. На выделенном сервере скидка 15% позволит вам сэкономить почти два месяца на хостинге.
Кроме того, при оплате за год вперед ваш бюджет на хостинг остается фиксированным. Никаких неожиданностей.
Подходит любой новый тарифный план. Выберите характеристики, укажите оплату за 12 месяцев и сэкономьте.
contabo.com/en/vps/
Не забудьте: вы можете добавить бесплатную установку n8n, Nextcloud, WireGuard или GitLab CE в один клик на любой VPS или VDS. Развертывание займет менее 30 минут.
Предложение скоро закончится. Воспользуйтесь скидкой и приобретите годовой абонемент.
Ваша команда Contabo

Мы в Selectel не боимся мечтать масштабно — для этого у нас есть надежная инфраструктура и надежная команда. Поэтому предлагаем тебе загадать самые смелые желания на 2026
Напиши себе послание в будущее: куда хочешь продвинуться в карьере, чего ждешь, где тебе важно оказаться в конце 2026? Специально для этого мы выделили целый новогодний сервер. Сохраним на нем твое письмо и отправим обратно ровно через год.
careers.selectel.ru/novogodnyserver
Компания TSMC уведомила клиентов о планах повышения цен на передовые технологические процессы производства 3-нм и более тонких чипов в течение следующих четырех лет, с 2026 по 2029 год, в связи с ростом производственных затрат, сообщают СМИ. Ожидается, что в 2026 году цены вырастут на 3-10%. В сообщении говорится, что повышение цен никак не повлияло на заказы, поскольку «гонка вооружений в области искусственного интеллекта» продолжает стимулировать спрос.
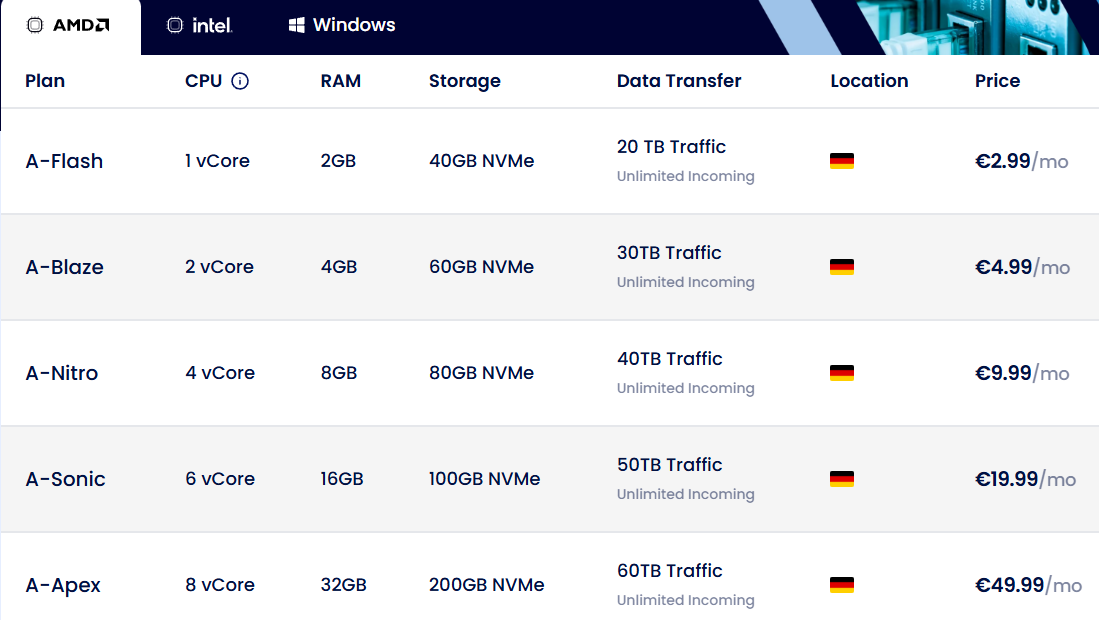
 www.dasabo.com/servers
www.dasabo.com/servers
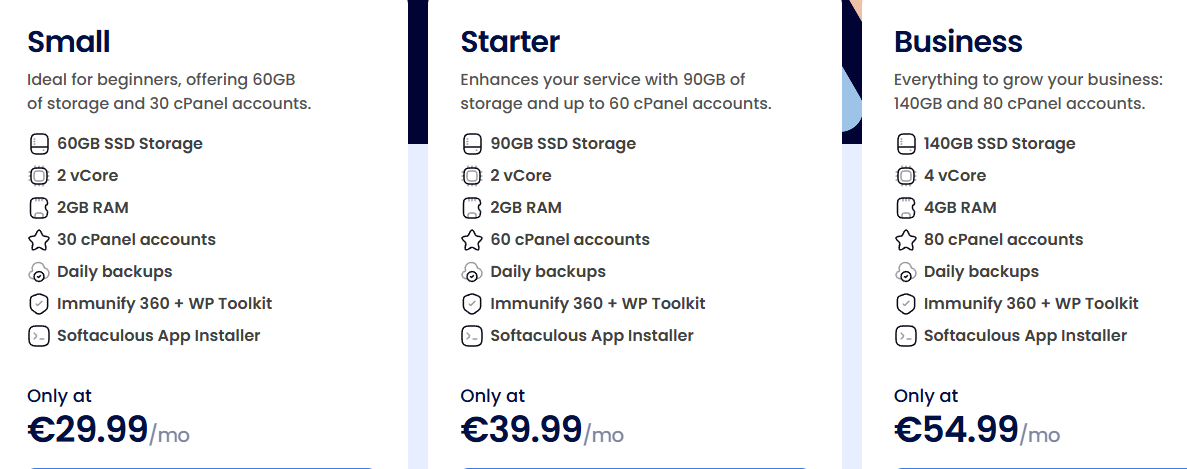
 www.dasabo.com/reseller
www.dasabo.com/reseller
Мы рады сообщить о важной вехе на пути развития компании Dasabo.
Компания Dasabo теперь официально аккредитована RIPE NCC как локальный интернет-регистратор (LIR).
Это достижение знаменует собой значительный шаг вперед для нашей компании и отражает наше неизменное стремление к созданию надежной, независимой и перспективной инфраструктуры. Став лицензированным провайдером услуг связи (LIR), мы можем напрямую управлять IP-ресурсами, оптимизировать работу сети и проектировать сервисы с большей гибкостью, прозрачностью и контролем.
Для наших пользователей это означает:
- Более прочная и надежная сетевая основа
- Более высокая автономия в управлении интеллектуальной собственностью.
- Улучшена масштабируемость для текущих и будущих сервисов.
- Четкое долгосрочное видение, ориентированное на качество и инновации.
Этот рубеж — только начало. Используя наш новый статус LIR, мы уже работаем над новыми услугами и решениями, которые расширят наше предложение и позволят лучше обслуживать профессионалов, предприятия и пользователей, ориентированных на инфраструктуру.
Благодарим вас за вашу неизменную поддержку и доверие.
Следите за новостями — вас ждут захватывающие события.
С уважением,
команда Dasabo

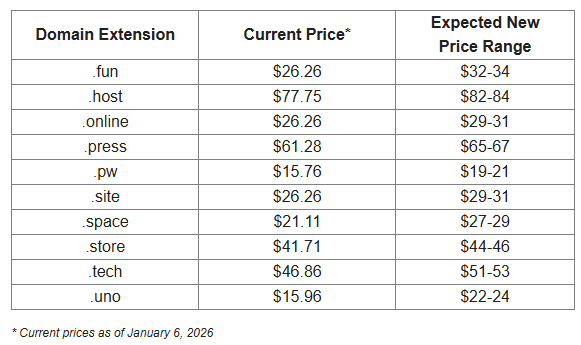
Здравствуйте! Извините, что мы на секунду заполним ваш почтовый ящик, но у нас есть для вас важная новость, касающаяся одного или нескольких ваших доменов в Porkbun. Регистратор Radix повышает цены на некоторые доменные расширения 15 января 2026 года в 16:00 UTC.
Обратите внимание, что цены на ваши домены .com, .org и .net в настоящее время НЕ повышаются.
Radix Registry повышает цены в масштабах всей отрасли, поэтому это изменение затронет всех регистраторов, предлагающих эти домены, а не только нас. Повышение цен распространяется на регистрацию, продление и передачу следующих доменных расширений:

Мы пишем, чтобы сообщить вам о предстоящем обновлении цен, которое затронет один или несколько доменов в вашем портфеле.
В соответствии с инициированной регистратором корректировкой цен, с 1 февраля будут обновлены цены на регистрацию и продление следующих доменных расширений:

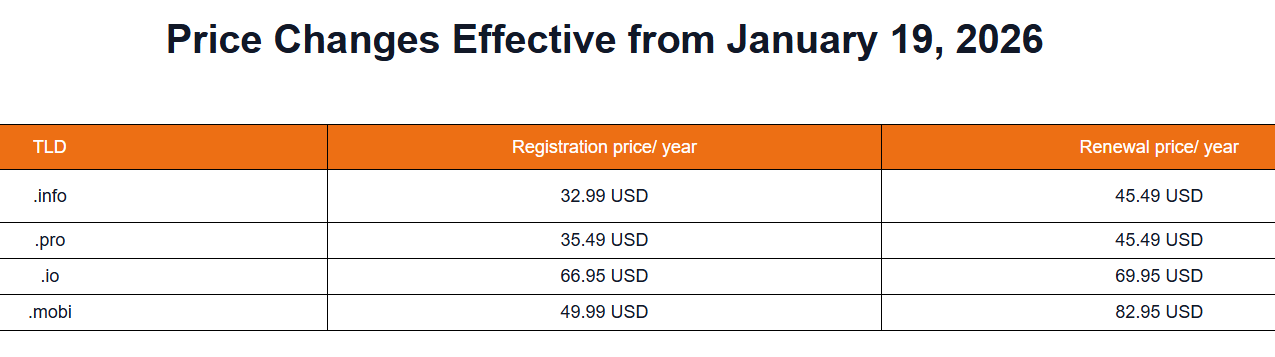

Мы сотрудничаем со многими регистраторами, чтобы предложить вам широкий выбор доменов верхнего уровня, но иногда их цены растут, а это значит, что нам тоже приходится повышать цены.
15 января 2026 года регистратор доменов .fun, .host, .online и других начнет повсеместное повышение цен. Эти изменения затронут стоимость продления, повторной активации, регистрации и переноса для отдельных доменов верхнего уровня (TLD).
Ниже вы можете ознакомиться с новыми ценами на все затронутые домены:

