Новости 2023 часть2


spacevm.ru
21 December 2023
«ДАКОМ М» запускает серию видеообзоров облачной платформы SpaceVM
Компания «ДАКОМ М» — российский разработчик решений в области виртуализации, рада сообщить о выпуске первого обзорного видео из новой серии, посвященной облачной платформе SpaceVM. Видео предназначено для того, чтобы помочь пользователям лучше понять основные принципы работы и возможности платформы SpaceVM, облегчить переход на эту систему, а также использовать ее потенциал на полную мощность.
В видео освещаются основные разделы и параметры работы с системой: управление локациями, кластерами, серверами, создание и настройка виртуальных машин, работа с хранилищами и сетями, настройки безопасности и др.
Пользователи узнают о преимуществах SpaceVM и о том, какие задачи можно решать с помощью облачной платформы. Кроме того, видео содержит практические примеры использования платформы и рекомендации по ее настройке.
«Мы рады представить нашу новую серию обзорных видео по работе с облачной платформой SpaceVM, — говорит Алексей Мензовитый, директор по продукту SpaceVM, ООО «ДАКОМ М». — Наша цель — помочь пользователям максимально эффективно использовать возможности платформы и упростить переход на нашу систему».
Серия видеобзоров будет постоянно обновляться и расширяться, чтобы охватить все аспекты работы с платформой SpaceVM.
19 December 2023
Компания «ДАКОМ М» приняла участие в конференции Объединенной судостроительной корпорации – «Цифровая трансформация через призму операционной и производственной эффективности»
Целью конференции стала оценка работы корпорации по реализации цифровых проектов. Раскрывая заявленную тему, коммерческий директор ООО «ДАКОМ М» представил доклад – «Построение облачной инфраструктуры корпорации на базе решений Space».
Генеральный директор АО «ОСК» Андрей Пучков подчеркнул на встрече, что предприятиям Группы ОСК необходимо объединить усилия для сотрудничества и партнёрства в сфере развития информационных технологий. Одной из ключевых задач он назвал – создание единого информационного пространства, создание центра обработки данных и корпоративной сети передачи данных.
Построение единого информационного пространства и облачной инфраструктуры в корпорации тесно связаны между собой. Единое информационное пространство обеспечивает эффективную коммуникацию между сотрудниками, а также доступ к необходимым данным и ресурсам. Облачные технологии, в свою очередь, позволяют масштабировать IT-инфраструктуру в соответствии с потребностями компании, снизить затраты предприятия на нее на 15-30% и обеспечить гибкость и адаптивность системы.
15 December 2023
Подтверждена совместимость облачной платформы SpaceVM с серверными решениями и СХД YADRO
На основании результатов проведенного тестирования подтверждена совместимость серверов YADRO VEGMAN R120 G2, YADRO VEGMAN R220 G2, YADRO X2-105, YADRO X2-205, YADRO X3-105, YADRO X3-205, системы хранения данных (СХД) YADRO TATLIN.UNIFIED.SE с облачной платформой SpaceVM.
Совместимость и корректность работы подтверждают двухсторонние сертификаты. Продукты компаний могут использоваться в ИТ решениях в составе единого комплекса.
Облачная платформа SpaceVM входит в состав экосистемы виртуализации Space и предназначена для развёртывания полноценного частного облака в корпоративной среде с необходимыми дополнительными опциями для автоматизации и оркестрации работы облачных сервисов. Все продукты Space являются собственной разработкой ООО «ДАКОМ М» и включены в «Единый реестр российских программ для электронных вычислительных машин и баз данных».
VEGMAN Rx20 G2 – высокопроизводительные серверы, разработанные и произведенные в России, ориентированные на решение корпоративных задач широкого спектра. Улучшенная конструкция, идеально сбалансированная аппаратная платформа, ведущее сервисное предложение в стране и поддержка централизованного средства по управлению, инвентаризации и мониторингу YADRO СУПРИМ.
YADRO TATLIN.UNIFIED.SE — российская система хранения данных корпоративного уровня среднего класса. Создана для данных корпоративных приложений, аналитики и платформ виртуализации, обладает исключительными показателями стоимости владения.
YADRO X серия – серверы общего назначения, имеют оптимальный баланс надёжности, стоимости и производительности для решения большого спектра задач малых и средних предприятий, а также базовых сценариев использования в сфере корпоративного бизнеса.
13 December 2023
Команда «ДАКОМ М» – «Хитрый жук» заняла первое место в отборочных региональных состязаниях WARPOINT TOURNAMENT 2023 и выступила в гранд-финале чемпионата
Уверенная победа игроков «ДАКОМ М» в отборочном туре WARPOINT TOURNAMENT 2023 показала высокую реакцию и слаженную тактическую работу команды, а бескомпромиссная борьба в гранд-финале PVP-шутер-чемпионата стала вызовом для новых достижений на виртуальной арене.
WARPOINT TOURNAMENT 2023 – это командные сражения в виртуальном мире, где все участники видят персонажей друг друга, могут свободно перемещаться и взаимодействовать между собой. По сути – это аналог игры counter-strike, только в формате VR.
В отборочном турнире от компании «ДАКОМ М» приняли участие две команды. Команда «Центнер»: капитан – Дмитрий Смирнов, Дмитрий Яковлев, Руслан Белов, Дарья Лукьянова и команда «Хитрый жук»: капитан – Олег Федосеев, Денис Агеев, Евгений Ус, Кристиан Которобай.
30 November 2023
Облачная платформа SpaceVM подтвердила совместимость с программным модулем MIND Migrate
Компании ООО «ДАКОМ М» — разработчик экосистемы виртуализации Space и MIND Software провели совместные тестовые испытания, в результате которых были подтверждена совместимость облачной платформы SpaceVM и программного модуля MIND Migrate.
27 November 2023
Подтверждена совместимость ПО Kaspersky Hybrid Cloud Security и экосистемы виртуализации Space
Отечественный разработчик экосистемы виртуализации Space — «ДАКОМ М», и лидер рынка кибербезопасности — «Лаборатория Касперского», провели испытания и подтвердили совместимость программных продуктов.
Отказоустойчивость и безопасность данных клиентов, пользующихся платформой SpaceVM — приоритетная задача для «ДАКОМ М», поэтому предпринимаются активные шаги по обеспечению совместимости продуктов экосистемы Space c продуктами ведущих российских разработчиков информационной безопасности.
Сертификат, полученный по итогам испытаний, подтвердил совместимость программных продуктов: Kaspersky Hybrid Cloud Security и ПО облачной платформы SpaceVM 6.2. Таким образом, функционируя на базе SpaceVM, ПО Kaspersky Hybrid Cloud Security обеспечивает безопасность и эффективность процесса цифровой трансформации, а также дает возможность оперировать большими и бизнес-значимыми сущностями, такими как «корпоративный ЦОД» или «корпоративная облачная платформа».
22 November 2023
Вышел новый релиз SpaceVM 6.3
В обновленной версии облачной платформы SpaceVM 6.3 появилась возможность работы с лицензиями специального пакета Space Essentials Plus Kit, расширены доступные инструменты подсистемы микросегментации, получила развитие подсистема управления политиками ИБ, введены дополнительные инструменты по контролю доступа к системе, сделан апгрейд функции высокой доступности к виртуальным машинам в рамках работы с информационными системами, реализована возможность изменения названия блочного устройства (LUN), создана опция назначения 30 и более тегов на сущность, а также оптимизирован графический Web-интерфейс.
Специальный пакет Space Essentials Plus Kit
Решение, оптимальное для небольших первоначальных инвестиций – пакет SpaceVM Essentials Plus Kit содержит лицензии на использование облачной платформы SpaceVM для 3 физических серверов и годовую базовую сервисную поддержку. В течение этого периода пользователю будут доступны обновления программного обеспечения SpaceVM. Эти лицензии – бессрочные и не объединяются с другими лицензиями SpaceVM.
Если ваш бизнес вырос и потребности компании расширились, вы всегда можете приобрести пакет апгрейда, который позволяет перейти на обычную масштабируемую лицензию. Как результат — постоянно доступная, более экономичная и устойчивая ИТ-среда, помогающая быстро реагировать на изменяющиеся потребности предприятия.
Микросегментация сети
В части развития подсистемы микросегментации реализован функционал, позволяющий устанавливать диапазоны портов и IP адресов, что позволяет создавать более гибкие политики фильтрации виртуальных сетей.
Улучшена работа ACL на коммутаторах виртуальной сети в части создания обратных правил для получения ответных пакетов.
Развитие подсистемы управления политиками ИБ и интеграции с SIEM- системами
В SpaceVM 6.3 реализована возможность выгрузки событий в формате CEF во внешние системы такие, как ArcSight, что позволяет дополнительно обеспечить информационную безопасность SpaceVM. Такие системы дают возможность в автоматизированном режиме анализировать регистрируемые события с целью выявления возможных инцидентов ИБ.
Реализована фиксация событий CLI и результат их выполнения на контроллере. События, выполненные в интерфейсе CLI на хостах виртуализации, фиксируются в веб-интерфейсе, с последующей возможностью их передачи во внешние системы мониторинга, например ArcSight.
В рамках работ по повышению безопасности продукта, совершенствованию системы контроля и управления доступом, создана возможность блокировки пользователя по IP-адресу. Функционал позволяет дополнительно защитить систему виртуализации от несанкционированного доступа на уровне блокировки IP адреса. Безопасная сессия дает возможность закрепить связь между токеном, получаемым при входе и IP-адресом, с которого совершен вход. Если токен, связанный с данным IP-адресом, будет использоваться с другого IP-адреса, то пользователь не пройдет авторизацию.
Появилась возможность мониторинга и автоматического перезапуска гостевых ОС в случае их недоступности. Функция позволяет проводить мониторинг активности ОС виртуальной машины по разным признакам. В случае недоступности ОС, при включенной функции будут произведены попытки автоматической перезагрузки ВМ. После нескольких попыток без ответа от ОС будет произведено выключение ВМ. Данная функция позволит пользователю осуществлять высокую доступность к ВМ в автоматизированном режиме, в случае возникновения каких либо технических проблем с ВМ.
Реализована возможность изменения названия блочного устройства (LUN) на усмотрение пользователя. В предыдущих версиях названию блочного устройства автоматически присваивалось значение, получаемое от СХД и равное пути, что не всегда было удобно при работе с несколькими LUN и их идентификации. Теперь, после автоматического добавления, название блочного устройства можно отредактировать на новое удобное/понятное. При этом если заданное пользователем название отличается от пути, то значение пути в списке LUN всегда можно увидеть по всплывающей подсказке.
Расширен функционал работы с тегами, появилась возможность назначения 30 и более тегов на сущность. При большом количестве сущностей функционал позволяет группировать теги на категории и применять к ним различные сценарии, что позволит поддерживать стабильность виртуальной инфраструктуры.
Проведена оптимизация графического Web-интерфейса в части адаптивности и визуализации части параметров.
09 November 2023
Подтверждена работоспособность линейки продуктов виртуализации Space в экосистеме РЕД ОС
Российский разработчик экосистемы виртуализации Space «ДАКОМ М» и отечественный производитель программного обеспечения «РЕД СОФТ» объявили о технологическом сотрудничестве, в рамках которого успешно провели тестирование продуктов на работоспособность. Так, компании подтвердили совместимость платформы для организации инфраструктуры виртуальных рабочих мест Space VDI и облачной платформы SpaceVM с операционной системой РЕД ОС.
04 November 2023
Вышел новый релиз российской VDI-платформы — Space VDI 5.3.0
Российский разработчик программного обеспечения и R&D центр, компания «ДАКОМ М», анонсировала выход Space VDI 5.3.0 — обновленной версии решения для организации виртуальных рабочих столов. Релиз включает в себя: архитектурные улучшения Space Disp; возможность выгрузки событий во внешние системы логирования, в формате CEF, для платформы мониторинга и контроля инцидентов ArcSight; реализацию управления пулом физических машин; оптимизацию подсистем регистрации и безопасности; апгрейд управления парольными политиками; режим стойкости паролей «Усиленный»; разработку — Space Agent PC 1.3, для установки на физический ПК; интеграцию с ADFS и оптимизацию графического Web-интерфейса.
Архитектурные улучшения Space Disp.
Завершен переход к кластерной архитектуре Space Disp. Отключен способ установки Space Disp, как единственного экземпляра, без возможности создания дополнительных экземпляров. Такое решение позволяет двигаться в сторону гибкости использования различных вариантов масштабирования инфраструктуры и предоставляет возможность реализации отказоустойчивой схемы диспетчера.
Реализована возможность выгрузки событий во внешние системы логирования, в формате CEF, для платформы мониторинга и контроля инцидентов ArcSight.
Возможность выгрузки событий во внешние системы, такие как ArcSight, позволят дополнительно обеспечить информационную безопасность Space Disp. Такие системы позволяют в автоматизированном режиме анализировать регистрируемые события с целью выявления потенциальных инцидентов ИБ.
Реализовано управление пулом физических машин.
Функционал предоставляет возможность подключения к группе физических машин и решает задачи управления рабочими столами удаленных машин, работающих вне инфраструктуры виртуализации, под операционной системой Astra Linux.
Оптимизирована подсистема безопасности, путем добавления взаимодействие с технологиями единого входа и двухфакторной аутентификации (SSO, ADFS) в Space Disp и обеспечением безопасности функционала обмена данными в Space Client.
«В рамках релиза проделана сложная комплексная работа по обеспечению безопасности и эффективности функционала Space Disp. Помимо этого, главным отличием релиза от предыдущих является изменение архитектурных особенностей Space Disp, которые направили вектор развития в сторону повышения производительности и предоставлению обновленных вариантов масштабирования инфраструктуры с использованием экосистемы Space VDI. С обновленными схемами масштабирования можно ознакомиться на страницах нашей документации», — сказал Руслан Белов, директор по продукту Space VDI, ООО «Даком М».
Доработано управление парольными политиками, реализован режим стойкости паролей «Усиленный».
Новый функционал обязательной смены временных паролей позволяет усилить конфиденциальность данных, а сложность этих паролей теперь контролируется уровнями стойкости от «слабого уровня» до «усиленного». Помимо этого новые роли пользователей, такие как аудиторы, предоставляют возможность контроля за действиями пользователей и не имеют возможности вносить изменения.
Разработан Space Agent PC 1.3, для установки на физический ПК.
Space Agent PC 1.3 — программный отделяемый модуль, который обеспечивает поддержку проприетарных протоколов доступа и оптимизацию взаимодействия Space Client с физическими машинами.
Осуществлена интеграция с ADFS
ADFS позволяют компаниям управлять своими собственными инфраструктурами идентификации и применять для доступа к приложениям, службам или ресурсам аутентификацию по запросу. Задача ADFS выдавать цифровые удостоверения на основании успешной аутентификации в Active Directory (службы каталогов ОС Windows Server). Эти выданные удостоверения будут является достаточным основанием для успешной аутентификации и авторизации для Space Disp и Space Client.
Оптимизирован графический Web-интерфейс: путем доработки шрифтов и подбором оптимальных цветов под светлую и темную темы, мы улучшили читаемость, разборчивость и адаптивность.
25 October 2023
Подтверждена совместимость оборудования Delta Computers с ПО виртуализации рабочих столов Space VDI
Российский производитель ИТ-оборудования, МПО и ПО Delta Computers и российский разработчик экосистемы виртуализации Space ДАКОМ М объявили об успешном тестировании на производительность и технологическую совместимость серверных продуктов Delta Computers с платформой для организации инфраструктуры виртуальных рабочих мест Space VDI.
Технология виртуализации рабочих столов получила широкое распространение за последние несколько лет благодаря тренду на цифровизацию. Она позволяет сотрудникам продуктивно и безопасно работать в удаленном формате, а бизнесу — обеспечить непрерывность процессов, сократить операционные затраты и упростить ИТ-обслуживание.
С помощью инфраструктуры VDI (Virtual Desktop Infrastructure) образ рабочего стола запускается на виртуальной машине и доставляется клиенту на любое устройство по сети. Виртуальная машина, VM (Virtual Machine), представляет собой комплексную платформу для развертывания полноценного частного облака в корпоративной среде с необходимыми дополнительными инструментами для автоматизации и координации работы облачных сервисов.
17 October 2023
Российские разработчики обсудили, как импортозамещение влияет на отечественный ИТ-рынок
Российский разработчик экосистемы виртуализации Space «ДАКОМ М» принял участие в III ежегодной конференции Softline, посвященной импортозамещению «ИмпортоОпередить!», которая состоялась в Москве 12 октября. Главная повестка мероприятия – новые подходы к обеспечению технологического суверенитета российских организаций.
За последний год, в текущих реалиях, российский ИТ-рынок сумел достаточно быстро перестроиться. Отечественные разработчики информационных систем и производители оборудования расширяют линейку своих решений, включают лучшие практики ведения бизнеса западных вендоров в процессы своих компаний и расширяют партнерскую сеть. За последнее время даже небольшие стартапы заметно выросли и включились в гонку за долю рынка – с каждым месяцем появляется все больше российских инновационных решений. Отечественные производителя стремятся предложить заказчикам выбор в решениях и подходах.
Коммерческий директор компании «ДАКОМ М» Максим Ерофеев поделился планами развития компании, рассказал о новых функциональных возможностях продуктов экосистемы Space, в том числе реализации технологии VDA для безопасного подключения удаленных пользователей к физическим машинам, расположенным в корпоративной локальной сети. Представил разработку компании технологию FreeGRID, которая станет отличным решением для заказчиков, столкнувшихся с санкционными ограничениями при работе с картами Nvidia.
Участники конференции: специалисты Softline и эксперты компаний Space, SL Soft, Базальт СПО, TrueConf, Pantum, Инферит, Р7, Девелоника в формате дискуссий обсудили дальнейшие перспективы развития отечественного ИТ-ландшафта, а также представили разработки новых информационных систем, программных приложений и облачных платформ.
05 October 2023
ДАКОМ М объявляет о запуске специального предложения – SpaceVM Essentials Plus Kit
ООО «ДАКОМ М» представляет специальное предложение — SpaceVM Essentials Plus Kit, позволяющее развернуть современную платформу виртуализации при небольших первоначальных инвестициях
Разработчик экосистемы виртуализации Space ООО «ДАКОМ М» представляет специальное предложение — SpaceVM Essentials Plus Kit, позволяющее развернуть современную платформу виртуализации при небольших первоначальных инвестициях.
Пакет SpaceVM Essentials Plus Kit включает в себя лицензии облачной платформы SpaceVM на 3 физических сервера и сертификат базовой сервисной поддержки на 1 год. В течение заданного периода поддержки пользователю будут доступны все обновления ПО SpaceVM. Лицензии являются бессрочными и не стекируются с другими лицензиями SpaceVM.
Со SpaceVM Essentials Plus Kit любая организация может использовать весь доступный функционал платформы виртуализации класса Enterprise, снизить затраты на оборудование, упростить управление и повысить эффективность работы ИТ- инфраструктуры в целом.
08 September 2023
Обзор SpaceVM 6.2, системы поддержки и защиты виртуальных сред
ООО «ДАКОМ М» — российский разработчик программного обеспечения и исследовательский (R&D) центр, создающий инновационные решения на основе облачных технологий для построения распределённых инфраструктур коммерческих и корпоративных предприятий различных масштабов.
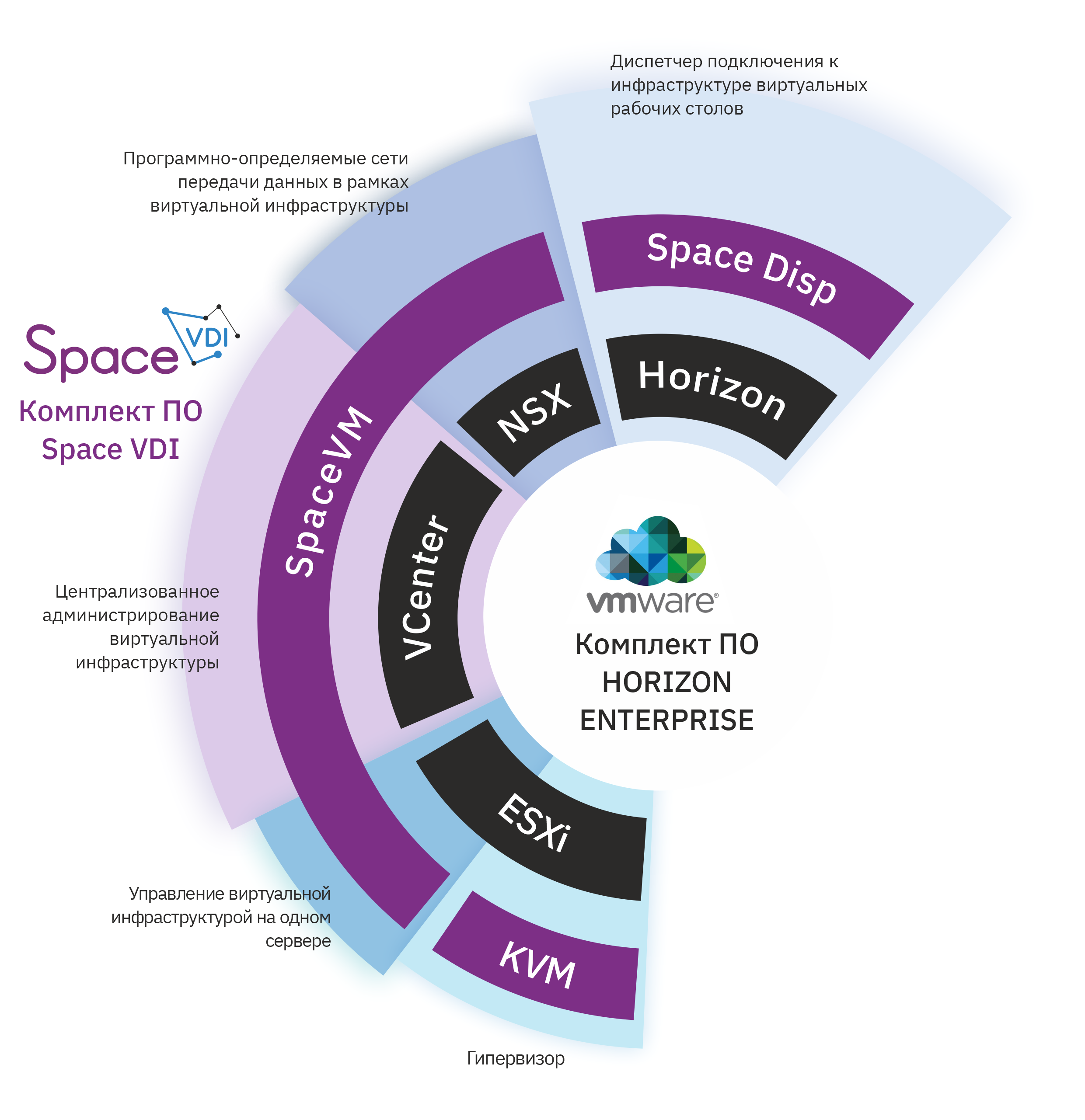
Space — это марка линейки решений, разрабатываемых компанией «ДАКОМ М». Среди них — облачная платформа SpaceVM, предназначенная для развёртывания корпоративных облачных сред и оснащения центров обработки данных, а также Space VDI — решение для организации виртуальных рабочих столов. Есть примеры реализации системы у таких заказчиков, как ОСК, «Якутскэнерго», «Россети Сибири», Росфинмониторинг.
SpaceVM — инструмент серверной виртуализации для эффективного управления ИТ-инфраструктурой. Представляет собой комплексную платформу для развёртывания полноценного частного облака в корпоративной среде с необходимыми дополнительными инструментами для автоматизации и оркестровки работы облачных сервисов. Система работает на базе серверов стандартной архитектуры x86-64 и не только позволяет перенести в облако веб-сайты, порталы и бизнес-приложения, но и обеспечивает работу телекоммуникационных сервисов, виртуальных маршрутизаторов, межсетевых экранов, почтовых и прокси-серверов. SpaceVM — полнофункциональный российский аналог систем серверной виртуализации иностранного производства (VMware и Microsoft).
Рассмотрим систему SpaceVM, её функциональные возможности и задачи, которая она поможет решить, более подробно.
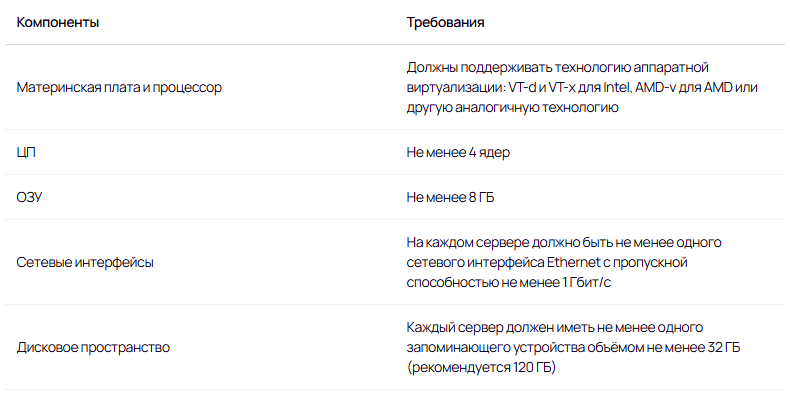
Лицензирование — по количеству физических хостов, не по сокетам. Также в лицензию входит возможность установки консоли управления (аналог VMware vCenter). Лицензии являются бессрочными
Функциональные возможности системы SpaceVM
Отметим основные функциональные возможности системы SpaceVM:
- полноценное развёртывание частного корпоративного облака;
- весь набор для автоматизации и оркестровки виртуальных сервисов;
- позволяет перенести на свою платформу что угодно: веб-сайты, бизнес-приложения, внутренние сервисы;
- обеспечивает развёртывание иной ИТ-инфраструктуры: межсетевых экранов (МСЭ), почтовых и прокси-серверов;
- предоставляет возможность работы с технологией Grid от NVIDIA — высоконагрузочные математические вычисления;
- есть возможность переноса диска при миграции с ESXi на SpaceVM;
- обеспечивает микросегментацию сети.
В продуктовой линейке экосистемы Space присутствует отдельное направление для аппаратных платформ на базе процессора «Эльбрус».
Из уже заложенных в актуальную версию SpaceVM возможностей также необходимо отметить подключение внешних хранилищ данных по NFS, iSCSI и FС, встроенный МСЭ, интеграцию с LDAP и SSO, журналирование событий и встроенную систему резервного копирования. Из стандартных для систем этого класса возможностей присутствуют визуализация нагрузки на виртуальную машину (ВМ), кластеризация (до 96 серверов), живая миграция между узлами кластеров и снимки состояний ВМ (снапшоты).
SpaceVM развивается не только как система виртуализации. Среди прочего в план её совершенствования заложены такие доработки, как интеграция с комплексами управления информацией и событиями (SIEM) MaxPatrol и ArcSight, внедрение политик ИБ и взаимодействие с защитными решениями Kaspersky Light Agent и Kaspersky SVM.
Архитектура и системные требования SpaceVM
SpaceVM предназначена для использования на серверных платформах с архитектурой x86-64.

Сценарии использования SpaceVM
SpaceVM предназначена для решения следующих задач:
Повышение эффективности использования вычислительных ресурсов путём запуска нескольких виртуальных серверов (машин) на одном физическом сервере.
Обеспечение выполнения несовместимых приложений на одном физическом сервере.
Организация общего виртуального пространства с возможностью объединять физические серверы в кластер единого управления.
Повышение доступности и обеспечение непрерывности работы приложений, когда ВМ переносятся на другой сервер кластера без прерывания выполнения пользовательского приложения и самовосстанавливаются на резервных серверах в кластере.
Повышение удобства управления вычислительными ресурсами с помощью централизованного веб-интерфейса с повышенной степенью автоматизации для сокращения времени администрирования и снижения порога вхождения персонала.
Пользователями системы могут быть компании государственного сектора, топливно-энергетического комплекса, промышленности и производства, частные финансовые компании и банки, организации в сфере здравоохранения и образования, научные центры.
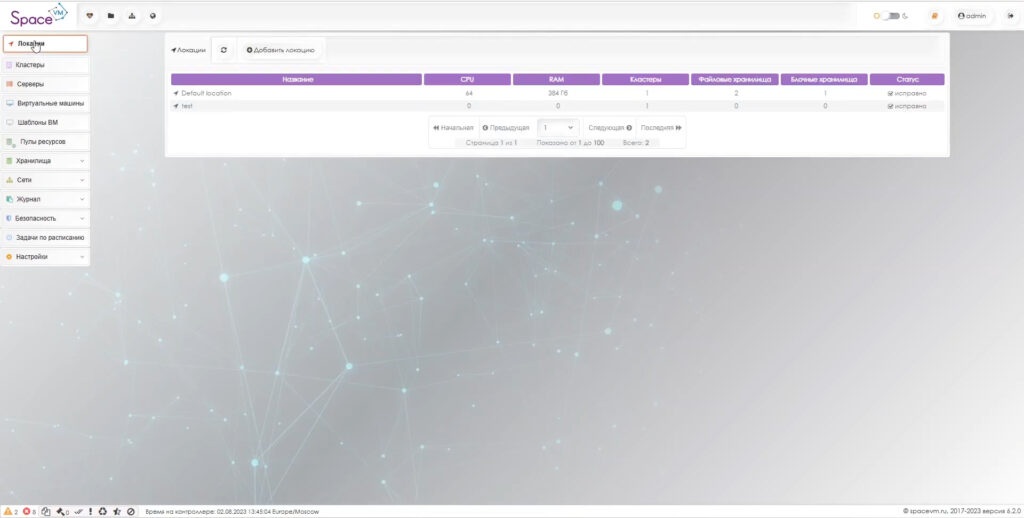
Рассмотрим основные возможности SpaceVM наглядно. Войти в систему можно как с локальной учётной записью, так и с доменной. Главная страница представляет собой окно мониторинга основных метрик гипервизора.

Есть возможность определить локации, куда сразу будут перемещаться все виртуальные машины при их создании, задать выделенные мощности и ресурсы.
По аналогии с VMware в системе SpaceVM используется понятие кластера. Из соответствующего раздела в интерфейсе ведутся распределение ВМ и управление ими, мониторинг их статуса, нагрузки и ресурсов, перенос хостов с кластера на кластер. Здесь возможно управлять такими сущностями, как хранилища ВМ, параметры высокой доступности, пул ресурсов, настройки DRS и пределы ресурсов кластера, а также логированием событий.
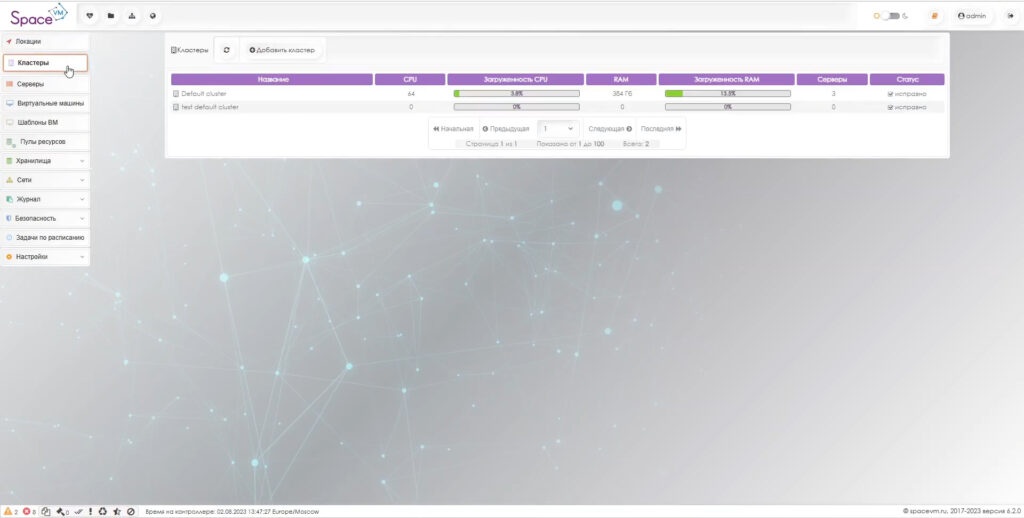
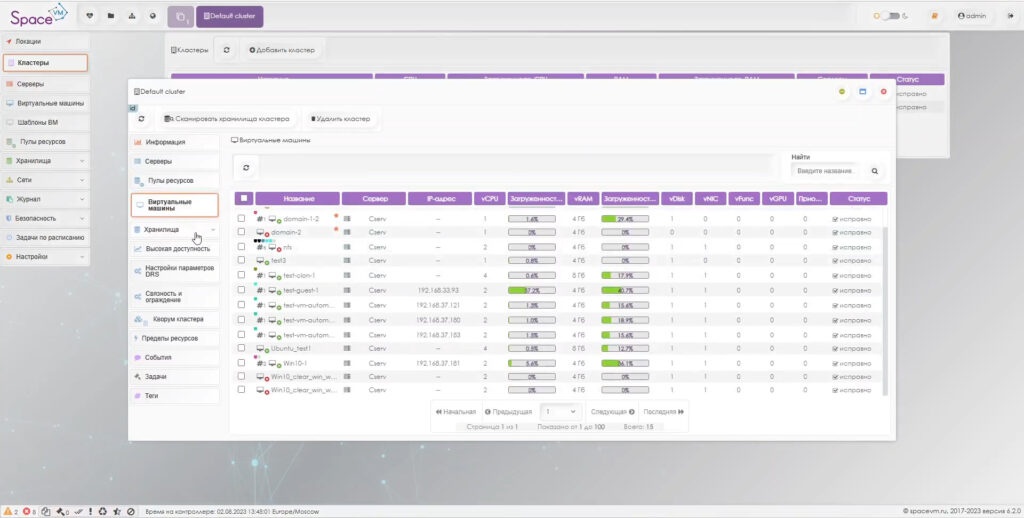
Внутри кластера возможно увидеть список ВМ и далее совершать с ними весь набор стандартных рабочих процедур: изменение ресурсных мощностей, добавление внешних дисков и медиаустройств, создание снапшотов, подключение через консоль гипервизора, применение vGPU для высоконагрузочных вычислений.

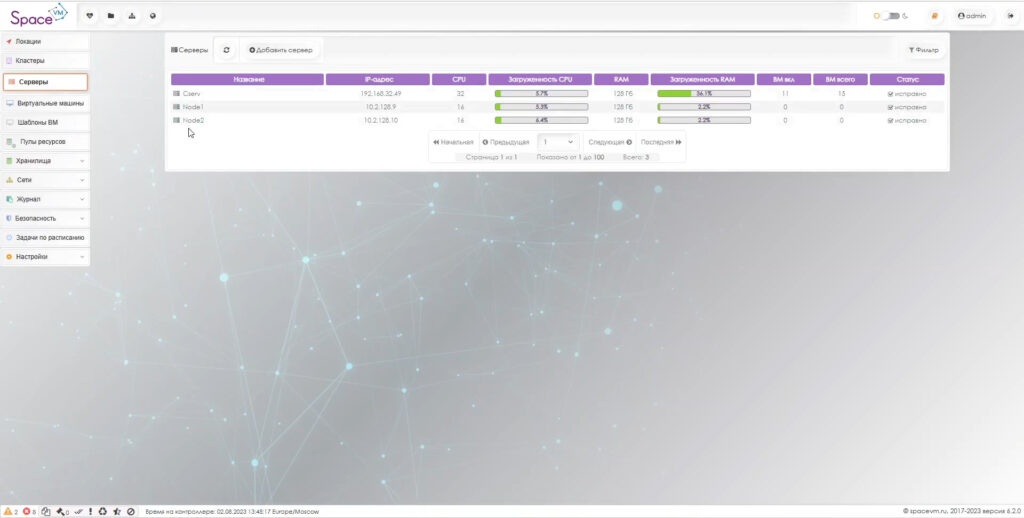
Вкладка «Серверы» открывает меню управления серверными мощностями и нодами гипервизора.
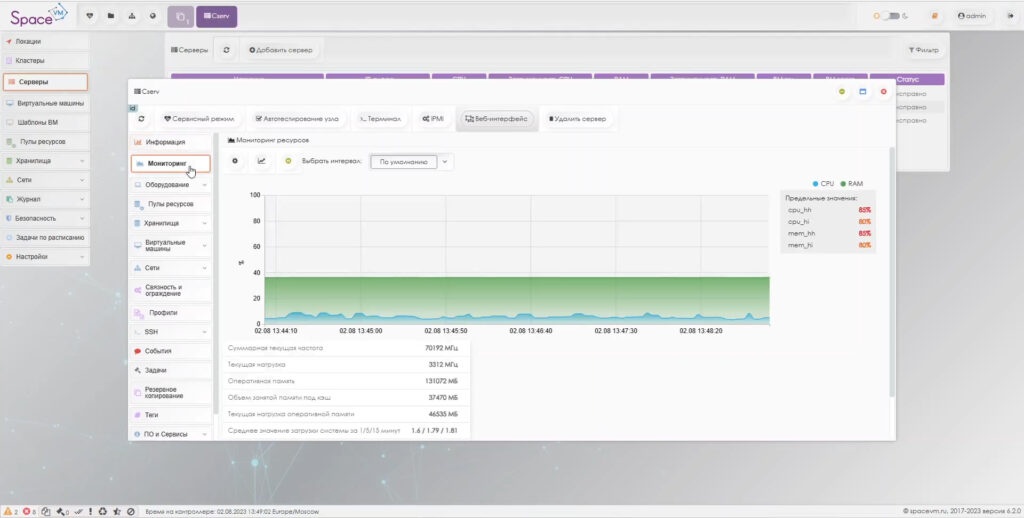
Управление и настройку также возможно осуществлять через стандартный интерфейс командной строки.
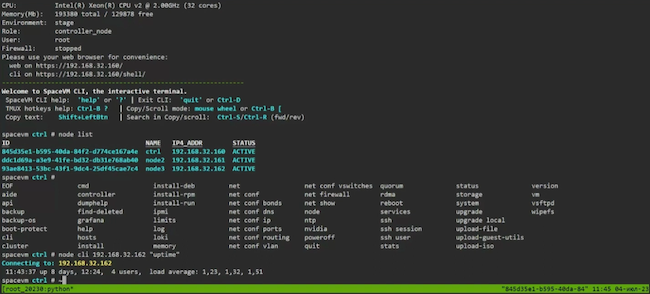
Кроме того, в SpaceVM выделен особый раздел под настройки безопасности, включая управление администраторами и их ролевой моделью в системе, ограничениями по сессиям, ключами шифрования и логированием событий. Среди прочего SpaceVM обеспечивает фильтрацию пакетов сетевого трафика, поступающего из внешней сети, по IP-адресу / порту / имени сетевого интерфейса источника и назначения, а также по протоколу.
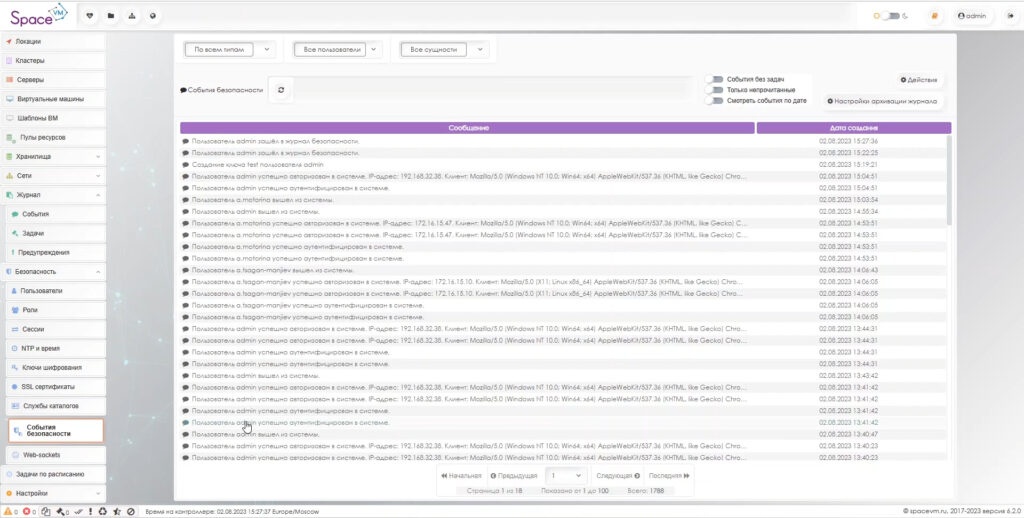
В журнал вносятся записи о следующих событиях:
- авторизация пользователя в интерфейсе управления;
- ошибка аутентификации пользователя;
- изменение состояния физического сервера (доступен, недоступен);
- добавление нового физического сервера;
- удаление физического сервера;
- время создания ВМ;
- запуск ВМ;
- остановка ВМ;
- уничтожение ВМ;
- миграция ВМ;
- создание копии состояния ВМ (снапшота);
- создание резервной копии.
Добавим, что SpaceVM прошла испытания по интеграции и подтвердила совместимость с системой резервного копирования «Кибер Бэкап», благодаря чему появляется возможность обеспечить защиту данных и образов ВМ. Безагентная технология взаимодействия позволяет системе «Кибер Бэкап» производить резервное копирование всех элементов виртуализации на уровне ядра системы и гарантировать быстрое восстановление любых сервисов или данных в случае сбоя.
На декабрь 2023 года запланирован релиз системы для совместимости с vGate — универсальной платформой безопасности облака, которую мы ранее обозревали.
Выводы
SpaceVM — система виртуализации от российского разработчика, которая помогает снизить расходы на ЦОД, повысить время бесперебойной работы систем и приложений, а также значительно упростить работу ИТ-отдела в период импортозамещения.
Облачная платформа SpaceVM — полнофункциональный российский аналог систем серверной виртуализации иностранного производства (VMware, Microsoft). Построение ИТ-инфраструктуры предприятия с использованием SpaceVM позволит обеспечить санкционную устойчивость и технологический суверенитет.
Достоинства:
Включена в реестр отечественного ПО.
Собственная разработка.
Поддержка на базе сервисных центров.
Наличие авторизованных центров обучения.
Совместимость с серверами из реестра Минпромторга (поддерживает работу на базе серверной инфраструктуры от российских производителей Delta Computers и YADRO).
Индивидуализация и доработка по запросам заказчиков.
Лицензируется по количеству хостов (физических серверов), а не сокетов.
Недостатки:
SpaceVM ещё развивается и пока не может на 100 % заменить продукты иностранных производителей систем виртуализации. В то же время большая часть аналогичных функциональных возможностей уже реализована: так, по заявлению разработчика, обеспечено замещение 80 % функций VMware vSphere 7 Enterprise Plus.
05 September 2023
АО «ОСК» и ООО «ДАКОМ М» подписали соглашение о сотрудничестве
Продукты экосистемы виртуализации Space, разрабатываемые ООО «ДАКОМ М» прошли успешное тестирование на инфраструктуре Объединенной судостроительной корпорации
Продукты экосистемы виртуализации Space, разрабатываемые ООО «ДАКОМ М» прошли успешное тестирование на инфраструктуре Объединенной судостроительной корпорации. Специалисты АО «ОСК» высоко оценили уровень функциональных возможностей продуктов и рассматривают их как приоритетный вариант в рамках программы импортозамещения ИТ-инфраструктуры корпорации.
Для реализации цифровых проектов Группы ОСК, среди которых: создание тяжёлой судостроительной САПР и единой платформы ERP всех обществ Группы, важно построение надежной и отказоустойчивой ИТ-инфраструктуры. При этом необходимым условием в обстановке санкций является обеспечение технологического суверенитета по всем ключевым направлениям. Специалисты АО «ОСК» ведут непростую работу по поиску и апробации российских решений, способных эффективно заместить продукты иностранного производства.
01 September 2023
«ДАКОМ М» стал членом АРПП «Отечественный софт»
ООО «ДАКОМ М», разработчик экосистемы виртуализации Space присоединился к Ассоциации разработчиков программных продуктов (АРПП) «Отечественный софт».
Решение о вхождении компании «ДАКОМ М» в ассоциацию было принято 30 августа 2023 г. на заседании правления АРПП. С презентацией о компании и ее ведущих программных продуктах выступил коммерческий директор ООО «ДАКОМ М» Максим Ерофеев.