Как сэкономить сотни миллионов на электричестве
Электричество можно экономить по-разному, но в основном экономия связана с энергосберегающими устройствами типа светодиодных лампочек, холодильников с высоким классом энергоэффективности или умных розеток с таймерами. Но в этой статье мы расскажем о другом способе — он позволяет снизить платежи за электроэнергию до 30%. Причем новое оборудование покупать не надо, да и режим потребления менять тоже.
Ростелеком на таком способе сэкономил сотни миллионов рублей на электроэнергии. При этом компания не тратилась на энергосберегающее оборудование, сотрудникам не пришлось менять привычки, и ни один клиент не заметил каких-либо изменений в качестве услуг связи. Магия? Нет, просто правильный подход к учету электроэнергии, который мы им помогли внедрить.
В этой статье покажем, как может происходить внедрение проекта в крупной компании и к чему готовиться, если у вас это первый опыт.
Что потребляет электричество в Ростелекоме
Объекты Ростелекома — это не просто офисы с компьютерами. Это целая инфраструктура телекоммуникационной сети с тысячами зданий и сооружений по всей стране:
Автоматические телефонные станции (АТС) — те самые здания, куда приходят все телефонные линии города

Базовые станции — вышки сотовой связи со всем оборудованием

Узлы связи — технические помещения с оборудованием, обеспечивающим работу сети интернет

Контейнеры с оборудованием связи — компактные модули в отдаленных районах

Административные здания с персоналом, обеспечивающие поддержку всей этой инфраструктуры.
Всё это оборудование работает круглосуточно и имеет очень высокие требования к надежности электроснабжения. Если экономия на электричестве негативно скажется на качестве связи, компания экономить не станет. Поэтому было важно снизить затраты и не менять технологических процессов.
У Ростелекома сотни тысяч таких объектов от Калининграда до Владивостока, в каждом регионе страны. Сейчас наша система охватывает 15 тысяч из них — те, на которых уже стоят умные счетчики, умеющие передавать данные удаленно. И в дальнейшем их количество будет расти.
Откуда берётся экономия, если всё продолжает работать?
В отличие от квартиры, где у вас есть тариф день/ночь и всё просто, для бизнеса существует шесть ценовых категорий тарифов на электроэнергию, и в зависимости от характера потребления электроэнергии один и тот же объект может платить по-разному:
Если ваше оборудование работает преимущественно ночью или равномерно в течение суток, то вам будет выгоден один тариф. Если основная нагрузка приходится на дневное время — другой.
Но есть нюанс: в масштабах всей страны Ростелеком работает более чем со 100 энергосбытовыми компаниями, и у каждой свои тарифные ставки в рамках этих шести категорий. То, что выгодно в Москве, может быть убыточно в Хабаровске.
Но тут есть подвох: готовые тарифы энергосбытовые компании в открытом доступе не публикуют. Можно либо ждать счёт и надеяться, что поставщик не ошибется в расчетах, либо самостоятельно собирать тарифные составляющие из разных источников по всей стране. Без автоматизации такую задачу решить невозможно — слишком много данных и слишком часто они меняются.
Выбор правильной ценовой категории для каждого объекта может дать экономию до 30% без изменения режима работы оборудования. Просто потому, что вы будете платить по более выгодному для вас тарифу.
Но чтобы понять, какой тариф выгоднее, нужно сначала собрать статистику потребления электроэнергии по часам. А для этого нужны специальные счётчики и система, которая эти данные собирает и анализирует. Вот тут-то мы и пригодились.
Как было до нас: 10 программ учета, которые не дружили друг с другом
До начала нашего проекта в Ростелекоме было внедрено 10 программ разных производителей. Каждый региональный филиал сам решал, какое программное обеспечение для учета электроэнергии использовать.
Для центрального аппарата компании это была большая головная боль. Это, как если бы в одном офисе одни сотрудники заносили результаты в Excel таблицу, другие работали с 1С, а третьи — записывали информацию в блокнот. Собрать все данные воедино и провести анализ в такой ситуации крайне сложно.
Одной из десяти программ учета была наша, её мы внедрили несколько лет назад. Однако, в отличие от других, мы не просто собирали данные со счетчиков, но и показали значительную экономию от внедрения. В Архангельском филиале она достигла 12 млн рублей в год, в Псковско-Новгородском филиале — около 8-10 млн, а в Карелии — порядка 6-8 млн рублей.
В центральном аппарате компании поняли, что это не очередная программа для сбора данных, а инструмент, который приносит реальную экономию. Вот так перед нами встала задача заменить разрозненные системы одним решением, которое будет собирать данные со всех приборов учета и позволит анализировать потребление в масштабах всей компании по 32 регионам.
Как мы делали единую систему: план и реальность
План был таким:
А в реальности…
Шаг 1: Анализ и подготовка (сентябрь 2023)
Первый этап занял больше года. Это заключение договора. Ростелеком — большая компания с множеством согласований. Нужно было выяснить, какие системы стоят в филиалах, какие счетчики установлены на объектах и как всю эту разнородную инфраструктуру соединить в одну систему.
Самая сложная часть — сбор информации. Мы подключались к системам удаленно и помогали структурировать данные. Ставили копии их программ у себя, копались в базах данных, составляли полные списки оборудования и расшифровывали, как устроены данные в каждой системе.
Это как расследование, только с техническим уклоном. Нам нужно было понять, как работают чужие системы, чтобы потом аккуратно перенести всё в нашу.
Шаг 2: Разворачиваем систему на серверах (октябрь-декабрь 2023)
Тут начались первые сюрпризы. В обычных проектах мы просто заходим на сервер клиента и устанавливаем нашу систему. Но с Ростелекомом всё оказалось сложнее. Из-за повышенных требований по информационной безопасности работа сильно затянулась:
Наш программный пакет проверяли на наличие любых потенциальных уязвимостей. Проверка выявляла все используемые нами компоненты, фреймворки и библиотеки, и если хоть один из них когда-либо имел зарегистрированную уязвимость, нам приходилось либо обновлять этот компонент, либо доказывать, что в нашем случае уязвимость не актуальна. Внесение любого изменения в проект требовало вновь ждать до двух недель на прохождение карантина.
Также нам пришлось доработать интеграцию с Active Directory — службой каталогов Microsoft, которая у клиента используется для авторизации пользователей. Это позволило сотрудникам компании входить в нашу систему с теми же учетными данными, которые они используют для других корпоративных систем.
Шаг 3: Подключение счетчиков (январь-март 2024)
Обычно с переключением счетчиков, по которым уже налажен опрос, сложностей не возникает. Но сюрпризы нас поджидали и тут. Когда мы начали проверять сетевую доступность до счетчиков, выяснилось, что в разных филиалах есть счетчики с устройствами связи, IP-адреса которых совпадают. Такие пересечения возникли в силу того, что разные филиалы настраивают свои локальные сети независимо друг от друга.
Представьте, что у вас есть счетчик в Пскове и счетчик в Петрозаводске, для связи с которыми используется один и тот же IP-адрес 192.168.1.100. Если счетчики находятся в изолированных друг от друга сетях, то проблем не возникает. Мы же все счетчики стали объединять в единую сеть и обнаружили пересечения диапазонов IP-адресов, это приводило к конфликтам.
Казалось бы, есть очевидное решение — сменить сетевые адреса, чтобы они не совпадали, и все заработает без лишних хлопот. Но нет, сетевая инфраструктура нашего клиента формировалась исторически сложным путем. Раньше каждый региональный филиал был фактически отдельной компанией со своими стандартами и правилами настройки сетей. Когда все эти компании объединились под единым национальным брендом, их сетевые инфраструктуры просто «сшили» вместе, сохранив исходную адресацию. За годы в каждой из этих сетей накопилось множество разного оборудования — не только счетчики электроэнергии, но и системы связи, безопасности, управления. И все они были настроены на работу в определенных диапазонах IP-адресов.
Если мы станем менять адреса, то в результате может отвалиться какое-нибудь другое устройство, которое используется совсем для других целей, например, оборудование связи. Проблема усугубилась тем, что в некоторых филиалах никто не мог пояснить, как именно всё настроено — документация неполная, а инженеры, которые всё это создавали, давно сменились.
Поэтому нам пришлось руководствоваться принципом «Работает — не трогай». В архитектуру системы были внесены изменения, и мы развернули отдельные серверы-сборщики для каждой «подсети» Ростелекома. Это как поставить отдельного почтальона в каждом районе, чтобы они не путались, если в разных концах города есть улицы с одинаковыми названиями.
Мы спроектировали распределенную архитектуру, похожую на сеть почтовых отделений. В каждой подсети компании поставили свой сервер-сборщик, который общается только с устройствами в своей «зоне ответственности». Затем все собранные данные передаются на центральный сервер. При этом пользователь видит полную картину в едином интерфейсе — ему не нужно знать про всю эту сложную систему, он просто заходит в единый личный кабинет и получает все данные.

Это более сложная архитектура, чем мы изначально планировали, но она гораздо надежнее и масштабируемее. И самое главное — она решила проблему с пересекающимися IP-адресами.
Шаг 4: Перенос счетчиков и настройка отчетов (июнь-декабрь 2024)
Самый долгий и кропотливый этап. Нужно было перенести информацию обо всех точках измерения и счетчиках из старых систем в новую. И сделать это с учетом жестких требований Ростелекома: сохранить историю потребления за прошлые годы, обеспечить полностью бесшовный переход без потери данных для ежемесячной отчетности и ни в коем случае не прерывать процесс передачи почасовых показаний в энергосбытовые компании, чтобы не нарваться на претензии и штрафы.
Это как заменить двигатель в автомобиле, не останавливаясь в пути.
Процесс был таким:
Последний пункт был особенно сложным. Ведь первого числа каждого месяца филиалы должны были передавать данные о потреблении электроэнергии в энергосбытовые компании.Если мы допустим сбой, то это приведет к нарушению договорных обязательств с поставщиками и может повлечь штрафные санкции до 25% от стоимости электроэнергии.
Поэтому мы разработали план поэтапного перехода:
В процессе работы обнаружили много старых счетчиков и модемов, которые пора было менять. Ростелеком закупил новую технику, а нам пришлось срочно научить нашу систему работать с этими устройствами — буквально получали коробки с новым оборудованием и за месяц добавляли поддержку.
В итоге мы перетащили данные из всех десяти разных систем, удаленно перенастроили часть приборов учета и обеспечили бесшовную передачу данных энергетикам. Никто даже не заметил, как произошла замена двигателя в едущей машине.
Теперь видно все объекты в едином интерфейсе. Центральный аппарат видит всю картину по предприятию, а инженеры филиалов — данные только по своему региону.
Первое, на что инженеры обращают внимание — это общая картина сбора данных. По сути, это диспетчерский экран, где сразу видно состояние всех объектов.
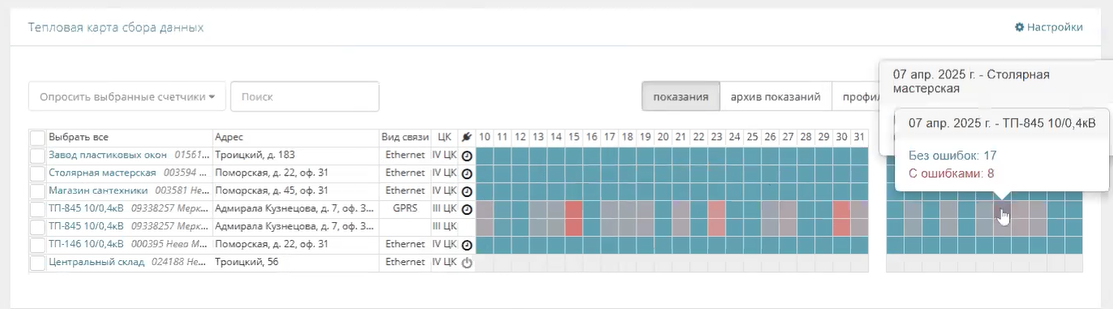
Если где-то появилось красное пятно, значит, счетчик на этом объекте не передает данные, и если не решить проблему, в конце месяца придется ехать снимать показания вручную или платить штрафы за непредоставление информации.
И конечно, все эти усилия по миграции и непрерывному сбору данных были направлены на главную цель — своевременную передачу показаний в энергосбытовые компании.Каждый поставщик электроэнергии требует предоставлять отчеты в строго определенном формате. Раньше это означало кропотливую ручную работу — собрать данные из разрозненных систем, перенести их в нужный формат, проверить, отправить и убедиться, что отчеты были приняты. Сбой на любом этапе приводил к переплатам за электроэнергию из-за штрафов.
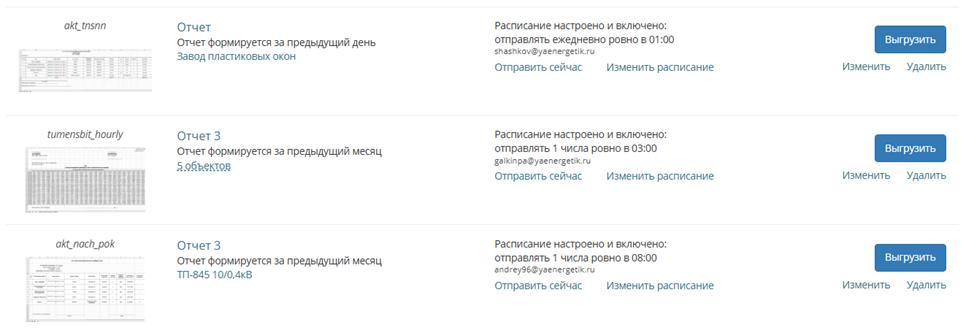
Теперь все эти отчеты формируются и отправляются автоматически. Система учитывает требования каждой энергосбытовой компании, форматы сдачи отчетности у которых могут сильно отличаться:
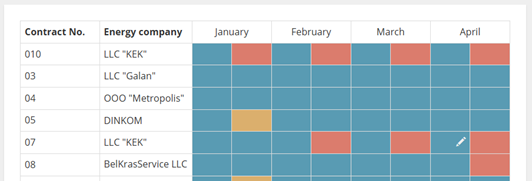
Остается только убедиться, что все отчеты были отправлены и получены поставщиками электроэнергии:
Шаг 5: Обучение пользователей (сентябрь 2024)
Когда система заработала, мы обучили команду Ростелекома ей пользоваться. Собрали более 60 сотрудников со всех филиалов на большой вебинар, а затем провели отдельные тренинги для энергетиков, инженеров и операторов — каждому объяснили его часть работы. Для особо любознательных филиалов проводим дополнительные вебинары с глубоким погружением в возможности системы.
Как теперь экономит Ростелеком
Самый ценный функционал системы — это анализ потребления и расчет оптимальных тарифов. Посмотрим, как это работает на конкретных примерах.
Пример 1: Сравнение тарифов и выбор оптимального
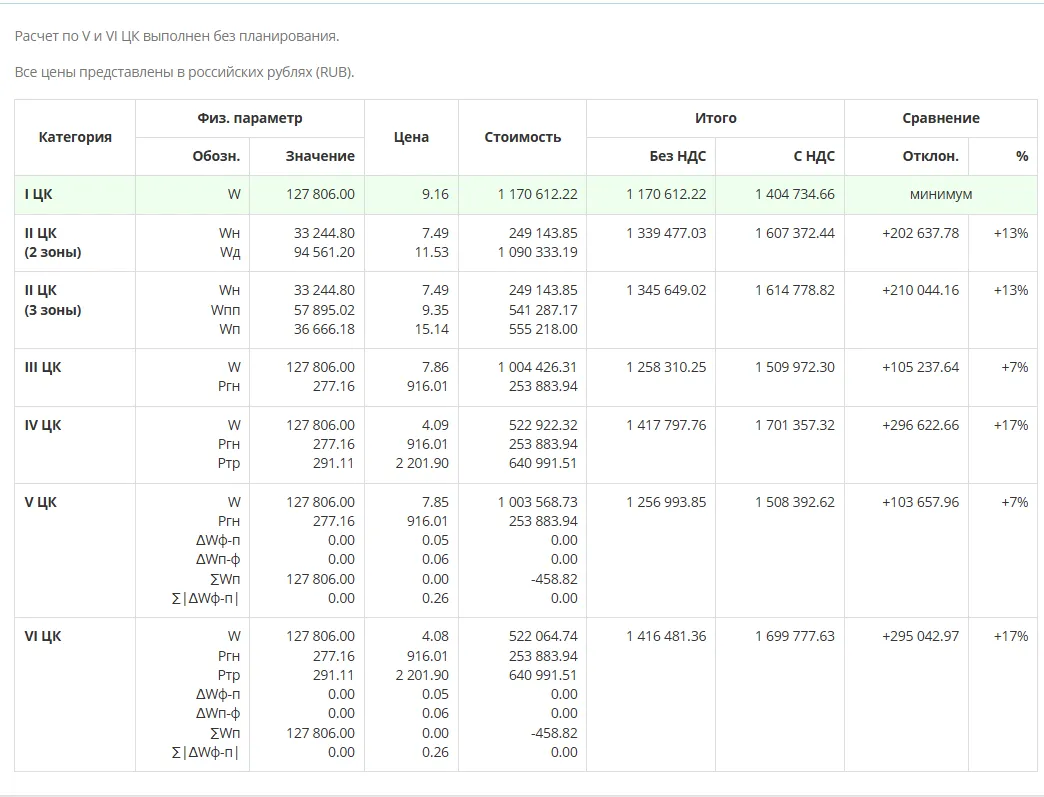
На этом скриншоте показано сравнение стоимости электроэнергии по всем возможным вариантам из тарифного меню одной энергосбытовой компании. Данный поставщик предлагает 5 вариантов расчета за электроэнергию, и система автоматически рассчитывает, сколько будет стоить один и тот же объем потребления (127 806 кВт) по разным тарифам:
Чтобы разобраться с начислениями подробнее, система позволяет выполнить посуточный тарифный анализ и определить дни максимальной экономии и переплаты. Это может помочь подобрать наиболее выгодные режимы работы предприятия.
Пример 2: Расчет экономии при переходе с одного тарифа на другой
Этот пример показывает посуточный анализ затрат при переходе с IV ценовой категории на I ценовую категорию:
В таблице показаны детали расчета:
Графики демонстрируют ежедневную статистику по экономии:
Экономия происходит в дни, когда синие столбцы вверху. Дни, когда есть переплата, показаны красными провалами.
Что в итоге получил Ростелеком?
Теперь вместо 10 разных систем у Ростелекома единая централизованная система учета электроэнергии, которая:
Экономический эффект внедрения системы в некоторых филиалах достигает 30% от первоначальных платежей за электроэнергию. При этом потребление не уменьшилось — наш клиент платит по оптимальным тарифам и за год экономит более 100 млн. руб.
Что особенного в этом проекте?
Для нас этот проект стал вызовом по нескольким причинам:
Масштабируемость решения — теперь наша система может расти практически без ограничений. При увеличении числа объектов достаточно добавить новые серверы-сборщики, что позволяет в перспективе обслуживать намного больше 15 тысяч точек учета без потери производительности.
Но главное — мы помогли крупной компании сэкономить миллионы рублей, не меняя режим работы оборудования и не снижая качество услуг для клиентов.
И сделали это, просто правильно настроив учет электроэнергии и подобрав оптимальные тарифы.
Мораль этой истории
Даже если вы не можете снизить потребление электроэнергии (потому что оборудование должно работать 24/7), вы всё равно можете существенно сэкономить, если правильно выберете тариф и будете контролировать потребление.
Но для этого нужна хорошая система учета, команда экспертов и немного терпения в работе с инфраструктурой крупной компании и бюрократией энергосбытовых организаций.
Что ж, мы своё терпение проверили на практике — и оно не подвело. А наш клиент теперь экономит миллионы. Всем выгодно!
www.cloud.rt.ru
Ростелеком на таком способе сэкономил сотни миллионов рублей на электроэнергии. При этом компания не тратилась на энергосберегающее оборудование, сотрудникам не пришлось менять привычки, и ни один клиент не заметил каких-либо изменений в качестве услуг связи. Магия? Нет, просто правильный подход к учету электроэнергии, который мы им помогли внедрить.
В этой статье покажем, как может происходить внедрение проекта в крупной компании и к чему готовиться, если у вас это первый опыт.
Что потребляет электричество в Ростелекоме
Объекты Ростелекома — это не просто офисы с компьютерами. Это целая инфраструктура телекоммуникационной сети с тысячами зданий и сооружений по всей стране:
Автоматические телефонные станции (АТС) — те самые здания, куда приходят все телефонные линии города
Базовые станции — вышки сотовой связи со всем оборудованием
Узлы связи — технические помещения с оборудованием, обеспечивающим работу сети интернет
Контейнеры с оборудованием связи — компактные модули в отдаленных районах
Административные здания с персоналом, обеспечивающие поддержку всей этой инфраструктуры.
Всё это оборудование работает круглосуточно и имеет очень высокие требования к надежности электроснабжения. Если экономия на электричестве негативно скажется на качестве связи, компания экономить не станет. Поэтому было важно снизить затраты и не менять технологических процессов.
У Ростелекома сотни тысяч таких объектов от Калининграда до Владивостока, в каждом регионе страны. Сейчас наша система охватывает 15 тысяч из них — те, на которых уже стоят умные счетчики, умеющие передавать данные удаленно. И в дальнейшем их количество будет расти.
Откуда берётся экономия, если всё продолжает работать?
В отличие от квартиры, где у вас есть тариф день/ночь и всё просто, для бизнеса существует шесть ценовых категорий тарифов на электроэнергию, и в зависимости от характера потребления электроэнергии один и тот же объект может платить по-разному:
- Простой тариф (Первая ценовая категория): Платите за общее количество киловатт, как в квартире по обычному счётчику
- Многозонный тариф (Вторая ЦК): День дороже, ночь дешевле — как в квартире с двухтарифным счётчиком, только для бизнеса
- Почасовой тариф (Третья ЦК): Каждый час имеет свою цену — утренние и вечерние пиковые часы дороже, ночные — дешевле
- Почасовой тариф с учётом мощности (Четвертая ЦК): То же, что и третья категория, но дополнительно платите за пиковую нагрузку — чем равномернее потребляете, тем выгоднее
- Тариф с планированием (Пятая ЦК): Стоимость электроэнергии также меняется каждый час, но вы должны заранее сообщать план потребления на следующий месяц — если уложитесь в план, тариф может стать выгоднее
- Тариф с планированием и учётом мощности (Шестая ЦК): Как пятая категория, но с дополнительной платой за пиковую нагрузку
Если ваше оборудование работает преимущественно ночью или равномерно в течение суток, то вам будет выгоден один тариф. Если основная нагрузка приходится на дневное время — другой.
Но есть нюанс: в масштабах всей страны Ростелеком работает более чем со 100 энергосбытовыми компаниями, и у каждой свои тарифные ставки в рамках этих шести категорий. То, что выгодно в Москве, может быть убыточно в Хабаровске.
Но тут есть подвох: готовые тарифы энергосбытовые компании в открытом доступе не публикуют. Можно либо ждать счёт и надеяться, что поставщик не ошибется в расчетах, либо самостоятельно собирать тарифные составляющие из разных источников по всей стране. Без автоматизации такую задачу решить невозможно — слишком много данных и слишком часто они меняются.
Выбор правильной ценовой категории для каждого объекта может дать экономию до 30% без изменения режима работы оборудования. Просто потому, что вы будете платить по более выгодному для вас тарифу.
Но чтобы понять, какой тариф выгоднее, нужно сначала собрать статистику потребления электроэнергии по часам. А для этого нужны специальные счётчики и система, которая эти данные собирает и анализирует. Вот тут-то мы и пригодились.
Как было до нас: 10 программ учета, которые не дружили друг с другом
До начала нашего проекта в Ростелекоме было внедрено 10 программ разных производителей. Каждый региональный филиал сам решал, какое программное обеспечение для учета электроэнергии использовать.
Для центрального аппарата компании это была большая головная боль. Это, как если бы в одном офисе одни сотрудники заносили результаты в Excel таблицу, другие работали с 1С, а третьи — записывали информацию в блокнот. Собрать все данные воедино и провести анализ в такой ситуации крайне сложно.
Одной из десяти программ учета была наша, её мы внедрили несколько лет назад. Однако, в отличие от других, мы не просто собирали данные со счетчиков, но и показали значительную экономию от внедрения. В Архангельском филиале она достигла 12 млн рублей в год, в Псковско-Новгородском филиале — около 8-10 млн, а в Карелии — порядка 6-8 млн рублей.
В центральном аппарате компании поняли, что это не очередная программа для сбора данных, а инструмент, который приносит реальную экономию. Вот так перед нами встала задача заменить разрозненные системы одним решением, которое будет собирать данные со всех приборов учета и позволит анализировать потребление в масштабах всей компании по 32 регионам.
Как мы делали единую систему: план и реальность
План был таким:
- Проанализировать текущие системы и понять, что с чем будет интегрироваться
- Развернуть нашу систему на серверах Ростелекома
- Перенести данные из старых систем
- Подключить счетчики к новой системе
- Обучить сотрудников
- Радоваться, как лихо мы управились.
А в реальности…
Шаг 1: Анализ и подготовка (сентябрь 2023)
Первый этап занял больше года. Это заключение договора. Ростелеком — большая компания с множеством согласований. Нужно было выяснить, какие системы стоят в филиалах, какие счетчики установлены на объектах и как всю эту разнородную инфраструктуру соединить в одну систему.
Самая сложная часть — сбор информации. Мы подключались к системам удаленно и помогали структурировать данные. Ставили копии их программ у себя, копались в базах данных, составляли полные списки оборудования и расшифровывали, как устроены данные в каждой системе.
Это как расследование, только с техническим уклоном. Нам нужно было понять, как работают чужие системы, чтобы потом аккуратно перенести всё в нашу.
Шаг 2: Разворачиваем систему на серверах (октябрь-декабрь 2023)
Тут начались первые сюрпризы. В обычных проектах мы просто заходим на сервер клиента и устанавливаем нашу систему. Но с Ростелекомом всё оказалось сложнее. Из-за повышенных требований по информационной безопасности работа сильно затянулась:
- Ограниченный доступ: нам выделили специальный VPN-канал для доступа к инфраструктуре, но прямого доступа к серверам не дали
- Учетные записи: для каждого нашего сотрудника создали отдельную учетную запись с фиксацией, с какого устройства он работает
- Документирование: мы готовили подробную документацию на каждого нашего сотрудника и какие действия он должен выполнять
- «Карантин»: наш установочный пакет проходил проверку службой безопасности в течение двух недель в специальной изолированной среде.
Наш программный пакет проверяли на наличие любых потенциальных уязвимостей. Проверка выявляла все используемые нами компоненты, фреймворки и библиотеки, и если хоть один из них когда-либо имел зарегистрированную уязвимость, нам приходилось либо обновлять этот компонент, либо доказывать, что в нашем случае уязвимость не актуальна. Внесение любого изменения в проект требовало вновь ждать до двух недель на прохождение карантина.
Также нам пришлось доработать интеграцию с Active Directory — службой каталогов Microsoft, которая у клиента используется для авторизации пользователей. Это позволило сотрудникам компании входить в нашу систему с теми же учетными данными, которые они используют для других корпоративных систем.
Шаг 3: Подключение счетчиков (январь-март 2024)
Обычно с переключением счетчиков, по которым уже налажен опрос, сложностей не возникает. Но сюрпризы нас поджидали и тут. Когда мы начали проверять сетевую доступность до счетчиков, выяснилось, что в разных филиалах есть счетчики с устройствами связи, IP-адреса которых совпадают. Такие пересечения возникли в силу того, что разные филиалы настраивают свои локальные сети независимо друг от друга.
Представьте, что у вас есть счетчик в Пскове и счетчик в Петрозаводске, для связи с которыми используется один и тот же IP-адрес 192.168.1.100. Если счетчики находятся в изолированных друг от друга сетях, то проблем не возникает. Мы же все счетчики стали объединять в единую сеть и обнаружили пересечения диапазонов IP-адресов, это приводило к конфликтам.
Казалось бы, есть очевидное решение — сменить сетевые адреса, чтобы они не совпадали, и все заработает без лишних хлопот. Но нет, сетевая инфраструктура нашего клиента формировалась исторически сложным путем. Раньше каждый региональный филиал был фактически отдельной компанией со своими стандартами и правилами настройки сетей. Когда все эти компании объединились под единым национальным брендом, их сетевые инфраструктуры просто «сшили» вместе, сохранив исходную адресацию. За годы в каждой из этих сетей накопилось множество разного оборудования — не только счетчики электроэнергии, но и системы связи, безопасности, управления. И все они были настроены на работу в определенных диапазонах IP-адресов.
Если мы станем менять адреса, то в результате может отвалиться какое-нибудь другое устройство, которое используется совсем для других целей, например, оборудование связи. Проблема усугубилась тем, что в некоторых филиалах никто не мог пояснить, как именно всё настроено — документация неполная, а инженеры, которые всё это создавали, давно сменились.
Поэтому нам пришлось руководствоваться принципом «Работает — не трогай». В архитектуру системы были внесены изменения, и мы развернули отдельные серверы-сборщики для каждой «подсети» Ростелекома. Это как поставить отдельного почтальона в каждом районе, чтобы они не путались, если в разных концах города есть улицы с одинаковыми названиями.
Мы спроектировали распределенную архитектуру, похожую на сеть почтовых отделений. В каждой подсети компании поставили свой сервер-сборщик, который общается только с устройствами в своей «зоне ответственности». Затем все собранные данные передаются на центральный сервер. При этом пользователь видит полную картину в едином интерфейсе — ему не нужно знать про всю эту сложную систему, он просто заходит в единый личный кабинет и получает все данные.
Это более сложная архитектура, чем мы изначально планировали, но она гораздо надежнее и масштабируемее. И самое главное — она решила проблему с пересекающимися IP-адресами.
Шаг 4: Перенос счетчиков и настройка отчетов (июнь-декабрь 2024)
Самый долгий и кропотливый этап. Нужно было перенести информацию обо всех точках измерения и счетчиках из старых систем в новую. И сделать это с учетом жестких требований Ростелекома: сохранить историю потребления за прошлые годы, обеспечить полностью бесшовный переход без потери данных для ежемесячной отчетности и ни в коем случае не прерывать процесс передачи почасовых показаний в энергосбытовые компании, чтобы не нарваться на претензии и штрафы.
Это как заменить двигатель в автомобиле, не останавливаясь в пути.
Процесс был таким:
- Выгружали данные из старой системы
- Дополняли недостающую информацию (часто в старых системах не хватало важных параметров)
- Приводили данные к единому формату
- Загружали в новую систему
- Проверяли корректность загрузки
- Перенастраивали оборудование на передачу данных в новую систему
Последний пункт был особенно сложным. Ведь первого числа каждого месяца филиалы должны были передавать данные о потреблении электроэнергии в энергосбытовые компании.Если мы допустим сбой, то это приведет к нарушению договорных обязательств с поставщиками и может повлечь штрафные санкции до 25% от стоимости электроэнергии.
Поэтому мы разработали план поэтапного перехода:
- Согласовывали с филиалом удобное время для перенастройки
- Подтверждали, что данные за прошлый месяц уже переданы
- Удаленно перенастраивали оборудование на передачу данных в новую систему
- Проверяли корректность сбора данных
- Обучали сотрудников филиала работе с новой системой отчетности
В процессе работы обнаружили много старых счетчиков и модемов, которые пора было менять. Ростелеком закупил новую технику, а нам пришлось срочно научить нашу систему работать с этими устройствами — буквально получали коробки с новым оборудованием и за месяц добавляли поддержку.
В итоге мы перетащили данные из всех десяти разных систем, удаленно перенастроили часть приборов учета и обеспечили бесшовную передачу данных энергетикам. Никто даже не заметил, как произошла замена двигателя в едущей машине.
Теперь видно все объекты в едином интерфейсе. Центральный аппарат видит всю картину по предприятию, а инженеры филиалов — данные только по своему региону.
Первое, на что инженеры обращают внимание — это общая картина сбора данных. По сути, это диспетчерский экран, где сразу видно состояние всех объектов.
Если где-то появилось красное пятно, значит, счетчик на этом объекте не передает данные, и если не решить проблему, в конце месяца придется ехать снимать показания вручную или платить штрафы за непредоставление информации.
И конечно, все эти усилия по миграции и непрерывному сбору данных были направлены на главную цель — своевременную передачу показаний в энергосбытовые компании.Каждый поставщик электроэнергии требует предоставлять отчеты в строго определенном формате. Раньше это означало кропотливую ручную работу — собрать данные из разрозненных систем, перенести их в нужный формат, проверить, отправить и убедиться, что отчеты были приняты. Сбой на любом этапе приводил к переплатам за электроэнергию из-за штрафов.
Теперь все эти отчеты формируются и отправляются автоматически. Система учитывает требования каждой энергосбытовой компании, форматы сдачи отчетности у которых могут сильно отличаться:
Остается только убедиться, что все отчеты были отправлены и получены поставщиками электроэнергии:
Шаг 5: Обучение пользователей (сентябрь 2024)
Когда система заработала, мы обучили команду Ростелекома ей пользоваться. Собрали более 60 сотрудников со всех филиалов на большой вебинар, а затем провели отдельные тренинги для энергетиков, инженеров и операторов — каждому объяснили его часть работы. Для особо любознательных филиалов проводим дополнительные вебинары с глубоким погружением в возможности системы.
Как теперь экономит Ростелеком
Самый ценный функционал системы — это анализ потребления и расчет оптимальных тарифов. Посмотрим, как это работает на конкретных примерах.
Пример 1: Сравнение тарифов и выбор оптимального
На этом скриншоте показано сравнение стоимости электроэнергии по всем возможным вариантам из тарифного меню одной энергосбытовой компании. Данный поставщик предлагает 5 вариантов расчета за электроэнергию, и система автоматически рассчитывает, сколько будет стоить один и тот же объем потребления (127 806 кВт) по разным тарифам:
- Выбрав первый вариант расчетов (I), компания должна оплатить 1,4 млн. руб. — это самый оптимальный вариант.
- Выбрав тарифы, дифферинцированные по зонам суток (2 зоны: день и ночь), за тот же объем компания заплатит 1,6 млн. руб. — дороже на 13%
- Переплата на почасовых тарифах (III и IV ЦК) составит 7% и 17%.
Чтобы разобраться с начислениями подробнее, система позволяет выполнить посуточный тарифный анализ и определить дни максимальной экономии и переплаты. Это может помочь подобрать наиболее выгодные режимы работы предприятия.
Пример 2: Расчет экономии при переходе с одного тарифа на другой
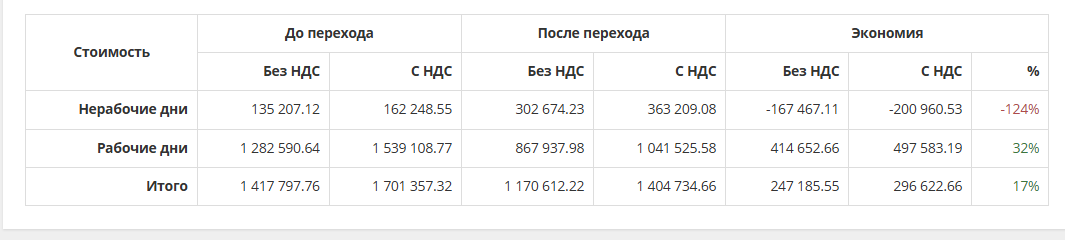
Этот пример показывает посуточный анализ затрат при переходе с IV ценовой категории на I ценовую категорию:
В таблице показаны детали расчета:
- В рабочие дни экономия составляет 0,5 млн руб или 32% в сравнении с текущим тарифом
- В нерабочие дни наблюдается переплата 0,2 млн. руб.
- Общая экономия за месяц: 0,3 млн. руб. или 17%
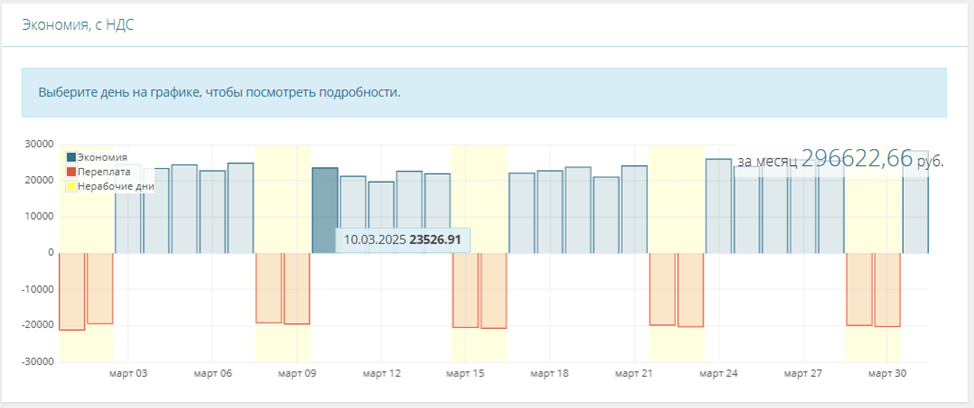
Графики демонстрируют ежедневную статистику по экономии:
Экономия происходит в дни, когда синие столбцы вверху. Дни, когда есть переплата, показаны красными провалами.
Что в итоге получил Ростелеком?
Теперь вместо 10 разных систем у Ростелекома единая централизованная система учета электроэнергии, которая:
- Собирает данные с более чем 15 тысяч счетчиков, раскиданных по 32 регионам страны.
- Отслеживает проблемы передачи данных
- Контролирует качество электроэнергии — напряжение, частоту и другие параметры
- Предупреждает о критических ситуациях, если параметры электросети выходят за допустимые пределы
- Автоматически формирует и рассылает отчеты для энергосбытовых компаний
- Анализирует потребление и показывает, где можно оптимизировать затраты
- Выявляет ошибки в расчетах поставщиков электроэнергии
Экономический эффект внедрения системы в некоторых филиалах достигает 30% от первоначальных платежей за электроэнергию. При этом потребление не уменьшилось — наш клиент платит по оптимальным тарифам и за год экономит более 100 млн. руб.
Что особенного в этом проекте?
Для нас этот проект стал вызовом по нескольким причинам:
- Масштаб — 15 тысяч счетчиков, 32 региона, 10 разных систем
- Требования безопасности — каждое обновление проходило проверку в течение двух недель, и мы старались пройти проверку с первой попытки
- Сетевая инфраструктура — пришлось адаптировать нашу систему под сложную сетевую архитектуру Ростелекома
- Непрерывность сбора данных — нельзя было допустить сбоев в передаче показаний
- Работа с критической инфраструктурой — необходимость интеграции с системами, обеспечивающими безопасность сети
Масштабируемость решения — теперь наша система может расти практически без ограничений. При увеличении числа объектов достаточно добавить новые серверы-сборщики, что позволяет в перспективе обслуживать намного больше 15 тысяч точек учета без потери производительности.
Но главное — мы помогли крупной компании сэкономить миллионы рублей, не меняя режим работы оборудования и не снижая качество услуг для клиентов.
И сделали это, просто правильно настроив учет электроэнергии и подобрав оптимальные тарифы.
Мораль этой истории
Даже если вы не можете снизить потребление электроэнергии (потому что оборудование должно работать 24/7), вы всё равно можете существенно сэкономить, если правильно выберете тариф и будете контролировать потребление.
Но для этого нужна хорошая система учета, команда экспертов и немного терпения в работе с инфраструктурой крупной компании и бюрократией энергосбытовых организаций.
Что ж, мы своё терпение проверили на практике — и оно не подвело. А наш клиент теперь экономит миллионы. Всем выгодно!
www.cloud.rt.ru












