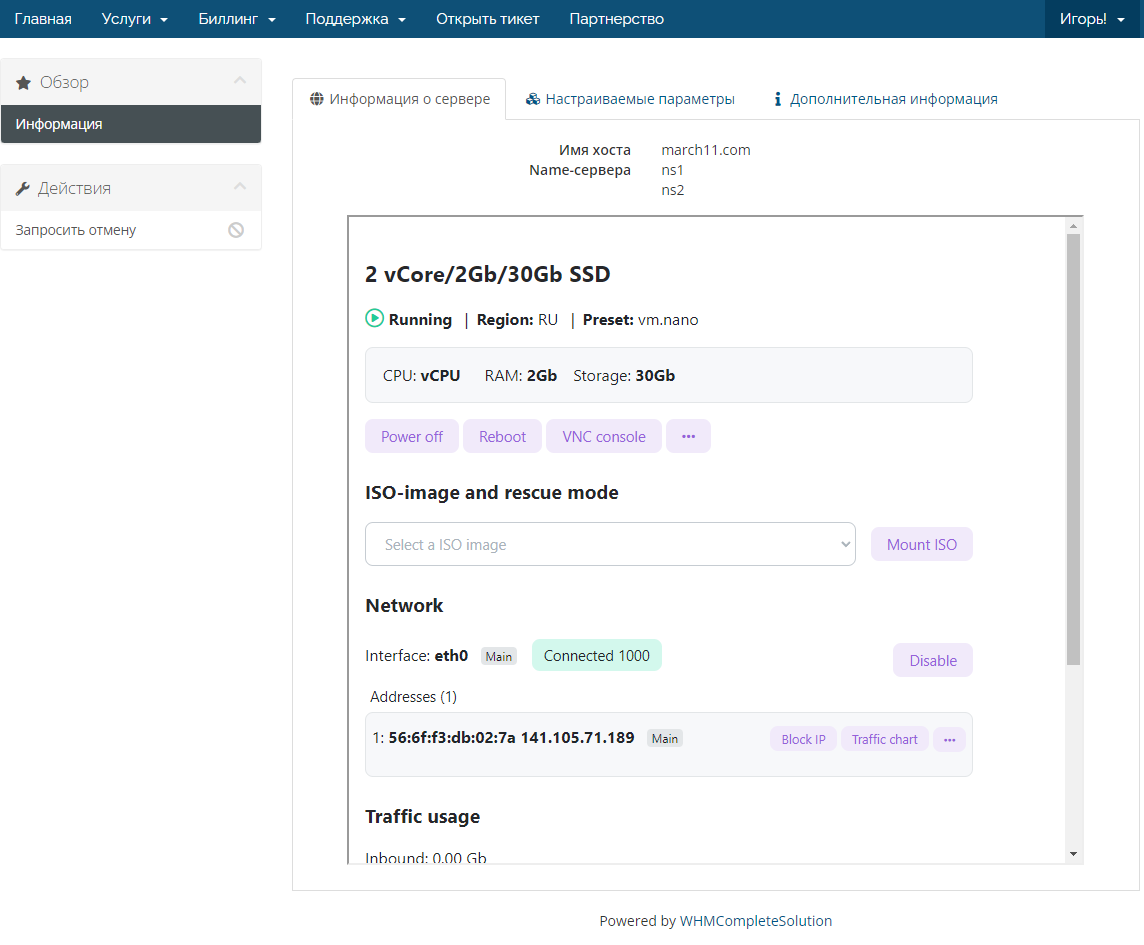
26.02.2024, О внесении компании 3data в санкционные списки США
26.02.2024, О внесении компании 3data в санкционные списки США
23 февраля 2024 г. на сайте министерства финансов США был обнародован санкционный список физических и юридических лиц, в котором упомянута компания ООО «3Дата» (ИНН 7702822710, ОГРН 1137746838800).
Учитывая современные тенденции и западную санкционную политику последних лет, мы были готовы к такому внешнеполитическому сценарию и информируем всех наших партнеров, действующих и будущих клиентов, контрагентов, что данное обстоятельство никак не скажется на работе компании, беспрерывном функционировании всех наших дата-центров и планах развития: компания 3data продолжает работать и оказывать все услуги в штатном режиме.
12.03.2024, Рассказали об интегрированном в деловой центр ЦОДе 3data на мероприятии девелопера Coldy
В конце февраля состоялся закрытый бизнес-ланч для брокеров и девелоперов в Инновационном Центре Сколково, организованный компанией Coldy. Илья Хала, генеральный директор сети дата-центров 3data, стал одним из спикеров мероприятия, выступив с презентацией на тему «Цифровая недвижимость: дата-центр в деловом центре «TALLER».
В рамках бизнес-ланча сотрудниками Coldy были представлены БЦ NICE TOWER и ДЦ TALLER, отличительной особенностью которого является наличие интегрированного дата-центра 3data «Ж8». В своем выступлении Илья Хала рассказал о преимуществах ЦОДа на объекте коммерческой недвижимости, плюсах аренды цифрового офиса, а также поделился техническими характеристиками центра обработки данных.
«ДЦ TALLER стал первым офисным центром в Москве с интегрированным в цифровую среду ЦОДом. Это дает возможность коммерческому объекту получить статус «Цифровой недвижимости» и сертификат Cloud Ready Building (CRB) на соответствие передовым международным требованиям по доступности цифровых сервисов. Таким образом повышается капитализация объекта и его ликвидность, а также выделяет его среди конкурентов, что позволяет привлечь лучших резидентов», — поделился Илья Хала.
Для арендаторов Илья выделил такие преимущества, как возможность задействовать полный спектр услуг вычислительной инфраструктуры (доступ ко всем современным облачным сервисам, размещение собственного оборудования, аренда серверных стоек и др.) и повышение надежности ИТ и телеком сервисов за счет максимальной приближенности дата-центра к заказчику. Также благодаря близкому расположению ЦОДа сокращается время, которое ИТ-специалисты компании тратят на дорогу. В особенности это важно, когда случаются инциденты, и за каждую минуту простоя бизнес может нести финансовые потери.
Дата-центр «Ж8» на Павелецкой с проектной емкостью в 140 стойко-мест с ИТ-нагрузкой от 5,5 кВт будет отвечать всем необходимым требованиям к надежности и безопасности на уровне Tier 3. ЦОД оснащен прямым подключением к международным и городским магистральным линиям связи, имеет доступ ко всем современным облачным сервисам, а единый ситуационный центр 3data будет осуществлять комплексный мониторинг работы объекта.
20.03.2024, 3 апреля состоится презентация книги Марата Мурадяна «Отцы русского маркетинга» в Московском доме книги
3data приглашает Вас на презентацию книги Марата Мурадяна «Отцы русского маркетинга». Мероприятие состоится 3 апреля с 19:00 до 21:00 в Московском доме книги на Новом Арбате, арт-пространство «Книгомания», 2-ой этаж.
27.03.2024, Обсудили развитие облачного рынка и его перспективы на конференции Cloud & Connectivity
21 марта состоялся 13-ый международный форум Cloud & Connectivity, организатором которого традиционно стало издательство «ИКС-Медиа». Генеральный директор сети дата-центров 3data Илья Хала принял участие в пленарной дискуссии на тему «Облака 2023–2024: итоги и перспективы». Также в диалог вступили представители компаний «Клауд Солюшенс», Ростелеком – ЦОД, МТС, Selectel и Евгений Филатов, заместитель министра Минцифры России.
Во время обсуждения эксперты пришли к единому мнению, что несмотря на все барьеры и трудности, облачный рынок продолжает развиваться. Появление качественных отечественных решений, а также поддержка со стороны государства поспособствовали данному росту.
11.04.2024, Провели презентацию книги «Отцы русского маркетинга» в Московском доме книги
В Московском доме книги на Новом Арбате состоялась презентация книги Марата Мурадяна «Отцы русского маркетинга», посвященной истории развития отечественного рекламного дела и маркетинга. Сеть дата-центров 3data выступила издателем книги.
02.05.2024, Повысили компетенции в сфере обслуживания ИБП Kehua Tech
3data обладает одной из самых квалифицированных технических команд на рынке ЦОД, сотрудники компании регулярно проходят различные обучающие курсы по развитию собственных компетенций для работы с любым оборудованием. Тренинг по эксплуатации источника бесперебойного питания (ИБП) производителя Kehua Tech послужил очередной точкой роста.
Обучение проводилось сертифицированными специалистами компании «Абсолютные Технологии», официальным дистрибьютором Kehua Tech, и охватило как теоретические, так и практические аспекты эксплуатации и обслуживания ИБП. В рамках тренинга сотрудникам технической службу 3data рассказали о конструкции ИБП, системе мониторинга, снятии характеристик работающего ИБП, особенностях технического обслуживания.
28.05.2024, Обсудили текущую ситуацию на рынке инженерных систем ЦОД на конференции Data Center Design & Engineering
В конце мая сеть дата-центров 3data приняла участие в 11-ой конференции и выставке Data Center Design & Engineering, организатором которой традиционно выступило издательство «ИКС-Медиа». На площадке Holiday Inn Moscow Sokolniki эксперты в области инфраструктуры и эксплуатации ЦОД обсудили текущую ситуацию и проблемы на рынке инженерных систем в России, возможные риски и решения перспективного развития.
03.06.2024, Техническая служба 3data продолжает развивать собственные компетенции в сферах ИБП и охлаждения ЦОД
Техническая команда 3data обладает обширными знаниями и необходимым опытом для обеспечения бесперебойной работы всей сети дата-центров, которая уже насчитывает более 20 ЦОДов. При этом специалисты проходят различные обучающие курсы и тренинги на регулярной основе для совершенствования своих навыков и компетенций.
В рамках обучения по обслуживании ИБП от компании Protect Power Systems специалисты 3data изучили особенности технического обслуживания таких моделей, как PowerNet VX, PowerRack, PowerPro, PowerConcept, PowerMod. Практика была посвящена установке и эксплуатации ИБП, диагностике и устранению неисправностей, пусконаладочным работам по настройке, работа с панелью управления, соблюдению правил безопасности и т.д.
17.06.2024, Инновации на стыке времен: ретрофутуристический дата-центр «П6»
Дата-центр «П6» находится на пересечении двух важнейших транспортных артерий Москвы – Ленинградского проспекта и МКАД. Площадка соответствует международным требования к надежности и безопасности на уровне Tier 3, предлагает все современные сетевые и облачные сервисы.
30.07.2024, Ввели в эксплуатацию вторую очередь дата-центра «П29» на северо-западе Москвы
Сеть дата-центров 3data завершила работы по модернизации дата-центра «П29», расположенного на северо-западе Москвы в районе Митино, и теперь заказчикам стали доступны еще 60 стоек. Помимо увеличения мощности, на объекте расширена зона коворкинга для клиентов, а также увеличена офисная часть объекта, которая готова к сдаче в аренду вместе со складскими помещениями.
 07.08.2024, Компания 3data выражает соболезнования родным и близким Виталия Езопова
07.08.2024, Компания 3data выражает соболезнования родным и близким Виталия Езопова
6 августа 2024 года из жизни ушел Виталий Езопов.
Виталий Викторович являлся одним из владельцев сети дата-центров 3data, на протяжении долгих лет вкладывал много сил в развитие компании и телеком отрасли нашей страны. Он был идейным вдохновителем десятков успешных проектов, настоящим патриотом и профессионалом самого высокого уровня.
Компания 3data выражает соболезнования родным и близким Виталия Езопова. Мы скорбим вместе с вами. Светлая память.
30.08.2024, Бережно сохраняем традицию оригинального оформления дата-центров 3data
Дата-центр «БА81» расположен на пересечении Большой Академической улицы и Северо-восточной хорды рядом со станцией МЦК Лихоборы. Удобное расположение обеспечивает хорошую транспортную и сетевую доступность для организаций северных и западных районов Москвы.
 3data.ru/dc/ba81
13.09.2024, Рассказали о новых проектах 3data и обсудили развитие отрасли на конференции «ЦОД. Москва»
3data.ru/dc/ba81
13.09.2024, Рассказали о новых проектах 3data и обсудили развитие отрасли на конференции «ЦОД. Москва»
На протяжении многих лет компания 3data является одним из главных партнеров ежегодной конференции «ЦОД.Москва», которую организовывает ведущая издательская компания отрасли ИКТ «ИКС-холдинг». Текущий 2024 год не стал исключением.
Уже традиционно в пленарной сессии выступил генеральный директор сети дата-центров 3data Илья Хала, рассказав о проектах компании и строительстве дата-центров. Подчеркнув высокую значимость создания профицита мощностей ЦОД на рынке, он анонсировал ввод в эксплуатацию нового объекта в 2025 году, рассчитанного на 4300 стойко-мест.
«В рамках проекта 3data HyperScale мы начали строительство дата-центра «В10», который расположен в Бирюлево на Востряковском проезде. Общая энергоемкость первого этапа составит 40 МВт с расчетом, что средняя ИТ-нагрузка на стойку будет равна 6 кВт. Но мы готовы предоставлять заказчикам до 20 кВт на стойку. Центр обработки данных будет соответствовать стандартам Uptime Institute Tier III Design + Facility», — анонсировал Илья Хала.
Продолжая выступление, он также рассказал о скором вводе в эксплуатацию классических ЦОДов 3data. В течение года для заказчиков будут доступны дата-центры «Ж8» и «ДМ2», расположенные на Павелецкой и в Домодедово соответственно.
22.10.2024, Эксперты 3data поделились опытом ЦОДостроения на международном форуме Data Center & Cloud Kazakhstan
В октябре сеть дата-центров 3data приняла участие в неделе Data Center & Cloud Kazakhstan, которая состоялась в городе Алматы. Гости мероприятия смогли посетить практические семинары, конференцию, выставку и двухдневный тренинг по тематике построения ЦОДов.
06.11.2024, Провели день открытых дверей в дата-центре «П29» для сотрудников и клиентов 3data
В конце октября мы провели день открытых дверей на площадке «П29». Дата-центр посетили сотрудники компании, действующие клиенты и партнеры. Мероприятие позволило всем гостям взглянуть на один из самых современных и красивых ЦОДов сети 3data.
3data.ru/dc/p29
20.12.2024, Повысили экспертизу в сфере структурированных кабельных систем
Многолетний опыт работы со сложными ИТ-системами позволил технической команде 3data накопить обширные знания в обеспечении бесперебойной работы сети дата-центров. Для поддержания высокого уровня квалификации специалисты регулярно проходят различные тренинги. Одним из последних стал семинар по структурированным кабельным системам от компании DATALAN.
 28.12.2024, 3data в 2024 году
28.12.2024, 3data в 2024 году
Сеть дата-центров 3data в 2024 году развивалась стабильно, в соответствии с намеченными планами. Компания выросла по всем ключевым показателям: привлекла новых клиентов и сохранила текущих, запустила ряд новых объектов и приобрела несколько площадок под будущие дата-центры, активно вводила новые услуги и выполнила планы продаж.
В начале уходящего года была увеличена общая энергоемкость одного из флагманских дата-центров 3data «Э2». Несколько лет ЦОД был полностью законтрактован клиентами, но увеличение подведенной мощности позволило осуществить масштабирование действующих заказчиков, а также предоставило возможность размещения своей инфраструктуры для новых.
Также ввели в эксплуатацию вторую очередь дата-центра «П29». Помимо увеличения мощности, на объекте были расширены зона коворкинга для клиентов и офисная часть, готовящаяся к сдаче в аренду вместе со складскими помещениями. В рамках завершения проекта по модернизации площадки провели традиционный день открытых дверей на «П29», продемонстрировав клиентам и партнерам самый современный ЦОД 3data.
Компания видит свою социальную миссию не только в хранении современной информации, но и в сохранении истории нашей страны. Например, 3data продолжает активно поддерживать московский Музей истории телефона, располагающийся в здании одного из наших ЦОДов. В уходящем году мы презентовали общественности книгу Марата Мурадяна «Отцы русского маркетинга», выступив издателями.
Для поддержания высокого уровня квалификации технические специалисты 3data регулярно проходят различные тренинги. В 2024 году сотрудники получили множество новых знаний по работе с оборудованием дата-центров, тем самым в очередной раз утверждая себя в статусе лучшей технической команды на рынке ЦОД.
В течение года мы сталкивались и с различными сложностями, но нам удалось их преодолеть. Мы благодарим всех наших многочисленных клиентов за оказанное нам доверие, что выражается в росте выручки на 26%, а партнеров за надежное сотрудничество.