

В связи с изменениями в Налоговом кодексе РФ в части уплаты НДС компаниями на УСН (176-ФЗ от 12.07.2024) с 1 января 2025 года будут изменены цены на услуги RUVDS. Для 96% виртуальных серверов повышение составит не более 12,6%, а для половины из них – не более 7%. Несмотря на официальную инфляцию свыше 27% за последние три года.
RUVDS делает всё возможное, чтобы сохранить высокие стандарты качества, не перекладывая издержки: компания держала цены неизменными в течение почти тех лет, а на тарифы линейки «Старт» оставались они неизменными с 2017 года.
Изменения для физлиц и юрлиц на УСН
Для физических лиц, пользующихся услугами RUVDS, повышение составит около 12,6%. Для юридических лиц, применяющих упрощенную систему налогообложения (УСН), повышение также составит около 12,6%.
Изменения для юрлиц на ОСНО
Для юридических лиц, находящихся на общей системе налогообложения (ОСНО), повышение в среднем составит 12,6%, из которых 5% будет возможно зачесть в качестве исходящего НДС в расходах.
Повышения не коснутся лицензий Microsoft и панели ispmanager, а также выделенного IP-адреса в базовом тарифе
Как заморозить цены
RUVDS предусмотрел механизм, позволяющий сохранить текущие цены до конца 2025 года. Чтобы заморозить текущие цены, клиенты могут продлить любой сервер по старой цене на любой период. Так, при оплате сервера на год старая цена сохранится до конца следующего года, а при оплате шести месяцев – до истечения этого срока.
Как получить скидку
До 31 декабря при продлении сервера на год действует скидка 30%. Для того, чтобы применить её, необходимо списать средства для продления конкретного сервера с баланса личного кабинета.
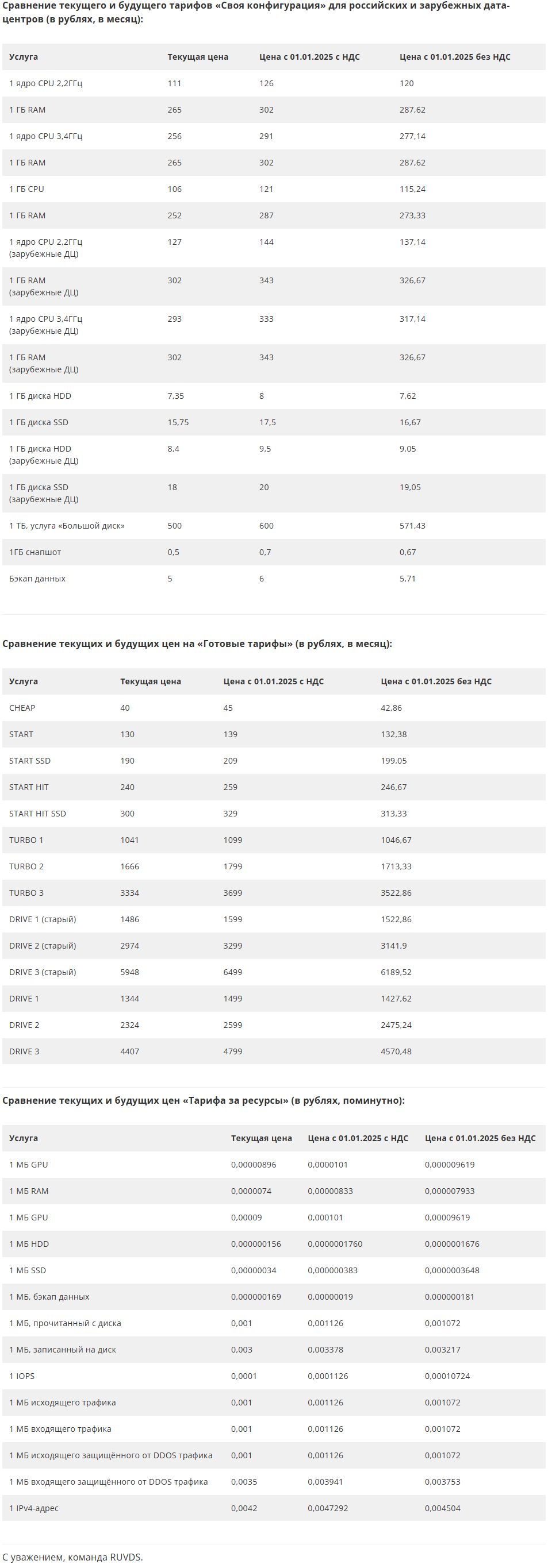
Сравнение текущего и будущего тарифов «Своя конфигурация» для российских и зарубежных дата-центров (в рублях, в месяц):
 ruvds.com
ruvds.com








