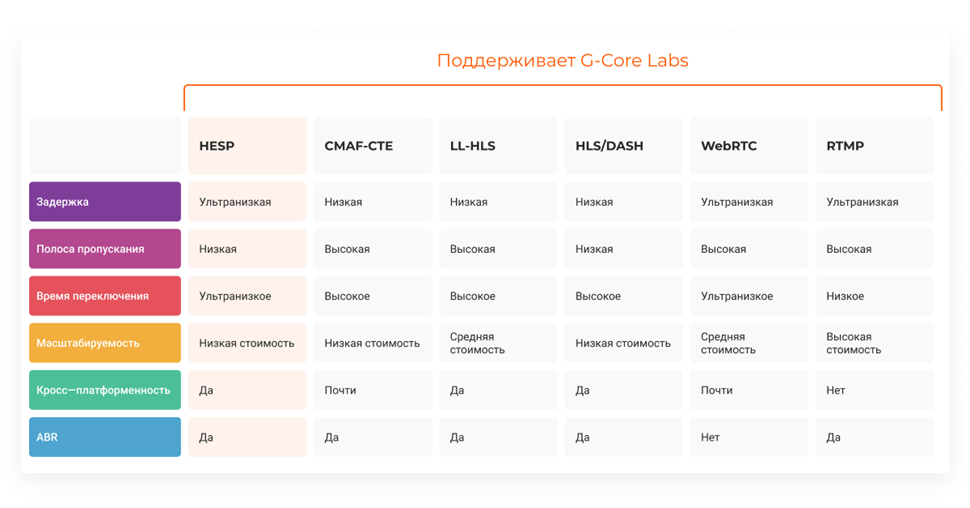
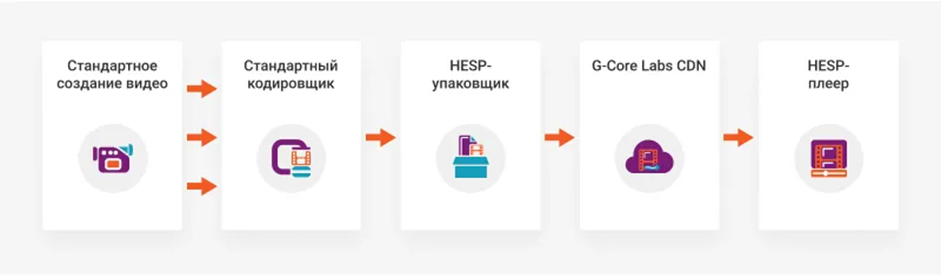
Как выбрать CDN для доставки динамического контента и не облажаться: 8 условий и must-have технологий
Обычно с помощью CDN ускоряют доставку статического контента. Спрашивается, почему бы не использовать сеть и для динамических приложений? Проблема в том, что для этого подходит далеко не каждая CDN. Как выбрать среди них правильную и на какие технологии обращать внимание — в нашем обзоре.
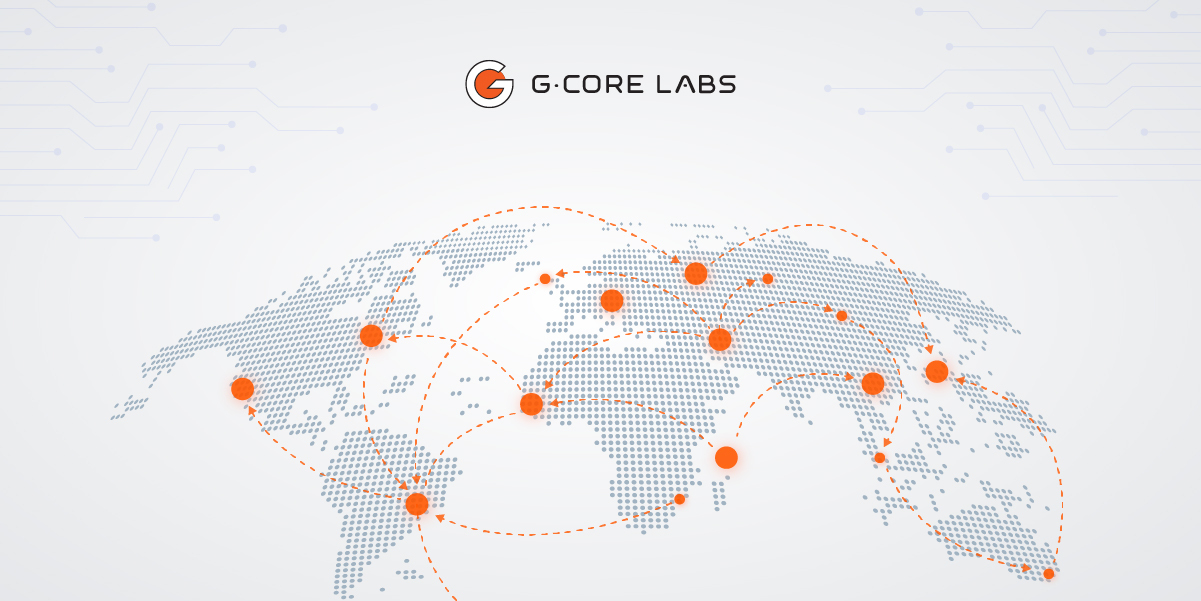
CDN заставляет веб-ресурсы работать быстрее главным образом за счёт кеширования. Со статическим контентом всё просто: он сохраняется на ближайших к пользователям кеш-серверах, и следующие запросы уже не идут к источнику, а забирают информацию с ближайших точек присутствия.
С динамическим контентом всё сложней, так как он уникален для каждого пользователя и его нельзя кешировать. Значит, и ускорить доставку не получится? Получится: если CDN отвечает ряду критериев, то она справится и с ускорением динамики.
1. Отличная связность
Быстрая доставка контента во многом зависит от связности сети. Чем больше у CDN пиринг-партнёров, тем лучше связность и тем более короткий маршрут от источника до пользователя может быть построен. А чем короче маршрут, тем быстрее данные будут доставлены. На это обязательно нужно обращать внимание при выборе сети доставки контента, идёт речь о статике или динамике.
2. Поддержка HTTP/2
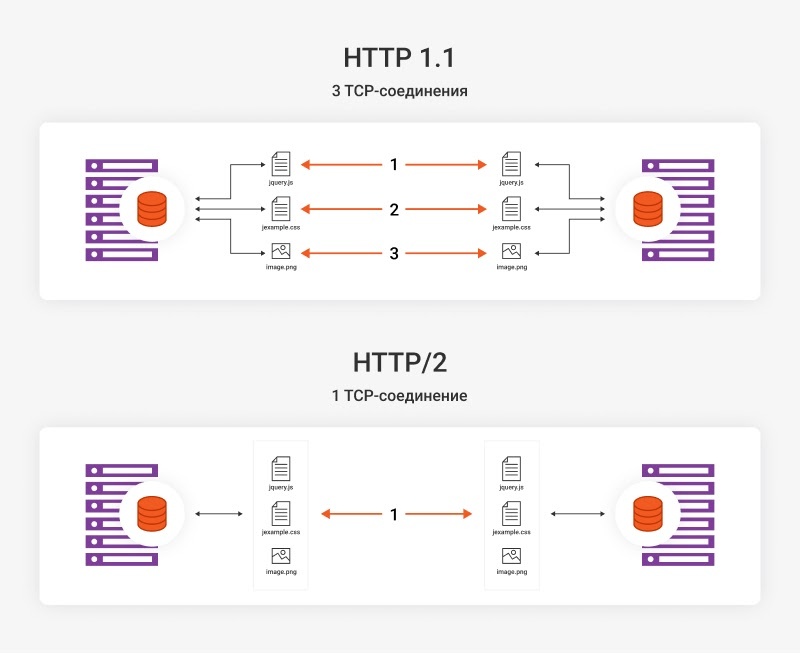
HTTP/2 — это последняя версия протокола HTTP. Использование этой версии во многом помогает ускорить отдачу контента — главным образом за счёт мультиплексирования, то есть передачи нескольких потоков данных по одному каналу.
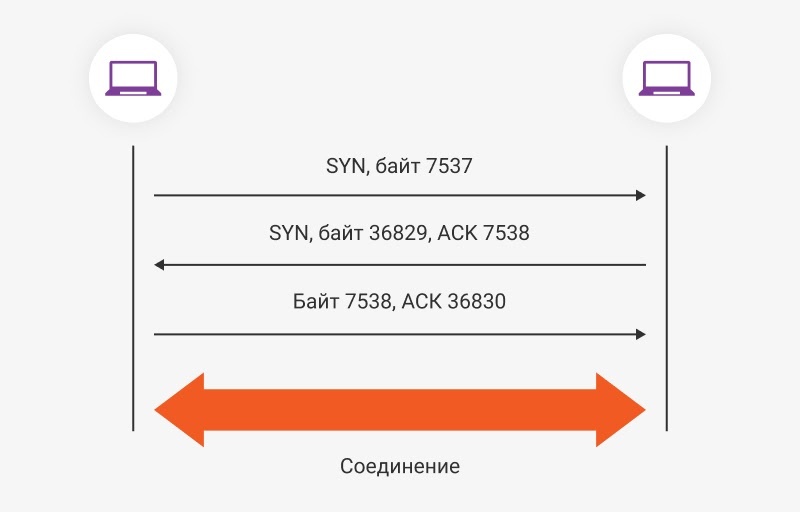
Чтобы отправить информацию, HTTP сначала должен установить TCP-соединение. Для этого требуется «тройное рукопожатие»:
После этих трёх шагов соединение считается установленным.
В предыдущих версиях HTTP для передачи каждого элемента (JаvaScript, CSS, изображений и других данных) открывалось отдельное TCP-соединение. «Тройное рукопожатие» нужно было проводить каждый раз, и это сильно замедляло доставку.
В HTTP/2 для всех этих данных устанавливается единое TCP-соединение. При этом разные типы информации могут отдаваться параллельно. Это значительно экономит время на передачу контента.
HTTP/2 помогает ускорить доставку и по другим причинам:
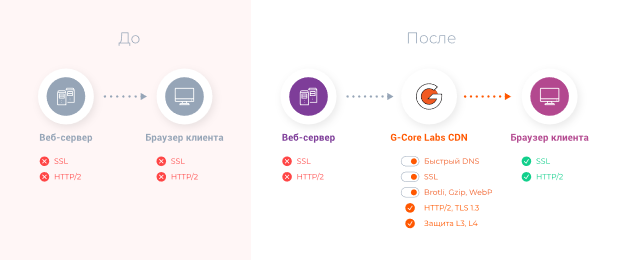
Мы заботимся не только о скорости доставки, но и о безопасности. Поэтому в G-Core Labs CDN есть функция принудительного редиректа на HTTPS. Это значит, что даже если передача по HTTPS не настроена на источнике, вы всё равно можете доставлять контент безопасно. Благодаря использованию HTTP/2 и TLS 1.3 безопасное подключение не будет замедлять отдачу контента, а то есть приложение будет работать быстро и безопасно.
3. Поддержка WebSocket
WebSocket — это независимый протокол на основе TCP. Он даёт возможность обмениваться сообщениями между клиентом и сервером в режиме реального времени.
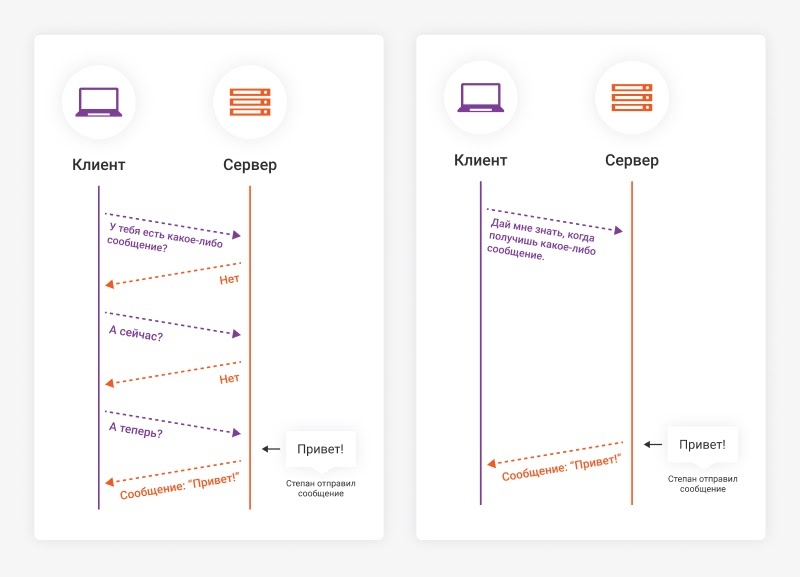
Его принципиальное отличие от HTTP в том, что для получения информации клиенту не нужно каждый раз посылать запрос на сервер.
Возьмём для примера чат. Чтобы клиент узнал, что ему пришло новое сообщение, браузер должен периодически отправлять запросы на сервер и узнавать, нет ли новой информации.
Минусы такого подхода:
WebSocket же устанавливает постоянное соединение. И когда появится новое сообщение, сервер сразу отправит его клиенту.
Это сокращает количество запросов и увеличивает скорость отдачи данных.
Если вы хотите быстро доставлять часто меняющийся динамический контент (сообщения в чатах, push-уведомления и любые другие данные, которые постоянно обновляются на сайте), без WebSocket не обойтись.
4. Использование IPV6
IPv6 — более современная версия протокола IP. Он был разработан главным образом для того, чтобы решить проблему нехватки IP-адресов. Если в IPv4 для создания адреса используется 32-битная система, то в IPv6 — 128-битная.
Адрес IPv6 — это восемь 16-битных блоков, разделённых двоеточием. И общее количество IP-адресов, которые можно создать, составляет 2128 — это более 300 млн адресов на каждого жителя планеты. Такого количества должно хватить каждому устройству.
Но, кроме записи IP-адресов, в обновлённую версию протокола внесли и другие изменения, сделав его более эффективным для передачи информации.
Получается, IPv6 во многом более эффективен, чем IPv4, и передаёт данные быстрее. Чтобы перейти на него, нужно серьёзно модернизировать свою инфраструктуру. Но если вы подключены к нашей CDN, то в этом нет необходимости. Мы используем IPv6 при доставке, даже если ваше оборудование ещё не обновлено до этого протокола. Таким образом, динамический контент доставляется быстро, а вы не тратите ресурсы на апгрейд.
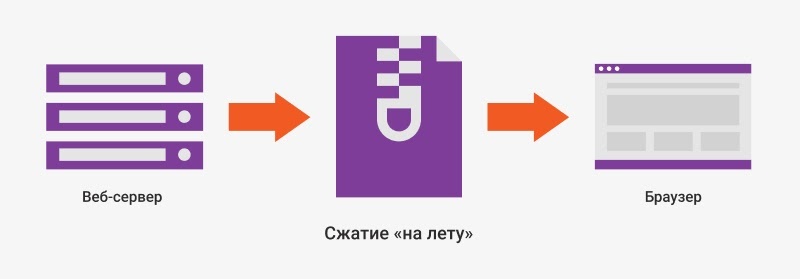
5. Сжатие на лету
Чем меньше весит контент, тем быстрее он будет доставлен пользователям. Но жертвовать важными элементами в угоду размеру — не лучшая идея. Эту проблему решает использование современных алгоритмов сжатия: Gzip, Brotli и WebP.
Главное преимущество этих алгоритмов в том, что они умеют сжимать файлы на лету, то есть прямо в процессе доставки пользователям.
6. Гибкие настройки кеширования
Не весь динамический контент нельзя кешировать. Некоторые данные можно сохранять на короткий срок, и они не потеряют свою актуальность для пользователей. Однако, для этого важно настроить кеширование точно в соответствии с особенностями вашего веб-ресурса. Поэтому выбирать нужно ту CDN, которая позволяет установить любое время кеширования либо отключить его совсем. Не лишней будет и опция очистки кеша — полная или выборочная, для одного файла или для группы.
7. Функции аутентификации на стороне провайдера
Если вам нужно предоставлять ограниченный доступ к контенту, вы можете перенести функции аутентификации на CDN. Это позволит избавить сервер от дополнительной нагрузки, а значит, и увеличить скорость. В нашей CDN для этого доступна опция Secure Token. Она позволяет создавать временные ссылки, которые содержат специальный хеш-ключ, и контент получается загрузить только по запросам, содержащим этот ключ.
Это защищает данные от нежелательных загрузок, помогает исключить нелегальные подключения и копирование. Доступ к ресурсу получают только те, кто имеет на это право, а проверка личности осуществляется с помощью CDN, что избавляет сервер от лишней нагрузки.
8. Облачное объектное хранилище
Контент важно не только эффективно доставлять, но и хранить. Возьмём, например, интернет-магазин. Чтобы отобразить покупателю индивидуальную подборку рекомендуемых товаров, вместе с остальными данными нужно загрузить и фото товаров. Для хранения такого контента требуются большие объёмы памяти. А при запросе клиента нужно быстро извлечь нужные файлы, сформировать ответ и отдать в нужном виде.
Хранение контента — это большая нагрузка и крупные затраты на вычислительные мощности. Поэтому эффективнее будет не размещать файлы на своих серверах, а арендовать облачное объектное хранилище.
В отличие от других типов, в объектных хранилищах нет иерархии — файлы извлекаются напрямую, за счёт чего сокращается время на их отдачу.
Как это относится к CDN? У G-Core Labs есть объектное хранилище, в которое можно поместить данные практически любого объёма, максимально быстро извлекать и доставлять их. Хранилище оптимизировано под работу с динамическими веб-ресурсами. Подключить его можно вместе с CDN и управлять ими через единую панель.
Подведём итоги
G-Core Labs CDN отвечает всем этим критериям, поэтому доставляет динамику так же быстро, как и статику. За производительность сети отвечают технологии Intel: в апреле 2021 мы одними из первых в мире начали интеграцию процессоров Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих сервисов. Убедиться в высокой скорости доставки динамического контента с помощью нашей CDN вы можете бесплатно — для этого у нас предусмотрен бесплатный тариф, а также бесплатный пробный период на любом тарифном плане.
gcorelabs.com/ru/cdn/
CDN заставляет веб-ресурсы работать быстрее главным образом за счёт кеширования. Со статическим контентом всё просто: он сохраняется на ближайших к пользователям кеш-серверах, и следующие запросы уже не идут к источнику, а забирают информацию с ближайших точек присутствия.
С динамическим контентом всё сложней, так как он уникален для каждого пользователя и его нельзя кешировать. Значит, и ускорить доставку не получится? Получится: если CDN отвечает ряду критериев, то она справится и с ускорением динамики.
1. Отличная связность
Быстрая доставка контента во многом зависит от связности сети. Чем больше у CDN пиринг-партнёров, тем лучше связность и тем более короткий маршрут от источника до пользователя может быть построен. А чем короче маршрут, тем быстрее данные будут доставлены. На это обязательно нужно обращать внимание при выборе сети доставки контента, идёт речь о статике или динамике.
2. Поддержка HTTP/2
HTTP/2 — это последняя версия протокола HTTP. Использование этой версии во многом помогает ускорить отдачу контента — главным образом за счёт мультиплексирования, то есть передачи нескольких потоков данных по одному каналу.
Чтобы отправить информацию, HTTP сначала должен установить TCP-соединение. Для этого требуется «тройное рукопожатие»:
- Отправитель посылает запрос на установку соединения — сообщение SYN и порядковый номер переданного байта.
- Получатель в ответ посылает сообщение SYN, подтверждает получение данных сообщением ACK и отправляет номер байта, который должен быть получен следующим.
- Отправитель тоже подтверждает, что получил информацию, и посылает номер следующего ожидаемого байта.
После этих трёх шагов соединение считается установленным.
В предыдущих версиях HTTP для передачи каждого элемента (JаvaScript, CSS, изображений и других данных) открывалось отдельное TCP-соединение. «Тройное рукопожатие» нужно было проводить каждый раз, и это сильно замедляло доставку.
В HTTP/2 для всех этих данных устанавливается единое TCP-соединение. При этом разные типы информации могут отдаваться параллельно. Это значительно экономит время на передачу контента.
HTTP/2 помогает ускорить доставку и по другим причинам:
- Это бинарный протокол. Использование бинарного формата вместо текстового значительно облегчает выполнение команд. В таких протоколах меньше ошибок, меньше нагрузка на сеть и, как следствие, меньше задержек.
- Умеет сжимать заголовки. Заголовок — это тоже данные. А чем больше данных передаётся, тем медленнее они доходят до пользователя. HTTP/2 сжимает заголовки по алгоритму Хаффмана и опускает повторяющиеся.
- Доступна приоритезация запросов. Определённую информацию можно назначить приоритетной — тогда она будут отдаваться в самом начале и загружаться быстрее. В первом приоритете можно отдавать самые важные элементы страницы, которые должны отобразиться у пользователя в первую очередь.
- Есть функция Server Push. Она позволяет предугадывать, какие данные понадобятся клиенту, и отправлять их ещё до того, как поступил запрос. Это ускоряет загрузку, снижает количество запросов, а значит, уменьшает нагрузку на источник.
Мы заботимся не только о скорости доставки, но и о безопасности. Поэтому в G-Core Labs CDN есть функция принудительного редиректа на HTTPS. Это значит, что даже если передача по HTTPS не настроена на источнике, вы всё равно можете доставлять контент безопасно. Благодаря использованию HTTP/2 и TLS 1.3 безопасное подключение не будет замедлять отдачу контента, а то есть приложение будет работать быстро и безопасно.
3. Поддержка WebSocket
WebSocket — это независимый протокол на основе TCP. Он даёт возможность обмениваться сообщениями между клиентом и сервером в режиме реального времени.
Его принципиальное отличие от HTTP в том, что для получения информации клиенту не нужно каждый раз посылать запрос на сервер.
Возьмём для примера чат. Чтобы клиент узнал, что ему пришло новое сообщение, браузер должен периодически отправлять запросы на сервер и узнавать, нет ли новой информации.
Минусы такого подхода:
- Увеличивается количество запросов к серверу. Из-за этого растёт нагрузка и падает скорость обработки запросов.
- Данные обновляются медленнее. Так как браузер посылает запросы с определённой периодичностью, передать новое сообщение клиенту он может не сразу. Это создаёт задержки при доставке контента.
WebSocket же устанавливает постоянное соединение. И когда появится новое сообщение, сервер сразу отправит его клиенту.
Это сокращает количество запросов и увеличивает скорость отдачи данных.
Если вы хотите быстро доставлять часто меняющийся динамический контент (сообщения в чатах, push-уведомления и любые другие данные, которые постоянно обновляются на сайте), без WebSocket не обойтись.
4. Использование IPV6
IPv6 — более современная версия протокола IP. Он был разработан главным образом для того, чтобы решить проблему нехватки IP-адресов. Если в IPv4 для создания адреса используется 32-битная система, то в IPv6 — 128-битная.
Адрес IPv6 — это восемь 16-битных блоков, разделённых двоеточием. И общее количество IP-адресов, которые можно создать, составляет 2128 — это более 300 млн адресов на каждого жителя планеты. Такого количества должно хватить каждому устройству.
Но, кроме записи IP-адресов, в обновлённую версию протокола внесли и другие изменения, сделав его более эффективным для передачи информации.
- Меньшая нагрузка на сетевое оборудование. Эта версия протокола не использует NAT — технологию для преобразования приватных адресов в публичные.
- NAT был нужен в IPv4, так как там существовала проблема нехватки адресов. Внутри локальной сети у каждого устройства был приватный IP-адрес, который использовался для локальной передачи данных, например между устройствами внутри одной компании. Но для взаимодействия с другими ресурсами через глобальный интернет нужен был публичный, общедоступный адрес.
- NAT преобразовывал приватный адрес в публичный — этот процесс называется трансляцией. При этом нужно было не только преобразовывать адреса, но и хранить информацию об установленных соединениях. Это увеличивало нагрузку на оборудование, и во время пиковых скачков трафика скорость падала. В IPv6 нет необходимости в трансляции, не нужно хранить информацию о соединениях, а значит, нагрузка на оборудование меньше и скорость остаётся стабильной.
- Более простые заголовки пакетов. В новой версии из них убрали несущественные элементы. Это упростило обработку, снизило нагрузку на маршрутизаторы и в целом сократило объём передаваемых данных.
- Более быстрая маршрутизация. Структура адреса IPv6 устроена так, что маршрутизаторы на каждом уровне сети (крупные провайдеры, подсети, сети организаций) обрабатывают не весь адрес, а его часть. Это уменьшает размер таблицы маршрутизации, а значит, сокращает время на обработку.
- Определяет чувствительные к задержкам пакеты и передаёт их в первую очередь. Такую возможность даёт функция QoS (Quality of Service). Это специальная технология, которая умеет определять тип трафика и приоритизировать его на основании этого.
Получается, IPv6 во многом более эффективен, чем IPv4, и передаёт данные быстрее. Чтобы перейти на него, нужно серьёзно модернизировать свою инфраструктуру. Но если вы подключены к нашей CDN, то в этом нет необходимости. Мы используем IPv6 при доставке, даже если ваше оборудование ещё не обновлено до этого протокола. Таким образом, динамический контент доставляется быстро, а вы не тратите ресурсы на апгрейд.
5. Сжатие на лету
Чем меньше весит контент, тем быстрее он будет доставлен пользователям. Но жертвовать важными элементами в угоду размеру — не лучшая идея. Эту проблему решает использование современных алгоритмов сжатия: Gzip, Brotli и WebP.
- Gzip предназначен для сжатия текстового контента. Он находит в файлах одинаковые строки и объединяет их. За счёт этого размер данных уменьшается на 60–70%.
- Brotli уменьшает размер любого контента. Для сжатия он использует уже встроенный в браузеры пользователей словарь из более чем 100 000 самых часто встречающихся в интернете элементов. Алгоритм находит эти элементы в передаваемых данных, вычисляет уникальные фрагменты и передаёт только их, а неуникальные добавляет из словаря. Brotli на 20–25% эффективнее Gzip.
- WebP — новый алгоритм для сжатия изображений. Он на 26% лучше PNG сжимает изображения без потерь и на 25–34% эффективнее JPG при сжатии изображений с потерями.
Главное преимущество этих алгоритмов в том, что они умеют сжимать файлы на лету, то есть прямо в процессе доставки пользователям.
6. Гибкие настройки кеширования
Не весь динамический контент нельзя кешировать. Некоторые данные можно сохранять на короткий срок, и они не потеряют свою актуальность для пользователей. Однако, для этого важно настроить кеширование точно в соответствии с особенностями вашего веб-ресурса. Поэтому выбирать нужно ту CDN, которая позволяет установить любое время кеширования либо отключить его совсем. Не лишней будет и опция очистки кеша — полная или выборочная, для одного файла или для группы.
7. Функции аутентификации на стороне провайдера
Если вам нужно предоставлять ограниченный доступ к контенту, вы можете перенести функции аутентификации на CDN. Это позволит избавить сервер от дополнительной нагрузки, а значит, и увеличить скорость. В нашей CDN для этого доступна опция Secure Token. Она позволяет создавать временные ссылки, которые содержат специальный хеш-ключ, и контент получается загрузить только по запросам, содержащим этот ключ.
Это защищает данные от нежелательных загрузок, помогает исключить нелегальные подключения и копирование. Доступ к ресурсу получают только те, кто имеет на это право, а проверка личности осуществляется с помощью CDN, что избавляет сервер от лишней нагрузки.
8. Облачное объектное хранилище
Контент важно не только эффективно доставлять, но и хранить. Возьмём, например, интернет-магазин. Чтобы отобразить покупателю индивидуальную подборку рекомендуемых товаров, вместе с остальными данными нужно загрузить и фото товаров. Для хранения такого контента требуются большие объёмы памяти. А при запросе клиента нужно быстро извлечь нужные файлы, сформировать ответ и отдать в нужном виде.
Хранение контента — это большая нагрузка и крупные затраты на вычислительные мощности. Поэтому эффективнее будет не размещать файлы на своих серверах, а арендовать облачное объектное хранилище.
В отличие от других типов, в объектных хранилищах нет иерархии — файлы извлекаются напрямую, за счёт чего сокращается время на их отдачу.
Как это относится к CDN? У G-Core Labs есть объектное хранилище, в которое можно поместить данные практически любого объёма, максимально быстро извлекать и доставлять их. Хранилище оптимизировано под работу с динамическими веб-ресурсами. Подключить его можно вместе с CDN и управлять ими через единую панель.
Подведём итоги
- Есть мнение, что CDN может ускорить доставку только статического контента и плохо работает с динамикой. Но на самом деле, если сеть поддерживает определённые функции, она отлично справится и с ускорением динамики.
- Чтобы CDN могла построить лучший маршрут для доставки данных, у неё должно быть отличная связность. У G-Core Labs CDN больше 6 000 пиринг-партнёров, поэтому она позволяет передавать данные максимально быстро.
- CDN должна поддерживать HTTP/2, так как он намного эффективнее предыдущих версий HTTP. Его главный плюс в том, что для передачи любых типов файлов он устанавливает только одно TCP-соединение.
- В CDN должна быть поддержка WebSocket — этот протокол для передачи данных в реальном времени упрощает доставку часто меняющегося динамического контента, поэтому без него не обойтись.
- Чтобы быстрее доставлять контент, CDN важно поддерживать протокол IPv6. Желательно, чтобы сеть позволяла использовать эту версию протокола, даже если её ещё не поддерживает оборудование пользователя.
- Важно, чтобы провайдер умел сжимать контент на лету прямо на стороне CDN, в процессе доставки с помощью алгоритмов Brotli, Gzip и WebP.
- У CDN должны быть гибкие настройки кеширования. Желательно, чтобы провайдер мог взять функции аутентификации пользователей на себя, чтобы снизить нагрузку на ваши ресурсы.
- Вместе с CDN можно подключить объектное хранилище, чтобы эффективно доставлять и хранить данные.
G-Core Labs CDN отвечает всем этим критериям, поэтому доставляет динамику так же быстро, как и статику. За производительность сети отвечают технологии Intel: в апреле 2021 мы одними из первых в мире начали интеграцию процессоров Intel Xeon Scalable 3-го поколения (Ice Lake) в серверную инфраструктуру своих сервисов. Убедиться в высокой скорости доставки динамического контента с помощью нашей CDN вы можете бесплатно — для этого у нас предусмотрен бесплатный тариф, а также бесплатный пробный период на любом тарифном плане.
gcorelabs.com/ru/cdn/